Évaluation de la qualité des données (EQD)
Contexte et objectif
Section intitulée « Contexte et objectif »Objectif du module
Section intitulée « Objectif du module »Le module d’évaluation de la qualité des données (EQD) évalue la fiabilité des données de routine du système d’information sur la gestion de la santé (SIGS) communiquées par les établissements de santé. Il s’agit d’une étape initiale de contrôle de la qualité dans le pipeline FASTR, qui examine les rapports mensuels des établissements afin d’identifier les problèmes de qualité des données avant qu’elles ne soient utilisées dans l’analyse en aval.
Le module évalue la qualité des données selon trois dimensions complémentaires : les valeurs aberrantes, qui identifient les valeurs rapportées anormalement élevées pouvant refléter des erreurs de rapport ou de saisie des données ; l’exhaustivité, qui mesure la régularité et la continuité des rapports des établissements dans le temps ; et la cohérence, qui évalue si les indicateurs connexes présentent les relations attendues. Ces dimensions sont combinées en une note globale de l’EQD, qui fournit une mesure synthétique standardisée de la fiabilité des données.
Les données de routine du SIGS constituent une source essentielle pour le suivi de la prestation des services de santé, tant au niveau des établissements que de la population, car elles permettent de saisir des événements tels que les vaccinations effectuées et les accouchements assistés par du personnel de santé qualifié. Comme toutes les données collectées en routine, les données SIGS sont sujettes à des limitations de qualité. Le module EQD du FASTR applique un examen systématique des données mensuelles au niveau des établissements et des indicateurs afin d’identifier et de caractériser ces limites. Les résultats sont résumés sous forme d’estimations annuelles, qui peuvent refléter des données partielles en fonction de la disponibilité des données au moment de l’analyse (par exemple, les analyses effectuées en milieu d’année peuvent inclure des données uniquement pour les mois disponibles).
Raison d’être de l’analyse
Section intitulée « Raison d’être de l’analyse »La qualité des données influe directement sur la fiabilité des indicateurs de santé et des estimations de la couverture. Avant de calculer les taux d’utilisation des services ou la couverture de la population, il est nécessaire de déterminer si les données sous-jacentes sur les établissements sont suffisamment fiables. Ce module identifie les schémas de données susceptibles de fausser les résultats analytiques, ce qui permet aux utilisateurs de prendre des décisions éclairées sur le traitement des données dans les étapes suivantes du pipeline.
Points clés
Section intitulée « Points clés »| Composante | Détails |
|---|---|
| Entrées | Données brutes du SIGS (hmis_ISO3.csv) contenant les volumes de services des établissements par mois et par indicateurIdentifiants des zones géographiques/administratives Noms d’indicateurs normalisés |
| Sorties | M1_output_outliers.csv — drapeaux de valeurs aberrantes par établissement-mois-indicateurM1_output_outlier_list.csv — liste des valeurs aberrantes signalées (revue)M1_output_completeness.csv — drapeaux de complétude par établissement-mois-indicateurM1_output_consistency_geo.csv — résultats de cohérence sous-nationale par paire de ratiosM1_output_dqa.csv — scores composites de l’EQD (moyenne et réussite/échec) |
| Objectif | Évaluer la fiabilité des données SIGS par la détection des valeurs aberrantes, l’évaluation de l’exhaustivité et la vérification de la cohérence afin de garantir des données fiables pour l’estimation de la couverture |
!!! warning “Rappel : l’entrée doit être des volumes, pas des pourcentages”
Ce module attend des **volumes bruts de services** (nombre de visites, doses, accouchements déclarés par chaque établissement chaque mois). Les pourcentages, taux ou chiffres de couverture pré-calculés ne peuvent pas être analysés ici — la détection des valeurs aberrantes compare les valeurs à la distribution de volume propre à chaque établissement (un pourcentage plafonné à 100 ne contient aucun signal), et les drapeaux de complétude dépendent de la déclaration ou non d'un volume. Voir [Extraction des données](02_data_extraction) pour savoir quoi extraire de votre SIGS.Flux de travail analytique
Section intitulée « Flux de travail analytique »Aperçu des étapes analytiques
Section intitulée « Aperçu des étapes analytiques »Le module applique une séquence structurée de contrôles de la qualité des données, allant d’observations individuelles à une évaluation globale de la fiabilité des données :
Étape 1 : Préparation des données Les rapports mensuels des établissements sont chargés et organisés pour l’analyse. Les dates sont normalisées et les unités géographiques ainsi que les indicateurs de santé disponibles dans l’ensemble de données sont identifiés.
Étape 2 : Détection des valeurs aberrantes Pour chaque établissement et chaque indicateur (par exemple, les doses de vaccin Pentavalent ou les visites de soins prénatals), le module identifie les valeurs anormalement élevées qui peuvent refléter des erreurs de déclaration ou de saisie des données. Deux approches complémentaires sont utilisées : la détection statistique des valeurs aberrantes, basée sur les écarts par rapport à l’historique des rapports d’un établissement, et les vérifications proportionnelles qui signalent les mois représentant une part invraisemblablement importante du volume de services déclaré par l’établissement sur les 12 mois glissants précédents pour cet indicateur.
Étape 3 : Évaluation de l’exhaustivité Le module évalue la cohérence des rapports de l’établissement au fil du temps en construisant une chronologie complète des rapports pour chaque combinaison établissement-indicateur et en identifiant les mois manquants. Les établissements qui n’ont pas fait de déclaration pendant de longues périodes (six mois ou plus) sont classés comme inactifs plutôt qu’incomplets.
Étape 4 : Évaluation de la cohérence Les indicateurs connexes sont censés suivre des relations prévisibles. Par exemple, le nombre de premières visites de soins prénatals doit être supérieur au nombre de quatrièmes visites. Le module évalue ces relations à l’aide de ratios d’indicateurs calculés au niveau du district, en réduisant le biais dû au déplacement des patients entre les établissements, et signale les écarts par rapport aux modèles attendus.
Étape 5 : Vérifications de la disponibilité des indicateurs Avant d’appliquer les évaluations de cohérence, le module vérifie que les paires d’indicateurs requises sont présentes dans les données. Lorsque des indicateurs sont manquants, l’analyse s’adapte aux informations disponibles sans générer d’erreurs.
Étape 6 : Calcul du score EQD Pour un ensemble défini d’indicateurs de base (généralement la première dose de vaccin Pentavalent, la première visite de soins prénatals et les consultations externes), les résultats des contrôles des valeurs aberrantes, de l’exhaustivité et de la cohérence sont combinés pour obtenir un score global du EQD. Un mois-facilité ne reçoit le score le plus élevé que si tous les indicateurs de base répondent aux normes minimales dans les trois dimensions.
Étape 7 : Résultats Le module génère un ensemble de résultats structurés, y compris les indicateurs de valeurs aberrantes, les indicateurs d’exhaustivité, les résultats de cohérence et les scores finaux de l’EQD. Ces résultats sont utilisés dans les modules FASTR suivants et fournissent une base transparente pour l’examen et l’amélioration de la qualité des données.
Diagramme de flux de travail
Section intitulée « Diagramme de flux de travail »Points de décision clés
Section intitulée « Points de décision clés »Quand une valeur est-elle considérée comme aberrante ?
Les valeurs aberrantes sont identifiées en évaluant les variations au sein de l’établissement dans les rapports mensuels pour chaque indicateur. Une valeur est considérée comme aberrante si elle remplit l’un ou l’autre des critères suivants :
- La valeur dépasse 10 fois l’écart absolu médian (EAM) par rapport à la médiane mensuelle de l’indicateur ; ou
- La valeur représente plus de 80 % du volume total déclaré par l’établissement pour cet indicateur sur les 12 mois glissants se terminant à cette période et le nombre déclaré est supérieur à 100.
L’écart absolu est calculé en utilisant uniquement les valeurs égales ou supérieures à la médiane, afin de concentrer la détection sur les valeurs inhabituellement élevées et d’éviter de signaler les observations portant sur de faibles volumes.
Pourquoi la cohérence est-elle évaluée au niveau du district plutôt qu’au niveau de l’établissement ?
Les patients se font souvent soigner dans différents établissements au sein d’un même district, en fonction du service. Par exemple, une femme peut recevoir sa première visite de soins prénatals dans un centre de santé primaire, mais accoucher dans un hôpital de district. L’évaluation de la cohérence au niveau du district tient compte de ces mouvements de patients et fournit une représentation plus précise des schémas d’utilisation des services.
Que se passe-t-il lorsque les indicateurs requis sont manquants ?
Le module s’adapte aux données disponibles. Si les paires d’indicateurs nécessaires à l’évaluation de la cohérence sont manquantes, les contrôles de cohérence ne sont pas appliqués et le score EQD est calculé en utilisant uniquement les dimensions d’aberration et d’exhaustivité. L’analyse se poursuit en utilisant les dimensions de qualité qui peuvent être évaluées.
Comment les installations inactives sont-elles gérées ?
Les établissements qui n’ont pas fait de déclaration pendant six mois consécutifs ou plus au début ou à la fin de leur période de déclaration sont classés comme inactifs pour ces mois plutôt qu’incomplets. Cela évite de pénaliser les installations qui n’ont pas encore commencé à faire leur déclaration ou qui ont définitivement cessé leurs activités.
Traitement des données et résultats
Section intitulée « Traitement des données et résultats »Aperçu de la transformation
Le module transforme les rapports d’installation bruts en ensembles de données marqués d’un label de qualité en suivant les étapes suivantes :
- Format d’entrée : Observations mensuelles avec l’identifiant de l’établissement, la période de déclaration, l’indicateur et le nombre déclaré
- Enrichissement : Calcul des statistiques de soutien, y compris les valeurs médianes, les résidus basés sur le MAD et les contributions proportionnelles en volume
- Complétion : Génération explicite d’enregistrements pour les mois manquants, convertissant les lacunes implicites en points de données observables
- Agrégation : Agrégation des données au niveau de l’établissement au niveau du district pour l’évaluation de la cohérence
- Marquage de la qualité : Attribution d’indicateurs de qualité binaires pour les valeurs aberrantes, l’exhaustivité et la cohérence
- Notation : Combinaison des indicateurs de qualité en scores continus (0-1) et en indicateurs de réussite/échec correspondants
- Format de sortie : Production de plusieurs fichiers de sortie adaptés à différentes utilisations analytiques, y compris l’examen rapide des valeurs aberrantes, l’analyse complète de la qualité des données et les données d’entrée pour les modules FASTR en aval
Le module traite les données en format long, avec un enregistrement par combinaison installation-indicateur-période, et produit des mesures standardisées de la qualité des données qui sont utilisées par les modules suivants pour informer les décisions d’ajustement, de pondération ou d’exclusion des données.
