Ajustement de la qualité des données
Contexte et objectif
Section intitulée « Contexte et objectif »Objectif du module
Section intitulée « Objectif du module »Le module d’ajustement de la qualité des données s’attaque à deux limitations courantes des données de routine des établissements de santé : les valeurs extrêmes résultant d’erreurs de déclaration ou de saisie des données (valeurs aberrantes) et les lacunes résultant d’une déclaration incomplète (données manquantes). Plutôt que d’exclure les observations concernées, le module remplace ces valeurs par des estimations statistiquement dérivées, fondées sur les modèles de déclaration historiques de chaque établissement.
Le processus d’ajustement applique des méthodes de lissage des séries temporelles qui s’appuient sur les tendances et la saisonnalité observées dans les données au niveau de l’établissement. Les moyennes mobiles et les profils historiques spécifiques à l’établissement sont utilisés pour corriger les valeurs anormales tout en préservant les modèles de prestation de services sous-jacents.
Pour favoriser la transparence et la flexibilité analytique, le module génère quatre ensembles de données parallèles : données non ajustées, données avec corrections des valeurs aberrantes uniquement, données avec imputation des valeurs manquantes uniquement, et données avec les deux ajustements appliqués. Cela permet aux utilisateurs d’évaluer la sensibilité des résultats aux différentes hypothèses de qualité des données et de sélectionner l’ensemble de données le plus approprié à leur objectif analytique.
Raison d’être de l’analyse
Section intitulée « Raison d’être de l’analyse »Les données du système d’information sur la gestion de la santé (SIGS) contiennent souvent des erreurs de déclaration et des lacunes qui peuvent fausser les tendances observées et masquer les schémas sous-jacents de la prestation de services. Les valeurs extrêmes peuvent créer des pics artificiels dans les volumes de services, tandis que les rapports incomplets peuvent entraîner des baisses apparentes qui reflètent des problèmes de qualité des données plutôt que de véritables changements dans la prestation de services. Ces limites sont particulièrement importantes lorsque les données SIGS sont utilisées pour le suivi des performances, la comparaison entre les unités géographiques ou l’analyse des tendances.
En traitant systématiquement les valeurs aberrantes et les données manquantes avant l’analyse, ce module améliore la cohérence et l’interprétabilité des données SIGS. Cela permet de s’assurer que les résultats analytiques ultérieurs sont basés sur des modèles de prestation de services observés plutôt que sur des artefacts introduits par la variabilité des rapports ou les contraintes liées à la qualité des données.
Points clés
Section intitulée « Points clés »| Composante | Détails |
|---|---|
| Entrées | Données brutes du SIGS (hmis_ISO3.csv)Indicateurs de valeurs aberrantes du module 1 ( M1_output_outliers.csv)Indicateurs d’exhaustivité du module 1 ( M1_output_completeness.csv) |
| Sorties | Données ajustées au niveau de l’établissement (M2_adjusted_data.csv)Données agrégées sous-nationales ( M2_adjusted_data_admin_area.csv)Données agrégées nationales ( M2_adjusted_data_national.csv)Métadonnées d’exclusion ( M2_low_volume_exclusions.csv) |
| Objectif | Remplacer les valeurs aberrantes et compléter les données manquantes à l’aide de modèles historiques spécifiques à l’établissement ; quatre scénarios d’ajustement sont produits (aucun, valeurs aberrantes uniquement, exhaustivité uniquement, les deux) |
Flux de travail analytique
Section intitulée « Flux de travail analytique »Aperçu des étapes analytiques
Section intitulée « Aperçu des étapes analytiques »Le module applique un processus standardisé en plusieurs étapes pour ajuster les données de routine des établissements de santé tout en préservant les modèles de prestation de services sous-jacents :
Étape 1 : Chargement et préparation des données
Le module intègre trois entrées : les volumes de services déclarés au niveau de l’établissement (hmis_ISO3.csv), les indicateurs de valeurs aberrantes identifiant les valeurs anormales (M1_output_outliers.csv du module 1) et les indicateurs de complétude indiquant les mois pour lesquels la déclaration est incomplète (M1_output_completeness.csv du module 1). Les indicateurs pour lesquels l’ajustement n’est pas approprié (tout indicateur dont le nom contient death ou still_birth, sans tenir compte de la casse) sont identifiés et exclus des étapes d’ajustement ultérieures.