Résultats de l’analyse et visualisation
Section intitulée « Résultats de l’analyse et visualisation »L’analyse FASTR génère six principaux résultats visuels (chacun est également produit sous forme de carte sous-nationale correspondante, à l’exception de la complétude dans le temps) :
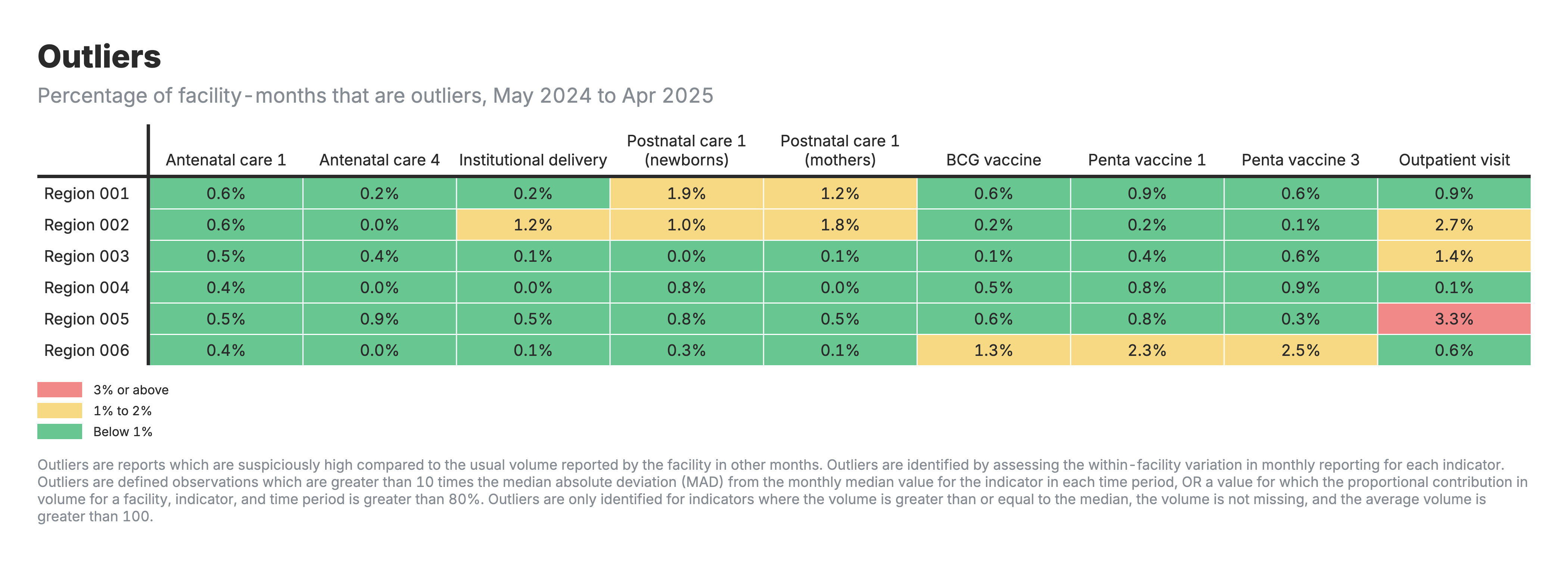
1. Heatmap des valeurs aberrantes
Tableau de la heatmap avec les zones comme lignes et les indicateurs de santé comme colonnes, codés par couleur en fonction du pourcentage de valeurs aberrantes.
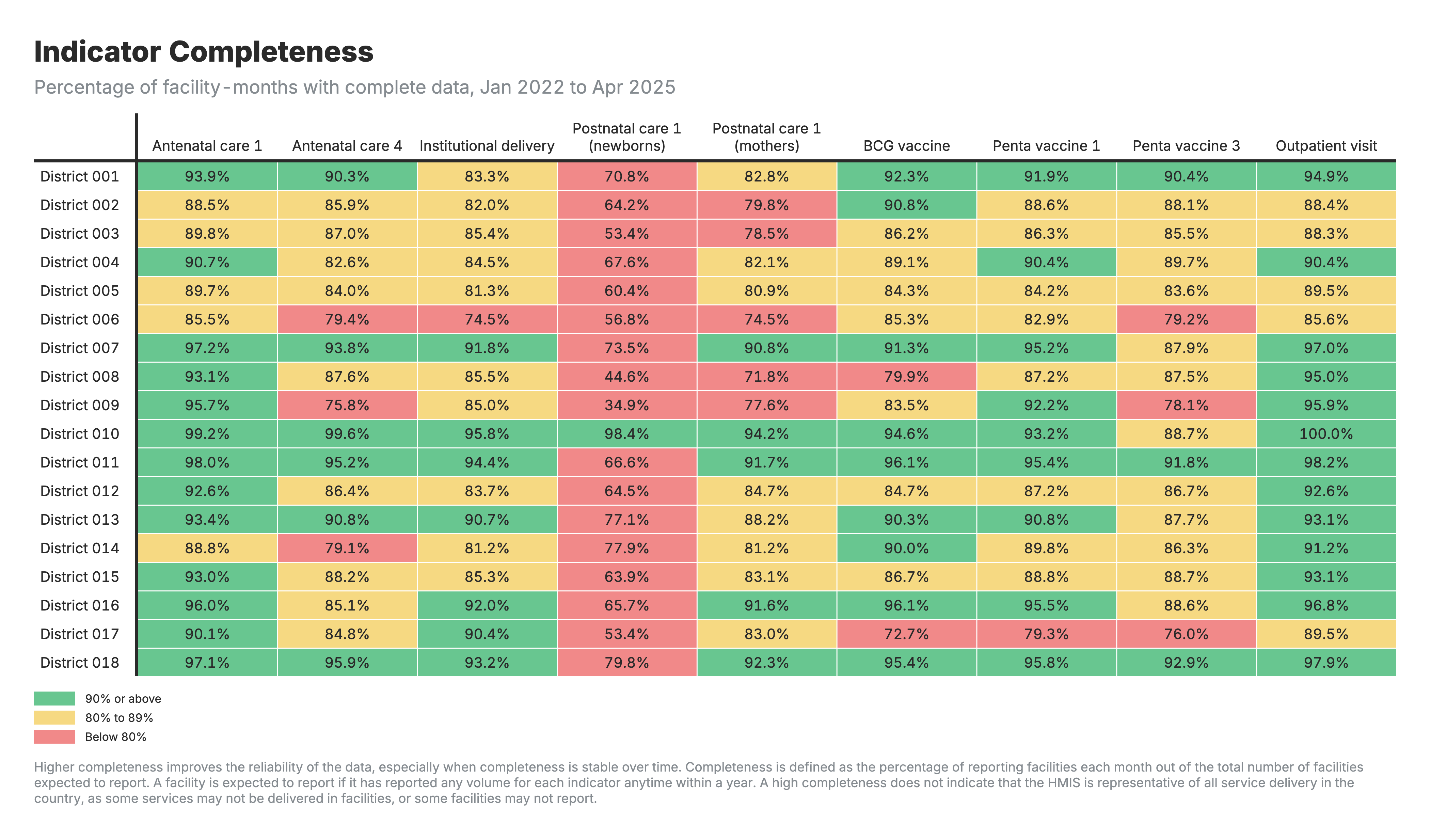
2. Complétude de l’indicateur
Tableau de la heatmap avec les zones en lignes et les indicateurs de santé en colonnes, codés par couleur en fonction du pourcentage d’exhaustivité.
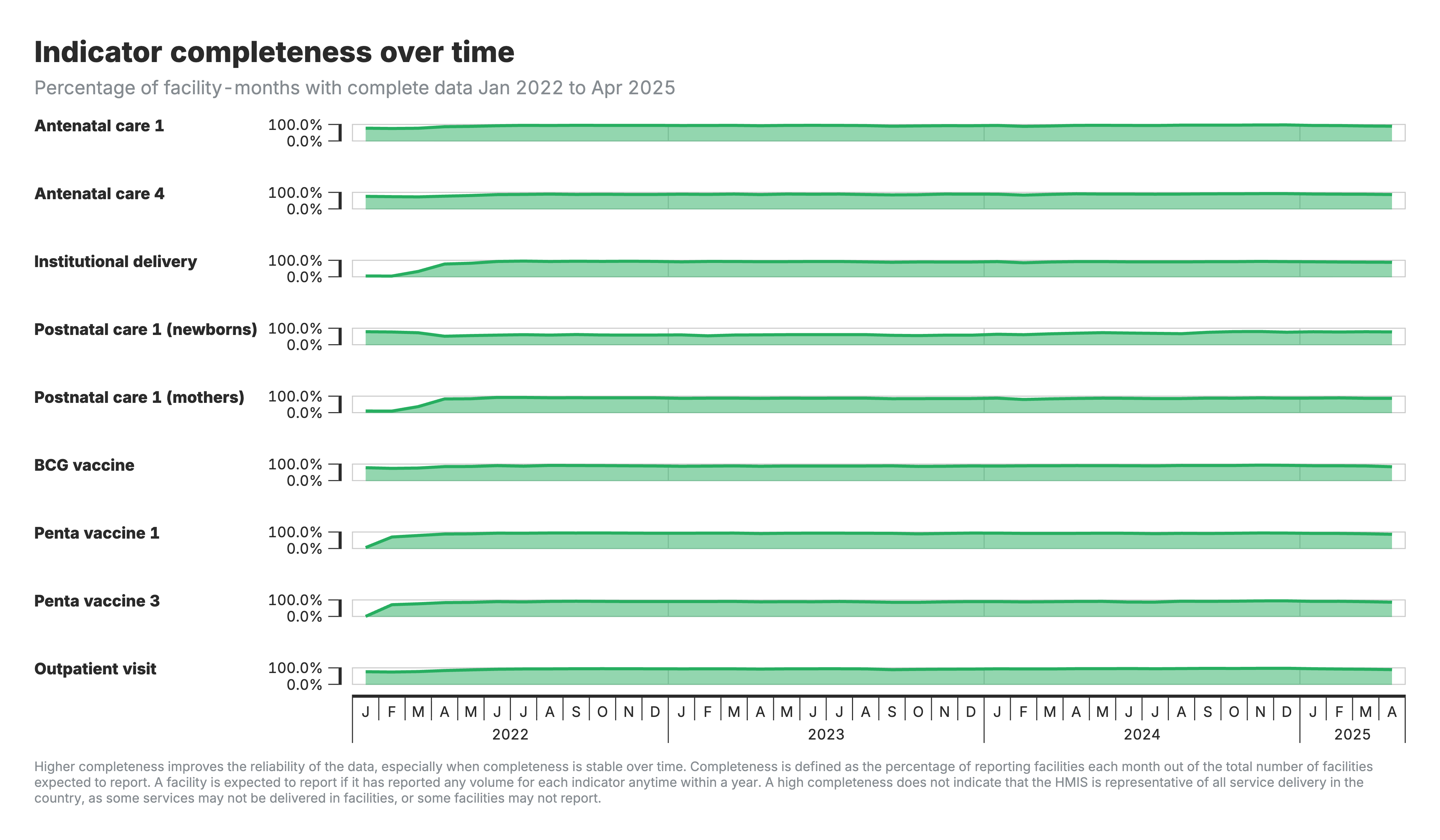
3. Complétude des indicateurs dans le temps
Graphiques chronologiques horizontaux montrant les tendances en matière d’exhaustivité pour chaque indicateur au cours de la période d’analyse.
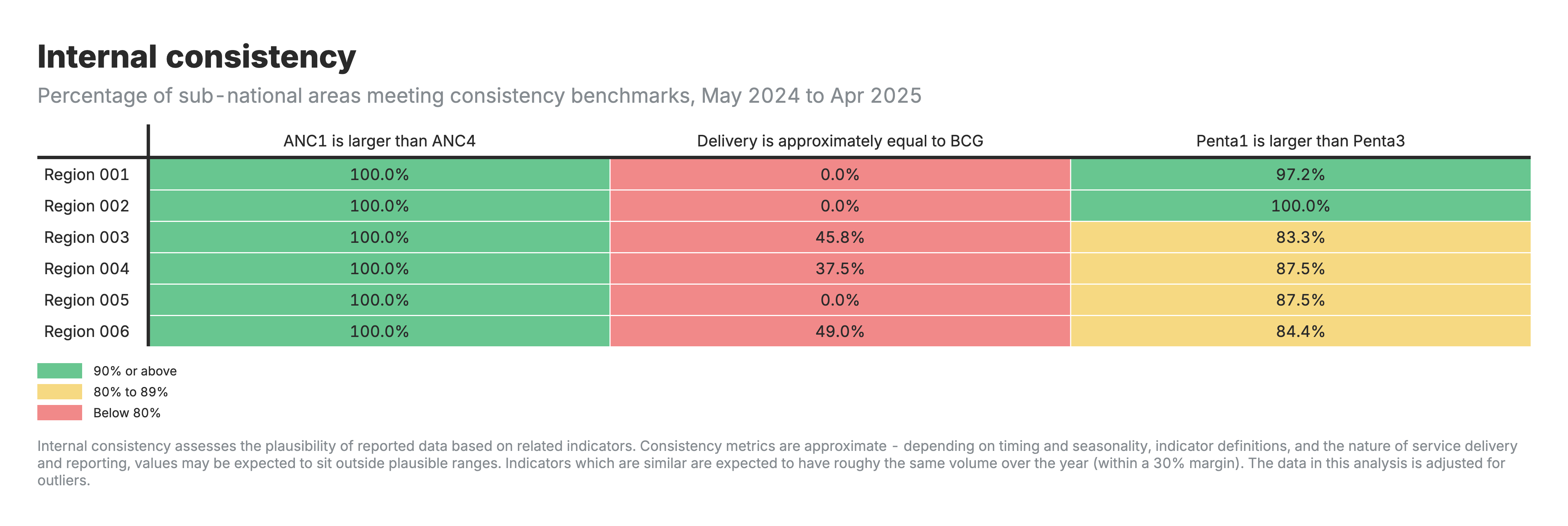
4. Cohérence interne
Tableau de la heatmap avec les zones comme lignes et les catégories de repères de cohérence comme colonnes, codées par couleur en fonction de la performance.
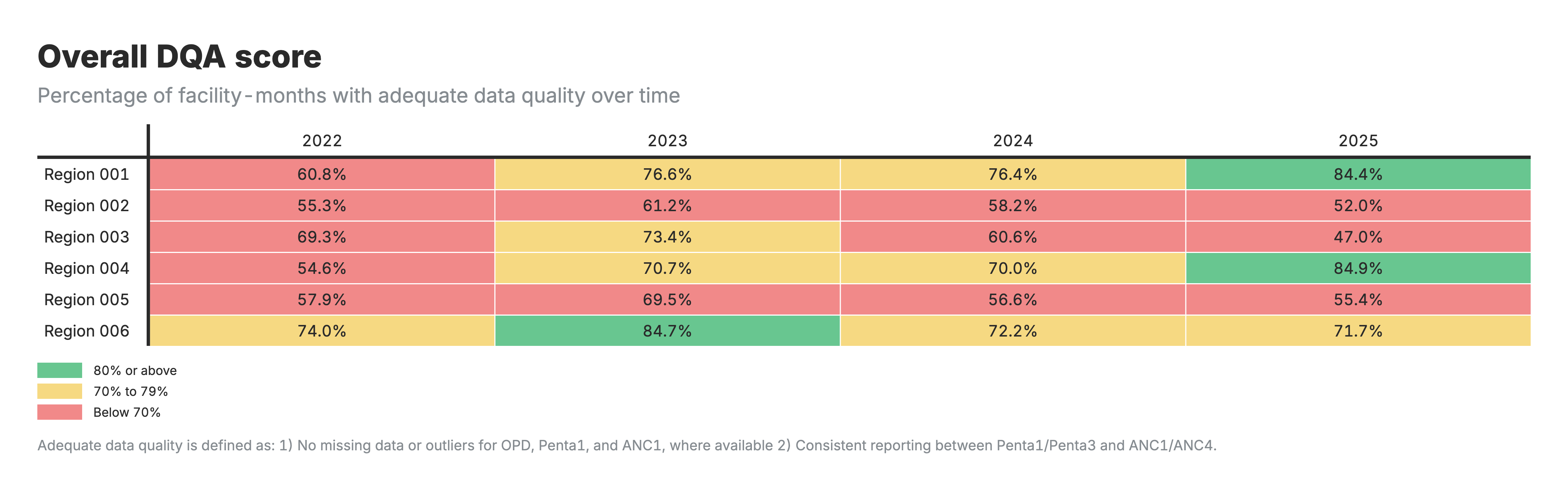
5. Score global du EQD
Tableau de la heatmap avec les zones comme lignes et les périodes comme colonnes, codées par couleur en fonction du pourcentage du score EQD.
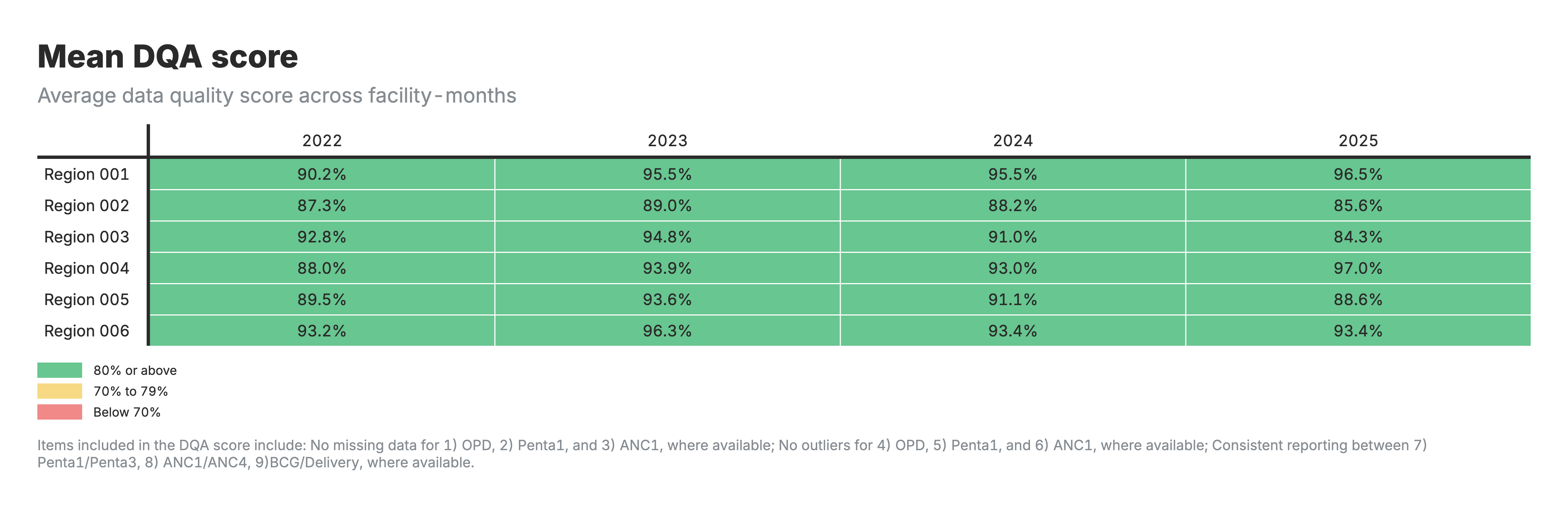
6. Score moyen de l’EQD
Tableau de la heatmap avec les zones comme lignes et les périodes comme colonnes, codées par couleur en fonction du score moyen de l’EQD.
Guide d’interprétation
Pour les heatmaps (sorties 1, 2, 4, 5, 6) :
- Lignes : Zones géographiques (zones/régions)
- Colonnes : Indicateurs de santé ou périodes de temps
Pour la heatmap des valeurs aberrantes (résultat 1) :
- Valeurs : Pourcentage de mois d’établissement signalés comme aberrants
- Des pourcentages plus faibles indiquent moins de valeurs extrêmes
Pour la heatmap de l’exhaustivité des indicateurs (résultat 2) :
- Valeurs : Pourcentage de mois d’installation avec un rapport complet
- Des pourcentages plus élevés indiquent un rapport plus complet
Pour le graphique de l’exhaustivité de l’indicateur dans le temps (résultat 3) :
- Tableau chronologique horizontal montrant les tendances de l’exhaustivité par indicateur
- Axe X : Période de temps
- Axe Y : Pourcentage d’exhaustivité
- Indique si les rapports s’améliorent, diminuent ou sont stables
Pour la heatmap de la cohérence interne (résultat 4) :
- Valeurs : Pourcentage de domaines répondant aux critères de cohérence
- Indique si les indicateurs liés suivent les relations attendues (par exemple, CPN1 ≥ CPN4)
Pour les heatmaps des scores de l’EQD (résultats 5-6) :
- Sortie 5 : Pourcentage de mois de l’établissement ayant passé tous les contrôles de qualité
- Résultat 6 : Score moyen de l’EQD sur l’ensemble des mois de l’établissement
- Des scores plus élevés indiquent une meilleure qualité globale des données
Référence détaillée
Section intitulée « Référence détaillée »Cette section fournit des détails techniques aux personnes chargées de la mise en œuvre, aux développeurs et aux analystes qui ont besoin de comprendre la méthodologie sous-jacente.
Paramètres de configuration
Section intitulée « Paramètres de configuration »Le module utilise plusieurs paramètres configurables qui contrôlent le comportement de l’analyse :
Paramètres géographiques
# Country identifierCOUNTRY_ISO3 <- "GIN" # ISO3 country code
# Geographic level for consistency analysisGEOLEVEL <- "admin_area_3" # Admin level (1=national, 2=région, 3=district, etc.)Le paramètre GEOLEVEL détermine le niveau d’agrégation pour l’analyse de cohérence. Les niveaux administratifs inférieurs (3-4) permettent de saisir les tendances locales, mais les données peuvent être rares. Les niveaux supérieurs (2) fournissent des estimations plus stables mais peuvent masquer des incohérences locales.
Paramètres de détection des valeurs aberrantes
# Proportion threshold for outlier detectionOUTLIER_PROPORTION_THRESHOLD <- 0.8 # Flag if single month > 80% of the trailing 12-month total
# Minimum count to consider for outlier flaggingMINIMUM_COUNT_THRESHOLD <- 100 # Only flag valeurs aberrantes with count > 100
# Number of median absolute deviations for statistical valeur aberrante detectionMADS <- 10 # Flag if value > 10 MADs from medianTuning guidance:
- Détection plus sensible : Abaisser
OUTLIER_PROPORTION_THRESHOLDà 0,6-0,7, réduireMADSà 8 - Détection moins sensible : Augmenter
OUTLIER_PROPORTION_THRESHOLDà 0,9, augmenterMADSà 12-15 - Petites installations : Réduire
MINIMUM_COUNT_THRESHOLDà 50 - Grandes installations uniquement : Augmenter
MINIMUM_COUNT_THRESHOLDà 200+
Sélection des indicateurs de l'EQD
# Core indicators used for DQA scoring (default)DQA_INDICATORS <- c("anc1", "penta1", "opd")
# Consistency pairs to evaluate (default)CONSISTENCY_PAIRS_USED <- c("penta", "anc", "delivery")Valeurs acceptées pour DQA_INDICATORS (paramètre de la plateforme) : tout sous-ensemble de c("anc1", "penta1", "opd").
Valeurs acceptées pour CONSISTENCY_PAIRS_USED (paramètre de la plateforme) : tout sous-ensemble de c("penta", "anc", "delivery", "malaria").
Plages de référence de cohérence
all_consistency_ranges <- list( pair_penta = c(lower = 0.95, upper = Inf), # Penta1 >= 0.95 * Penta3 pair_anc = c(lower = 0.95, upper = Inf), # ANC1 >= 0.95 * ANC4 pair_delivery = c(lower = 0.7, upper = 1.3), # 0.7 <= BCG/Delivery <= 1.3 pair_malaria = c(lower = 0.9, upper = 1.1) # Malaria indicators within 10%)Les fourchettes reflètent les attentes du programme. Par exemple, la CPN1 devrait toujours être au moins 95% de la CPN4 (plus de femmes commencent les soins que de femmes qui vont jusqu’au bout des quatre visites). La tolerance de 5 % tient compte des variations dans la saisie des données. Le BCG, en tant que vaccin administré à la naissance, devrait correspondre approximativement au nombre d’accouchements dans les établissements de santé, avec une tolerance de 30 % pour les variations.
Spécifications des entrées/sorties
Section intitulée « Spécifications des entrées/sorties »Structure du fichier d’entrée
Section intitulée « Structure du fichier d’entrée »Fichier requis : hmis_[COUNTRY_ISO3].csv
Colonnes requises:
facility_id(caractère/entier) : Identifiant unique pour chaque établissement de santéperiod_id(nombre entier) : Période au format AAAAMM (par exemple, 202401 pour janvier 2024)indicator_common_id(caractère) : Noms d’indicateurs standardisés (par exemple, “penta1”, “anc1”, “opd”)count(numérique) : Volume ou nombre de services pour l’indicateuradmin_area_1àadmin_area_8(caractères) : Colonnes de zones géographiques/administratives
Exemple de format:
facility_id,period_id,indicator_common_id,count,admin_area_1,admin_area_2,admin_area_3FAC001,202401,penta1,45,Country_A,Province_A,District_AFAC001,202401,anc1,67,Country_A,Province_A,District_AFAC001,202402,penta1,52,Country_A,Province_A,District_AExigences en matière de données:
- Au moins 12 mois de données recommandés pour une détection robuste des valeurs aberrantes
- Les valeurs manquantes sont représentées par NA ou par des lignes absentes (les deux sont traitées)
- Les zéros doivent être des zéros explicites et non des valeurs manquantes
- Les colonnes géographiques sont détectées automatiquement (les colonnes 2 à 8 sont facultatives)
Fichiers de sortie
Section intitulée « Fichiers de sortie »M1_output_outlier_list.csv - Valeurs aberrantes marquées uniquement
Objectif : Liste de référence rapide des seules observations signalées comme aberrantes
Colonnes:
facility_id: Identifiant de l’installationadmin_area_[2-8]: Zones géographiques (incluses dynamiquement en fonction des données)indicator_common_id: Nom de l’indicateur de santéperiod_id: Période (YYYYMM)count: Volume de services déclarés
Cas d’utilisation : Les gestionnaires de données examinent des valeurs aberrantes spécifiques en vue d’une enquête ou d’une correction
M1_output_outliers.csv - Tous les enregistrements avec des indicateurs de valeurs aberrantes
Objectif : Ensemble complet de données avec indicateurs de valeurs aberrantes pour toutes les combinaisons établissement-indicateur-période
Colonnes:
facility_id: Identifiant de l’établissementadmin_area_[2-8]: Zones géographiques (incluses dynamiquement en fonction des données)period_id: Période (YYYYMM)indicator_common_id: Nom de l’indicateur de santéoutlier_flag: Indicateur de valeurs aberrantes combinées finales (0 = pas de valeurs aberrantes, 1 = valeurs aberrantes)
Cas d’utilisation :
- Entrée pour le module 2 (Ajustements de la qualité des données)
- Analyse statistique des modèles de valeurs aberrantes
- Génération de visualisations de la prévalence des valeurs aberrantes
M1_output_completeness.csv - Statut de complétude
Objectif : Indicateurs d’exhaustivité pour toutes les combinaisons établissement-indicateur-période, y compris les enregistrements explicitement créés pour les mois manquants
Colonnes:
facility_id: Identifiant de l’établissementadmin_area_[2-8]: Zones géographiques (incluses dynamiquement en fonction des données)indicator_common_id: Nom de l’indicateur de santéperiod_id: Période (AAAAMM)completeness_flag: 0=Incomplet (manquant), 1=Complet (rapporté)
Caractéristiques particulières :
- Contient des lignes explicites pour les mois non déclarés
- Les périodes inactives (6+ mois au début/à la fin avec completeness_flag=2) sont exclues de l’exportation
- Séries temporelles complètes pour chaque combinaison établissement-indicateur
Cas d’utilisation :
- Calcul des pourcentages d’exhaustivité
- Identification des lacunes en matière de déclaration
- Analyse des tendances du comportement en matière de déclaration
M1_output_consistency_geo.csv - Cohérence au niveau géographique
Objectif : Indicateurs de cohérence calculés au niveau géographique spécifié (par exemple, district)
Colonnes:
admin_area_[2-8]: Identifiants géographiques jusqu’au niveau géographique spécifié (inclus dynamiquement en fonction des données)period_id: Période (YYYYMM)ratio_type: Nom de la paire de cohérence (par exemple, “pair_penta”, “pair_anc”)sconsistency: Indicateur binaire (1=consistant, 0=inconsistant, NA=incapable de calculer)
Format : Format long avec une ligne par type de zone géographique-période-ratio
Cas d’utilisation :
- Comprendre les modèles de prestation de services au niveau du district
- Identifier les zones géographiques présentant des problèmes de cohérence
- Création de heatmaps de cohérence par zone
M1_output_dqa.csv - notes finales de l'EQD
Objectif : Scores composites de qualité des données par établissement et par période
Colonnes:
facility_id: Identifiant de l’établissementadmin_area_[2-8]: Zones géographiques (incluses dynamiquement en fonction des données)period_id: Période (YYYYMM)dqa_mean: Moyenne des scores des composants (0-1)dqa_score: Réussite/échec global(e) binaire (1 = tous les contrôles sont réussis ; 0 = un contrôle a échoué)
Cas d’utilisation :
- Filtrage des données pour les modules suivants (par exemple, n’utiliser que les mois d’installation avec dqa_score=1)
- Suivi des tendances de la qualité des données dans le temps
- Identifier les établissements qui ont besoin d’un soutien pour améliorer la qualité des données
Documentation sur les fonctions clés
Section intitulée « Documentation sur les fonctions clés »load_and_preprocess_data()
Signature : load_and_preprocess_data(file_path)
But : Charge les données SIGS et les prépare pour l’analyse en créant les champs de date et les indicateurs composites nécessaires
Paramètres:
file_path(caractère) : Chemin d’accès au fichier CSV du SIGS
Retourne : Liste contenant :
data: Cadre de données prétraité avec le champ date ajoutégeo_cols: Vecteur de noms de colonnes géographiques détectés
Processus:
- Lecture du fichier CSV contenant les données SIGS
- Convertit
period_id(format YYYYMM) en objets Date pour l’ordre temporel - Détecte toutes les colonnes relatives aux zones administratives (admin_area_1 à admin_area_8)
- Crée un indicateur composite du paludisme s’il existe des indicateurs constitutifs :
- Combine
rdt_positive+micro_positiveenrdt_positive_plus_micro - Cet indicateur composite est utilisé pour les contrôles de cohérence relatifs au paludisme
- Combine
Exemple:
inputs <- load_and_preprocess_data("hmis_ISO3.csv")data <- inputs$datageo_cols <- inputs$geo_colsvalidate_consistency_pairs()
Signature : validate_consistency_pairs(consistency_params, data)
But : Valide que les paires d’indicateurs requises existent dans l’ensemble de données avant d’exécuter l’analyse de cohérence
Paramètres:
consistency_params: Liste contenant les consistency_pairs et consistency_rangesdata: L’ensemble de données SIGS
Retourne : Mise à jour des consistency_params avec seulement les paires valides (liste vide s’il n’y a pas de paires valides)
Processus:
- Vérifie quels indicateurs sont disponibles dans l’ensemble de données
- Supprime les paires de cohérence pour lesquelles un ou les deux indicateurs sont manquants
- Émet des avertissements concernant les paires supprimées
- Retourne une liste vide s’il ne reste plus de paires valides
Exemple de sortie:
Warning: Skipping pair_delivery - indicator 'delivery' not found in dataWarning: Skipping pair_malaria - indicator 'rdt_positive_plus_micro' not found in dataRemaining consistency pairs: pair_penta, pair_ancoutlier_analysis()
Signature : outlier_analysis(data, geo_cols, outlier_params)
But : Identifier les valeurs aberrantes statistiques dans les volumes de services des installations à l’aide de deux méthodes de détection
Paramètres:
data: Données SIGS avec facility_id, indicator_common_id, period_id, countgeo_cols: Vecteur de noms de colonnes géographiquesoutlier_params: Liste contenant :outlier_pc_threshold: Seuil de proportion (par défaut 0.8)count_threshold: Seuil de comptage minimum (par défaut 100)
Résultats : Cadre de données avec les indicateurs de valeurs aberrantes et les mesures de diagnostic pour chaque établissement-indicateur-période
Champs calculés:
median_volume: Nombre médian par indicateur d’établissementmad_volume: MAD calculé sur les valeurs >= médianemad_residual: Résidu standardisé (|comptage - médiane| / MAD)outlier_mad: Drapeau binaire (1 si mad_residual > MADS)pc: Contribution proportionnelle au total des 12 mois glissants (fenêtre se terminant à la période de la ligne)outlier_pc: Indicateur binaire (1 si pc > seuil)outlier_flag: Indicateur final (1 si l’un des indicateurs de la méthode ET le nombre > seuil minimum)
Algorithm steps:
Étape 1 : Calculer le volume médian pour chaque combinaison établissement-indicateur
Étape 2 : Calculer la DAM en utilisant uniquement les valeurs égales ou supérieures à la médiane
- Évite les biais dus aux établissements ayant de nombreux mois à faible volume
- Standardise les résidus en divisant (nombre - médiane) par MAD
- Drapeaux outlier_mad = 1 si mad_residual > paramètre MADS
Étape 3 : Calcul de la contribution proportionnelle
- Pour chaque établissement-indicateur-période, additionner le nombre sur les 12 mois glissants se terminant à cette période (fenêtre mobile par établissement × indicateur)
- Calculer pc = count / window_total (pc est NA si le total de la fenêtre vaut 0)
- Drapeaux outlier_pc = 1 si pc > OUTLIER_PROPORTION_THRESHOLD
- Ce dénominateur glissant remplace un dénominateur d’année civile, qui signalait à tort les établissements dont la seule déclaration se situait en début d’année civile (leur unique mois était son propre dénominateur)
Étape 4 : Combiner les drapeaux
- Indicateur de valeur aberrante finale = 1 si (outlier_mad = 1 OR outlier_pc = 1) AND count > MINIMUM_COUNT_THRESHOLD
- Le seuil (100 par défaut) garantit que seuls les volumes importants sont signalés, ce qui permet d’éviter les faux positifs dans les établissements à faible volume
process_completeness()
Signature : process_completeness(outlier_data_main)
But : Fonction d’orchestration principale qui génère des séries temporelles complètes et attribue des indicateurs de complétude pour tous les indicateurs
Paramètres:
outlier_data_main: Résultats de l’analyse des valeurs aberrantes (contient toutes les combinaisons installation-indicateur-période avec leur nombre)
Résultats : Ensemble de données au format long avec les indicateurs d’exhaustivité pour toutes les combinaisons établissement-indicateur-période
Processus:
- Identifie la première et la dernière période de rapport pour chaque indicateur au niveau mondial
- Appelle
generate_full_series_per_indicator()pour chaque indicateur - Applique la logique de marquage d’exhaustivité (complet/incomplet/inactif)
- Fusionne avec les métadonnées géographiques
- Combine les résultats de tous les indicateurs
- Supprime les périodes inactives (completeness_flag = 2)
Structure de sortie:
- Lignes explicites pour les périodes déclarées et non déclarées
- Indicateur d’exhaustivité : 0 (incomplet), 1 (complet), 2 (inactif - supprimé)
- Séries temporelles complètes de la première à la dernière période de déclaration par indicateur
generate_full_series_per_indicator()
Signature : generate_full_series_per_indicator(outlier_data, indicator_id, timeframe)
Objectif : Crée une série chronologique mensuelle complète pour un indicateur spécifique, en comblant les lacunes lorsque les établissements n’ont pas fait de déclaration
Paramètres:
outlier_data: data.table avec des résultats aberrantsindicator_id: Indicateur spécifique à traiter (par exemple, “penta1”)timeframe: Tableau de données avec first_pid et last_pid pour chaque indicateur
Résultats : Série chronologique complète avec des lignes explicites pour les périodes déclarées et non déclarées
Processus:
- Sous-ensemble de données pour un indicateur spécifique
- Génère une séquence mensuelle de la première à la dernière
period_idpour cet indicateur - Crée une grille complète établissement-période (tous les établissements × tous les mois) en utilisant la jointure croisée
CJ() - Fusionne avec les données réelles déclarées
- Les chiffres manquants indiquent les périodes non déclarées
- Application de l’algorithme de détection des inactifs
Algorithme de détection inactive:
# A facility is flagged inactive (offline_flag = 2) if:# 1. Missing 6+ consecutive months BEFORE first report, OR# 2. Missing 6+ consecutive months AFTER last report
offline_flag := fifelse( (missing_group == 1 & missing_count >= 6 & !first_report_idx) | (missing_group == max(missing_group) & missing_count >= 6 & !last_report_idx), 2L, 0L)Exemple de chronologie:
Facility A reporting pattern for indicator "penta1":Period: 202001 202002 202003 202004 202005 202006 202007 202008 202009 202010Count: NA NA NA NA 50 30 NA NA 40 35Flag: 2 2 2 2 1 1 0 0 1 1 [----Inactive----] [---Active period with gaps---]
Explanation:- First 4 months: Inactive (6+ months missing before first report at 202005)- 202005-202006: Complete (reported)- 202007-202008: Incomplete (gaps in active period)- 202009-202010: Complete (reported)geo_consistency_analysis()
Signature : geo_consistency_analysis(data, geo_cols, geo_level, consistency_params)
Objectif : Calcul des ratios de cohérence au niveau géographique pour tenir compte des patients qui recherchent des services dans plusieurs établissements au sein d’un district ou d’une région
Paramètres:
data: Données aberrantes (avec les données aberrantes déjà marquées)geo_cols: Vecteur de noms de colonnes géographiquesgeo_level: Niveau géographique pour l’agrégation (par exemple, “admin_area_3”)consistency_params: Liste avec consistency_pairs et consistency_ranges
Résultats : Cadre de données au format long avec les résultats de cohérence au niveau géographique
Processus:
- Exclut les valeurs aberrantes (définit le nombre à NA lorsque outlier_flag = 1)
- Agrégation des données au niveau géographique spécifié par période (somme des installations)
- Reformule les données en format large (une colonne par indicateur)
- Calcul du ratio pour chaque paire d’indicateurs
- Signale la cohérence sur la base d’intervalles prédéfinis
Colonnes de sortie:
- Identifiants géographiques (jusqu’au niveau spécifié)
period_id: Période de tempsratio_type: Nom de la paire de cohérence (par exemple, “pair_penta”)consistency_ratio: Valeur du ratio calculésconsistency: Indicateur binaire (1 = cohérent, 0 = incohérent, NA = impossible à calculer)
Exemple de sortie:
admin_area_2 admin_area_3 period_id ratio_type consistency_ratio sconsistencyDistrict_A Ward_1 202401 pair_penta 1.05 1District_A Ward_1 202401 pair_anc 0.88 0District_A Ward_2 202401 pair_penta 0.97 1Justification : La mesure de la cohérence au niveau géographique tient compte des déplacements des patients entre les établissements et fournit une image plus précise des schémas d’utilisation des services au sein d’une communauté.
expand_geo_consistency_to_facilities()
Signature : expand_geo_consistency_to_facilities(établissement_metadata, geo_consistency_results, geo_level)
Objectif : Attribuer des résultats de cohérence au niveau géographique à des installations individuelles
Paramètres:
facility_metadata: Liste d’installations avec affectations géographiquesgeo_consistency_results: Sortie de geo_consistency_analysis()geo_level: Niveau géographique utilisé dans l’analyse de cohérence
Retourne : Jeu de données au niveau de l’établissement avec drapeaux de cohérence
Processus:
- Extraction de la liste des établissements avec leurs affectations géographiques
- Effectue une jointure à gauche pour répliquer les scores de cohérence au niveau géographique à tous les établissements de cette zone
- Utilise une relation de plusieurs à plusieurs pour gérer plusieurs périodes et types de ratios
Justification : Étant donné que la cohérence est mesurée au niveau géographique (en tenant compte des déplacements des patients entre les établissements), tous les établissements d’un même district ou d’une même région reçoivent les mêmes scores de cohérence.
dqa_with_consistency()
Signature : dqa_with_consistency(completeness_data, consistency_data, outlier_data, geo_cols, dqa_rules)
But : Calcule les scores complets de l’EQD, y compris les contrôles de cohérence lorsque des paires de cohérence sont disponibles
Paramètres:
completeness_data: Sortie de process_completeness()consistency_data: Résultats de la cohérence de l’installation au format largeoutlier_data: Sortie de outlier_analysis()geo_cols: Vecteur de noms de colonnes géographiquesdqa_rules: Liste spécifiant les valeurs requises pour chaque dimension
Configuration des règles de l’EQD:
dqa_rules <- list( completeness = 1, # Must be complete (flag = 1) outlier_flag = 0, # Must NOT be an outlier (flag = 0) sconsistency = 1 # Must be consistent (flag = 1))Algorithme de notation:
1. Score d’exhaustivité et de valeurs aberrantes (par établissement et par période) :
- Chaque indicateur EQD obtient 0 à 2 points (1 pour l’exhaustivité + 1 pour l’absence de valeurs aberrantes)
- Maximum possible = 2 × nombre d’indicateurs EQD
- Score = Total des points / Maximum des points
2. Score de cohérence (par période d’installation) :
- Ne compte que les paires pour lesquelles les deux indicateurs existent (les paires NA sont exclues du dénominateur)
- Score = Nombre de paires réussies / Nombre de paires disponibles
- Si aucune paire n’est disponible, le score = 0
3. Score moyen de l’EQD:
- Moyenne de la note d’exhaustivité et de la note de cohérence
- Formule :
(completeness_outlier_score + consistency_score) / 2
4. Note binaire de l’EQD:
- 1 si tous les contrôles sont réussis (complet, pas de valeurs aberrantes, cohérent)
- 0 si l’un des contrôles échoue
**Traitement des indicateurs manquants La fonction gère intelligemment les cas où certains indicateurs de cohérence sont manquants :
- Les valeurs NA dans les paires de cohérence ne sont PAS remplacées par 0
- Seules les paires disponibles contribuent au dénominateur
- Cela évite de pénaliser les établissements pour des indicateurs qu’ils ne fournissent pas
Exemple de calcul:
Facility X in period 202401:- DQA Indicators: penta1, anc1, opd (3 indicators)- Completeness: All 3 complete → 3 points- Outliers: None → 3 points- Total: 6/6 → completeness_outlier_score = 1.0
Consistency Pairs:- pair_penta (penta1/penta3): Pass (1)- pair_anc (anc1/anc4): Fail (0)- pair_delivery: NA (bcg not a DQA indicator)
Consistency calculation:- Available pairs: 2 (penta, anc)- Passing pairs: 1 (penta)- consistency_score = 1/2 = 0.5
Final scores:- dqa_mean = (1.0 + 0.5) / 2 = 0.75- dqa_score = 0 (not all pairs passed)dqa_without_consistency()
Signature : dqa_without_consistency(completeness_data, outlier_data, geo_cols, dqa_rules)
But : Calcul des scores EQD en utilisant uniquement les contrôles d’exhaustivité et de valeurs aberrantes lorsque les données de cohérence ne sont pas disponibles ou qu’il n’existe pas de paires de cohérence valides
Quand on l’utilise:
- Aucune paire de cohérence n’est définie dans la configuration
- Toutes les paires de cohérence ont des indicateurs manquants
- L’ensemble de données ne contient pas d’indicateurs appariés
Notation:
- Utilise uniquement les composantes d’exhaustivité et de valeurs aberrantes
dqa_mean=completeness_outlier_scoredqa_score= 1 si tous les contrôles d’exhaustivité et de valeurs aberrantes sont réussis, 0 sinon
Structure de sortie:
dqa_results <- data.frame( facility_id, admin_area_X, # Dynamic geographic columns period_id, completeness_outlier_score, # Range: 0-1 dqa_mean, # Range: 0-1 (equals completeness_outlier_score) dqa_score # Binary: 0 or 1)Méthodes statistiques et algorithmes
Section intitulée « Méthodes statistiques et algorithmes »Calcul de l'écart absolu médian (MAD)
Le MAD est une mesure robuste de la variabilité qui est moins sensible aux valeurs aberrantes que l’écart-type.
Algorithme MAD standard:
- Calculer la médiane de l’ensemble de données
- Calculer les écarts absolus : |Valeur - médiane pour chaque point de données
- Trouver la médiane de ces écarts absolus
FASTR Modification: Le module calcule le MAD en utilisant uniquement les valeurs égales ou supérieures à la médiane, ce qui le rend plus sensible aux valeurs aberrantes élevées tout en évitant les biais dus aux établissements ayant de nombreux mois à faible volume.
Calcul du degré de valeur aberrante:
$$ \text{MAD Résiduel} = \frac{|\text{volume} - \text{volume médian}|}{\text{MAD}} $$
Classification des valeurs aberrantes:
- Si le résidu MAD > 10 (configurable via le paramètre
MADS), la valeur est marquée comme une valeur aberrante basée sur MAD (outlier_mad = 1) - Le
outlier_flagfinal requiert également un nombre > 100
Exemple:
Facility ABC, Indicator: penta1Monthly counts: 20, 25, 22, 28, 24, 26, 150, 23, 27, 25, 21, 24
Step 1: Calculate median = 24.5Step 2: Values >= median: 25, 28, 24.5, 26, 150, 27, 25, 24.5Step 3: Absolute deviations from median: 0.5, 3.5, 0, 1.5, 125.5, 2.5, 0.5, 0Step 4: MAD = median(0, 0, 0.5, 0.5, 1.5, 2.5, 3.5, 125.5) = 1.0Step 5: For count=150: MAD residual = |150 - 24.5| / 1.0 = 125.5Step 6: 125.5 > 10 AND 150 > 100, therefore outlier_flag = 1Détection proportionnelle des valeurs aberrantes
Cette méthode permet d’identifier les mois où une seule observation représente une proportion anormalement élevée du volume déclaré par l’établissement pour cet indicateur sur les 12 mois précédents.
Algorithme:
- Pour chaque établissement-indicateur-période, additionner le nombre sur les 12 mois glissants se terminant à cette période (fenêtre mobile par établissement × indicateur)
- Calculer la proportion :
pc = monthly_count / window_total(NA si le total de la fenêtre vaut 0) - Marquer comme aberration proportionnelle (
outlier_pc = 1) sipc > OUTLIER_PROPORTION_THRESHOLD(par défaut 0,8) - Le
outlier_flagfinal requiert également un nombre > 100
Raison d’être: Un établissement déclarant 80 % de son volume des 12 derniers mois en un seul mois indique probablement une erreur de saisie des données (par exemple, déclaration cumulative au lieu d’une déclaration mensuelle, chiffre supplémentaire saisi). La fenêtre glissante de 12 mois remplace un dénominateur d’année civile : un établissement dont la seule déclaration tombait en début d’année civile était auparavant son propre dénominateur (pc ≈ 1,0) et se trouvait signalé à tort.
Exemple:
Facility XYZ, Indicator: anc1Monthly counts (Jun 2023 – May 2024): Jun Jul Aug Sep Oct Nov Dec Jan Feb Mar Apr May 15 18 12 16 14 17 13 16 15 14 12 890
For May 2024 (count=890):window_total = 15+18+12+16+14+17+13+16+15+14+12+890 = 1052pc = 890 / 1052 = 0.8460.846 > 0.8 AND 890 > 100, therefore outlier_flag = 1Points de repère sur le rapport de cohérence
Le module applique des repères définis par programme pour les paires d’indicateurs :
Coherence CPN:
$$ \text{CPN Consistency} = \begin{cases} 1, & \frac{\text{CPN1 Volume}}{\text{CPN4 Volume}} \geq 0.95 \N - 0, & \text{otherm}} - \N - \N - 0 0, & \text{autre} \NFin{cases} $$
Interprétation : Plus de femmes devraient commencer la CPN (CPN1) que terminer les quatre visites (CPN4). Le ratio devrait être ≥ 0,95, avec une tolerance de 5 % pour les variations de données.
Coherence Penta:
$$ \text{Penta Consistency} = \begin{cases} 1, & \frac{\text{Penta1 Volume}}{\text{Penta3 Volume}} \geq 0.95 \N- \N- \N- \N- \N- \N- 0 0, & \text{autre} \N-END{cases} $$
Interprétation : Plus d’enfants devraient recevoir Penta1 que de compléter la série de trois doses (Penta3).
BCG/Cohérence d’administration:
$$ \text{BCG/Coherence d’administration} = \begin{cases} 1, & 0.7 \leq \frac{\text{BCG Volume}}{\text{Delivery Volume}} \leq 1.3 \N- \N- \N- \N 0, & \text{autre} \N-END{cases} $$
Interprétation : Le BCG est un vaccin administré à la naissance, de sorte que le nombre de vaccinations par le BCG devrait être à peu près égal au nombre d’accouchements dans les établissements. La fourchette plus large (±30%) tient compte des nourrissons nés ailleurs qui reçoivent le BCG dans l’établissement ou des nourrissons nés dans l’établissement qui reçoivent le BCG ailleurs.
Détail de la mise en œuvre:
La cohérence est évaluée au niveau du district/de l’arrondissement (spécifié par GEOLEVEL) pour tenir compte des patients qui se rendent dans plusieurs établissements de leur région pour différents services.
Calcul de l'exhaustivité
Pour un indicateur donné au cours d’un mois donné :
$$ \text{Complétude} = \frac{\text{Nombre d’installations déclarantes}}{\text{Nombre d’installations prévues}} \n- fois 100 $$
Définition des établissements attendus: Un établissement est censé déclarer un indicateur s’il a déjà déclaré cet indicateur au cours de la période d’analyse ET s’il n’est pas considéré comme inactif.
Définition d’une installation inactive: Une installation est considérée comme inactive lorsqu’elle n’a pas fait de déclaration pendant au moins six mois consécutifs avant sa première déclaration ou après sa dernière déclaration.
Exemple:
District has 20 facilities that have ever reported penta1 data in 2024In March 2024:- 18 facilities submitted penta1 data- 2 facilities did not submit (but are not inactive)
Completeness = 18 / 20 × 100 = 90%Note importante : Un niveau élevé d’exhaustivité n’indique pas nécessairement que le SIGS est représentatif de l’ensemble de la prestation de services dans le pays, car certains services peuvent ne pas être fournis dans les établissements ou certains établissements peuvent ne pas faire de déclaration. Pour les pays où le DHIS2 ne stocke pas les zéros, l’exhaustivité de l’indicateur peut être sous-estimée s’il y a beaucoup d’établissements à faible volume.
Calcul du score composite de l'EQD
Le score de l’EQD combine trois dimensions de la qualité pour un ensemble défini d’indicateurs de base.
Scores des composantes:
1. Score d’exhaustivité et d’aberration:
$$ \text{Score d’exhaustivité et de valeur aberrante} = \frac{\sum (\text{réussite de l’exhaustivité} + \text{réussite de la valeur aberrante})}{2 \text{nombre d’indicateurs EQD}} $$
2. Score de cohérence:
$$ \text{Score de cohérence} = \frac{\text{Nombre de paires ayant réussi les tests}}{\text{Nombre de paires disponibles}} $$
3. Score moyen de l’EQD:
$$ \text{Moyenne EQD} = \frac{\text{Score d’exhaustivité et de valeurs aberrantes} + \text{Score de cohérence}}{2} $$
4. Score EQD binaire:
$$ \texte{score EQD} = \begin{cases} 1, & \text{si toutes les vérifications sont réussies (complètes, pas de valeurs aberrantes, cohérentes)} \\n- \r} 0, & \text{si une vérification échoue} \NFin{cases} $$
Critères de réussite pour un score binaire:
- TOUS les indicateurs de l’EQD doivent être complets (completeness_flag = 1)
- TOUS les indicateurs du EQD doivent être exempts de valeurs aberrantes (outlier_flag = 0)
- TOUTES les paires de cohérence disponibles doivent satisfaire aux critères de référence (sconsistency = 1)
Exemple de calcul:
Facility 123, Period 202403DQA Indicators: penta1, anc1, opd
Completeness: penta1=1, anc1=1, opd=1 → 3 pointsOutliers: penta1=0, anc1=0, opd=0 → 3 pointsCompleteness-Outlier Score = 6 / (2×3) = 1.0
Consistency Pairs:- pair_penta: 1 (pass)- pair_anc: 1 (pass)Consistency Score = 2 / 2 = 1.0
DQA Mean = (1.0 + 1.0) / 2 = 1.0DQA Score = 1 (all checks passed)Exemples de code
Section intitulée « Exemples de code »Exemple 1 : Exécution du module avec les paramètres par défaut
# Set working directorysetwd("/path/to/module/directory")
# Load required librarieslibrary(zoo)library(stringr)library(dplyr)library(tidyr)library(data.table)
# The module will automatically:# 1. Load hmis_ISO3.csv# 2. Run all analyses with default parameters# 3. Generate output CSV files in the working directory
source("01_module_data_quality_assessment.R")Exemple 2 : Ajuster la sensibilité de la détection des valeurs aberrantes
# Make outlier detection more sensitive (lower thresholds)OUTLIER_PROPORTION_THRESHOLD <- 0.6 # Flag if >60% of trailing 12-month volume (was 80%)MINIMUM_COUNT_THRESHOLD <- 50 # Consider counts >=50 (was 100)MADS <- 8 # Flag at 8 MADs (was 10)
# Run the modulesource("01_module_data_quality_assessment.R")Cas d’utilisation : Pays avec des volumes de services généralement faibles où les seuils par défaut sont trop conservateurs.
Exemple 3 : Niveau géographique différent pour plus de cohérence
# Use district level (admin_area_2) instead of sub-district (admin_area_3)GEOLEVEL <- "admin_area_2"
# This affects consistency analysis aggregation levelsource("01_module_data_quality_assessment.R")Cas d’utilisation : Le niveau du sous-district présente des données éparses ou trop peu d’installations par zone, ce qui rend l’agrégation au niveau du district plus stable.
Exemple 4 : indicateurs EQD personnalisés
# Focus DQA on maternal health indicators onlyDQA_INDICATORS <- c("anc1", "anc4", "delivery", "pnc1")
# Only evaluate anc consistency pairCONSISTENCY_PAIRS_USED <- c("anc")
source("01_module_data_quality_assessment.R")Cas d’utilisation : Analyse spécialisée portant sur un domaine de service spécifique.
Exemple 5 : Se présenter dans un autre pays
# Configure for your countryCOUNTRY_ISO3 <- "ISO3" # Replace with your country codePROJECT_DATA_HMIS <- "hmis_ISO3.csv"GEOLEVEL <- "admin_area_3"
# Adjust for country-specific indicators if neededDQA_INDICATORS <- c("penta1", "anc1", "opd", "fp_new")
source("01_module_data_quality_assessment.R")Exemple 6 : Utilisation programmatique des sorties
# After running the module, work with outputs
# Load DQA resultsdqa_results <- read.csv("M1_output_dqa.csv")
# Filter to high-quality facility-months onlyhigh_quality <- dqa_results %>% filter(dqa_score == 1)
# Calculate percentage of facility-months passing DQA by districtquality_by_district <- dqa_results %>% group_by(admin_area_2, period_id) %>% summarize( total_facility_months = n(), passing_quality = sum(dqa_score == 1), pct_passing = 100 * passing_quality / total_facility_months )
# Identify facilities with consistently poor quality (never passing)poor_quality_facilities <- dqa_results %>% group_by(facility_id) %>% summarize( months_analyzed = n(), months_passed = sum(dqa_score == 1), pct_passed = 100 * months_passed / months_analyzed ) %>% filter(pct_passed == 0)Dépannage
Section intitulée « Dépannage »Problème : Le module saute l'analyse de cohérence
Symptômes:
- Message de la console : “Aucune paire de cohérence valide n’a été trouvée”
- M1_output_consistency_geo.csv n’a que des en-têtes
- Les scores du EQD sont calculés sans la composante de cohérence
Diagnostic: Vérifiez que les deux indicateurs de chaque paire existent dans votre jeu de données :
# Load your datadata <- read.csv("hmis_[COUNTRY].csv")
# Check available indicateursprint(unique(data$indicator_common_id))
# Compare with required pairs# For pair_penta: need "penta1" and "penta3"# For pair_anc: need "anc1" and "anc4"# For pair_delivery: need "bcg" and "delivery" (or "sba")Solutions:
- Ajuster
CONSISTENCY_PAIRS_USEDpour n’inclure que les paires dont les indicateurs sont disponibles - Modifiez les noms des indicateurs dans vos données pour qu’ils correspondent aux noms attendus
- Accepter que l’EQD soit calculé sans la composante de cohérence
Problème : toutes les installations sont considérées comme aberrantes
Symptômes:
- Pourcentage très élevé de outlier_flag = 1 dans M1_output_outliers.csv
- La plupart des observations dans outlier_list.csv
Diagnostic: Vos seuils sont peut-être trop sensibles pour le contexte de vos données.
Solutions:
- Augmenter le seuil de MAD :
MADS <- 15 # Increase from default 10- Augmenter le seuil de proportion :
OUTLIER_PROPORTION_THRESHOLD <- 0.9 # Increase from 0.8- Augmenter le seuil de comptage minimum (se concentrer sur les grandes installations) :
MINIMUM_COUNT_THRESHOLD <- 200 # Increase from 100- Examiner les données : Vérifier s’il existe de véritables problèmes de qualité nécessitant un nettoyage des données plutôt qu’un ajustement des paramètres
Problème : aucun résultat de l'EQD n'a été généré
Symptômes:
- M1_output_dqa.csv est vide ou ne contient que des en-têtes
- Message de la console : “Sauter l’analyse EQD - aucun des indicateurs requis n’a été trouvé”
Diagnostic:
Aucun des indicateurs spécifiés dans DQA_INDICATORS n’existe dans votre jeu de données.
Solution: Vérifiez quels indicateurs de l’EQD sont manquants :
# Load datadata <- read.csv("hmis_[COUNTRY].csv")
# Check which DQA indicators are missingavailable_indicators <- unique(data$indicator_common_id)missing_indicators <- setdiff(DQA_INDICATORS, available_indicators)print(paste("Missing DQA indicators:", paste(missing_indicators, collapse=", ")))
# Available DQA indicatorsavailable_dqa <- intersect(DQA_INDICATORS, available_indicators)print(paste("Available DQA indicators:", paste(available_dqa, collapse=", ")))Puis mettez à jour DQA_INDICATORS pour n’inclure que les indicateurs disponibles :
DQA_INDICATORS <- c("penta1", "anc1") # Only use what's availableProblème : les ratios de cohérence semblent incorrects
Symptômes:
- Tous les indicateurs de cohérence sont à 0 (incohérent)
- Les taux de cohérence sont étonnamment élevés ou bas
Diagnostic: Le niveau d’agrégation géographique n’est peut-être pas adapté à vos données.
Investigation:
# Load geographic consistency resultsgeo_cons <- read.csv("M1_output_consistency_geo.csv")
# Check distribution of consistency ratiossummary(geo_cons$consistency_ratio)
# Check sample sizes at geographic leveloutliers <- read.csv("M1_output_outliers.csv")geo_summary <- outliers %>% group_by(admin_area_3, period_id) %>% summarize( n_facilities = n_distinct(facility_id), total_volume = sum(count, na.rm = TRUE) )summary(geo_summary$n_facilities)Solutions:
- Si les zones géographiques ont très peu d’installations (1-2), utiliser le niveau supérieur :
GEOLEVEL <- "admin_area_2" # Use district instead of sub-district-
Si les ratios sont généralement inférieurs à 0,95 pour les paires CPN/Penta, cela peut indiquer de véritables problèmes programmatiques (taux d’abandon élevé) plutôt que des problèmes de qualité des données
-
Examinez les fourchettes de référence de cohérence - elles peuvent nécessiter un ajustement à votre contexte :
# Example: Allow higher dropout (lower ratio) for Pentaall_consistency_ranges$pair_penta <- c(lower = 0.85, upper = Inf)Problème : les pourcentages d'exhaustivité semblent faibles
Symptômes:
- Proportion élevée de completeness_flag = 0 dans M1_output_completeness.csv
Diagnostic: Il peut s’agir d’un problème légitime (mauvais rapport) ou d’un artefact lié à la façon dont votre DHIS2 stocke les valeurs nulles.
Investigation:
# Load completeness datacompleteness <- read.csv("M1_output_completeness.csv")
# Check pattern: Are there explicit zeros or just missing values?outliers <- read.csv("M1_output_outliers.csv")table(is.na(outliers$count), outliers$count == 0)
# Check completeness by indicatorcomp_by_indicator <- completeness %>% group_by(indicator_common_id) %>% summarize( pct_complete = 100 * mean(completeness_flag == 1), pct_incomplete = 100 * mean(completeness_flag == 0) )print(comp_by_indicator)Considérations:
- Si votre DHIS2 ne stocke pas les zéros, les établissements à faible volume peuvent apparaître incomplets alors qu’ils n’avaient légitimement pas de services à déclarer
- Les pourcentages d’exhaustivité doivent être interprétés dans leur contexte - un taux d’exhaustivité de 70 % peut être acceptable en fonction du système de santé
- Utiliser le drapeau completeness_flag dans les modules suivants pour pondérer les estimations de manière appropriée
Problème : erreur de lecture du fichier d'entrée
Symptômes:
- Erreur : “Impossible d’ouvrir le fichier ‘hmis_[COUNTRY].csv’”
- Le module se bloque pendant le chargement des données
Solutions:
- Vérifier le chemin d’accès au fichier et le répertoire de travail :
getwd() # Verify working directorylist.files() # Check if SIGS file is present-
Vérifier que le nom du fichier correspond au paramètre
PROJECT_DATA_HMIS -
Vérifier le format du fichier (CSV, encodage correct, séparé par des virgules)
-
S’assurer que les colonnes requises existent :
# After loadingnames(data) # Should include: facility_id, period_id, indicator_common_id, countNotes d’utilisation
Section intitulée « Notes d’utilisation »Gestion des types de données
period_id Flexibilité:
Le module accepte period_id dans plusieurs formats :
- Entier :
202401 - Chaîne :
"202401" - Numérique :
202401.0
Tous les formats sont convertis en interne en objets Date afin de respecter l’ordre chronologique :
# Internal conversionas.Date(sprintf("%04d-%02d-01", year, month))Cela permet de garantir un ordre temporel correct, même en cas d’interruption des périodes de déclaration.
Valeurs de comptage:
- Valeurs numériques requises (entiers ou décimales)
- Les dénombrements nuls doivent être explicites
0, et nonNA - Les dénombrements manquants sont représentés par des
NAou des lignes manquantes
Colonnes géographiques:
- Type de caractère recommandé
- Peut contenir des espaces et des caractères spéciaux
- Sensible à la casse dans certaines opérations
Stratégie des valeurs manquantes
Le module utilise des approches spécifiques au contexte pour les valeurs manquantes :
Analyse des valeurs aberrantes:
- Les valeurs NA sont exclues des calculs de la médiane/MAD
- Seules les valeurs non NA contribuent aux statistiques
- Évite les biais dus à la rareté des données
Complétude:
- La mention explicite NA dans la colonne des effectifs indique que les données n’ont pas été déclarées
- Indicateur de complétude = 0 (incomplet)
- Distinction avec les périodes inactives (drapeau = 2, supprimé)
Cohérence:
- Les ratios NA (issus de la division par zéro) sont conservés en tant que NA et ne sont pas convertis en 0
- Les paires NA sont exclues du dénominateur de l’évaluation de la cohérence
- Évite de pénaliser les établissements pour des indicateurs non disponibles
Notation de l’EQD:
- Paires de cohérence NA exclues du dénominateur
- Seules les paires disponibles affectent le score de cohérence
- Permet une notation partielle lorsque certains indicateurs sont manquants
Considérations sur la mémoire
Pour les grands ensembles de données (>1 million de lignes), le module met en œuvre plusieurs optimisations :
data.table Utilisation:
- Le traitement de complétude utilise
data.tablepour les opérations in-place - Beaucoup plus rapide et plus efficace en termes de mémoire que
dplyrpour les données volumineuses
**Stratégie de filtrage
- Filtre les indicateurs pertinents avant les opérations coûteuses
- Réduit l’empreinte mémoire pendant les calculs
Gestion des objets:
- Supprime les objets intermédiaires après utilisation
- Empêche l’accumulation de mémoire pendant le traitement séquentiel
Recommandations pour les grands ensembles de données:
- Allouer au moins 8 Go de RAM pour les pays comptant plus de 1 000 établissements
- Envisager un traitement par année si les ensembles de données pluriannuels posent des problèmes de mémoire
- Surveillez l’utilisation de la mémoire :
pryr::mem_used()à différentes étapes
Opportunités d'optimisation des performances
Mise en œuvre actuelle:
L’analyse de complétude traite les indicateurs séquentiellement en utilisant lapply().
Amélioration potentielle: Pour les ensembles de données comportant de nombreux indicateurs, la parallélisation pourrait améliorer les performances :
# Future enhancement (not in current code)library(parallel)
# Detect available coresn_cores <- detectCores() - 1
# Parallel processing of indicateurscompleteness_list <- mclapply( unique(outlier_data_main$indicator_common_id), function(ind) generate_full_series_per_indicator( outlier_data = outlier_data_main, indicator_id = ind, timeframe = indicateur_timeframe ), mc.cores = n_cores)
# Combine resultscompleteness_data <- rbindlist(completeness_list)Accélération attendue:
- 3-4x plus rapide avec 4 cœurs sur des ensembles de données avec 10+ indicateurs
- Plus avantageux pour les pays avec de nombreux indicateurs et de longues séries temporelles
Sélection dynamique d'indicateurs
Le module s’adapte intelligemment aux données disponibles :
Sélection de l’indicateur de livraison:
# Prefer 'delivery' if available, otherwise fall back to 'sba'available_indicators <- unique(data$indicator_common_id)delivery_indicator <- if ("delivery" %in% available_indicators) { "delivery"} else if ("sba" %in% available_indicators) { "sba"} else { NULL # No delivery indicator available}Validation de l’indicateur EQD:
# Only use DQA indicators that exist in the datasetdqa_indicators_to_use <- intersect(DQA_INDICATORS, unique(data$indicator_common_id))
# If none found, skip DQA analysis with informative messageif (length(dqa_indicators_to_use) == 0) { print("Skipping DQA analysis - none of the required indicators found")}Validation des paires de cohérence: Le module vérifie chaque paire de cohérence et supprime celles qui ont des indicateurs manquants, en fournissant des avertissements clairs sur les paires qui ont été ignorées.
Gestion des erreurs et solutions de repli
Le module inclut une gestion robuste des erreurs :
Paires de cohérence manquantes:
- S’il n’existe pas de paires valides, l’analyse de cohérence est ignorée
- Utilise
dqa_without_consistency()pour la notation - Produit des fichiers fictifs avec les en-têtes appropriés
Niveaux géographiques manquants:
- Se rabat sur le plus bas niveau d’administration disponible si le
GEOLEVELspécifié n’est pas trouvé - Emet un avertissement à propos de la solution de repli
Résultats vides:
- Crée des fichiers CSV avec les en-têtes appropriés même s’il n’y a pas de données
- Assure que les processus en aval ne sont pas interrompus
Indicateurs manquants:
- Valide toutes les exigences en matière d’indicateurs avant l’analyse
- Avertit des paires supprimées
- Continue avec les indicateurs disponibles
Directives d'interprétation
outlier flags:
- outlier_flag = 1 suggère des problèmes potentiels de qualité des données, mais nécessite une investigation
- Toutes les valeurs aberrantes signalées ne sont pas des erreurs (de véritables campagnes de services peuvent déclencher des drapeaux)
- Utiliser les valeurs mad_residual et pc pour prioriser l’examen
Complétude:
- Le pourcentage d’exhaustivité varie selon le contexte du système de santé
- 80-90%+ est généralement bon, mais dépend du pays
- L’évolution dans le temps est plus instructive que le pourcentage absolu
- Un faible taux d’exhaustivité pour des indicateurs spécifiques peut refléter de véritables lacunes dans les services
Cohérence:
- la cohérence = 0 peut indiquer des problèmes de qualité des données OU des problèmes de performance programmatique (par exemple, un taux d’abandon élevé)
- L’interprétation nécessite des connaissances programmatiques
- Les schémas géographiques peuvent aider à distinguer les problèmes systématiques des erreurs aléatoires
Scores EQD:
- dqa_score = 1 indique que les données ont passé toutes les vérifications, et qu’elles peuvent être utilisées sans ajustement
- dqa_score = 0 nécessite un examen plus approfondi
- dqa_mean fournit une vision nuancée (0,75 = plutôt bon, 0,25 = plutôt mauvais)
Résumé des mesures de qualité des données
Section intitulée « Résumé des mesures de qualité des données »| Métrique | Type | Intervalle | Interprétation |
|---|---|---|---|
| outlier_flag | Binaire | 0 ou 1 | 1 = Valeur aberrante détectée par l’une ou l’autre des méthodes (MAD ou proportionnelle) ET compte > 100 |
| outlier_mad | Binaire | 0 ou 1 | 1 = Valeur aberrante statistique (basée sur MAD) |
| outlier_pc | Binaire | 0 ou 1 | 1 = Valeur aberrante proportionnelle (>80% du volume des 12 mois glissants) |
| mad_residual | Continu | 0 à ∞ | Écart standardisé par rapport à la médiane (plus élevé = plus extrême) |
| pc | Continu | 0 à 1 | Proportion du volume des 12 mois glissants se terminant à cette période (plus proche de 1 = plus concentré) |
| completeness_flag | Catégorique | 0, 1, 2 | 0=Incomplet (manquant), 1=Complet (rapporté), 2=Inactif (supprimé) |
| sconsistency | Binaire | 0, 1, NA | 1=Cohérent (réussit le test), 0=Incohérent, NA=Impossible à calculer |
| consistency_ratio | Continu | 0 à ∞ | Rapport d’indicateurs appariés (l’interprétation dépend de l’appairage) |
| completeness_outlier_score | Continu | 0 à 1 | Proportion d’indicateurs EQD passant les contrôles de complétude et de valeurs aberrantes |
| consistency_score | Continu | 0 à 1 | Proportion de paires de cohérence passant les tests de référence |
| dqa_mean | Continu | 0 à 1 | Moyenne des scores des composants (mesure globale de la qualité) |
| dqa_score | Binaire | 0 ou 1 | 1 = Toutes les vérifications réussies ; 0 = au moins une vérification échouée |
Flux de travail d’exécution
Section intitulée « Flux de travail d’exécution »Le module suit la séquence suivante :
1. DATA LOADING & PREPROCESSING ├─ Load SIGS CSV file ├─ Convert period_id to dates ├─ Detect geographic columns └─ Create composite malaria indicateur (if applicable)
2. CONFIGURATION & VALIDATION ├─ Detect available indicateurs ├─ Dynamically select delivery indicateur (delivery vs sba) ├─ Build consistency pairs based on available indicateurs ├─ Validate consistency pairs └─ Filter DQA indicateurs to available ones
3. OUTLIER ANALYSIS ├─ Calculate median and MAD by établissement-indicateur ├─ Flag MAD-based valeurs aberrantes (>10 MADs from median) ├─ Flag proportion-based valeurs aberrantes (>80% of trailing 12-month volume) └─ Combine flags (either method + count > 100)
4. COMPLETENESS ANALYSIS ├─ Identify reporting timeframe per indicateur ├─ Generate full time series (all facilities × all months) ├─ Tag reporting status (complete/incomplete/inactive) └─ Remove inactive periods (6+ months before first/after last report)
5. CONSISTENCY ANALYSIS (if applicable) ├─ Exclude valeurs aberrantes from data ├─ Aggregate to geographic level (e.g., district) ├─ Calculate ratios for indicateur pairs ├─ Flag consistency based on predefined ranges ├─ Expand geo-level results to facilities └─ Pivot to wide format (one column per pair)
6. DQA SCORING ├─ Filter to DQA indicateurs only ├─ Merge completeness, outlier, and consistency results ├─ Calculate component scores: │ ├─ completeness-outlier score (0-1) │ └─ Consistency score (0-1, if applicable) ├─ Calculate mean DQA score └─ Assign binary DQA pass/fail flag
7. EXPORT RESULTS ├─ M1_output_outlier_list.csv (valeurs aberrantes only) ├─ M1_output_outliers.csv (all records with flags) ├─ M1_output_completeness.csv (completeness flags) ├─ M1_output_consistency_geo.csv (geo-level consistency) └─ M1_output_dqa.csv (final DQA scores)Dernière mise à jour : 06-05-2026 Contact : fastr@worldbank.org