Étape 2 : Identifier les indicateurs à faible volume
Avant d’appliquer tout ajustement, chaque indicateur est évalué pour s’assurer qu’il présente un volume suffisant. Les indicateurs qui n’atteignent jamais 100 événements déclarés au cours d’un mois donné sur l’ensemble de la série chronologique (count >= 100) sont signalés et exclus de l’ajustement, car les méthodes statistiques de lissage ne sont pas significatives pour les indicateurs à faible volume constant. La liste des indicateurs à faible volume exclus est enregistrée dans M2_low_volume_exclusions.csv.
Étape 3 : Ajuster les valeurs aberrantes Pour les observations signalées comme aberrantes, le module estime les valeurs de remplacement en se basant sur les modèles historiques de déclaration de l’établissement. Un ensemble hiérarchique de méthodes est appliqué séquentiellement :
-
Moyenne mobile centrée sur six mois (trois mois avant et trois mois après)
-
Moyenne mobile prospective sur six mois
-
Moyenne mobile rétrospective sur six mois
-
Même mois civil de l’année précédente
-
Moyenne historique spécifique à l’établissement
Étape 4 : Remplir les données manquantes et incomplètes Pour les mois identifiés comme manquants ou incomplets, les valeurs sont imputées en utilisant le même cadre de moyenne mobile que celui appliqué à l’ajustement des valeurs aberrantes. Cette approche permet d’éviter les chutes artificielles à zéro causées par des lacunes temporaires dans les rapports, tout en maintenant la cohérence avec les tendances spécifiques à l’établissement.
Étape 5 : Créer plusieurs scénarios Pour favoriser la transparence et l’analyse de sensibilité, le module produit quatre ensembles de données parallèles :
-
Données non ajustées (valeurs déclarées originales)
-
Données avec ajustement des valeurs aberrantes uniquement
-
Données avec ajustements pour les données manquantes ou incomplètes uniquement
-
Données faisant l’objet d’ajustements pour les données aberrantes et les données incomplètes
Étape 6 : Agrégation au niveau géographique Après ajustement, les données au niveau de l’établissement sont agrégées aux niveaux sous-national et national. Tous les scénarios d’ajustement sont conservés à chaque niveau géographique, ce qui permet une analyse à différentes échelles administratives.
Étape 7 : Exportation des résultats Le module génère des fichiers de sortie structurés pour les ensembles de données au niveau de l’établissement, au niveau infranational et au niveau national, ainsi qu’un fichier de métadonnées documentant les indicateurs exclus de l’ajustement et les raisons de leur exclusion.
Diagramme de flux de travail
Section intitulée « Diagramme de flux de travail »Points de décision clés
Section intitulée « Points de décision clés »Identification des valeurs sujettes à ajustement
Le module applique des ajustements à deux catégories d’observations :
- Les valeurs signalées comme aberrantes par les procédures de détection statistique mises en œuvre dans le module 1
- Les valeurs correspondant aux mois identifiés comme incomplets ou manquants en raison de lacunes dans les déclarations
Certains indicateurs sont explicitement exclus de l’ajustement :
- Les indicateurs liés à la mortalité et aux mortinaissances (tout
indicator_common_iddont le nom contientdeathoustill_birth, sans tenir compte de la casse — couvrant les décès d’enfants de moins de cinq ans, les décès maternels, les décès néonatals, les mortinaissances, etc.), car ils représentent des événements discrets pour lesquels le lissage ou l’imputation ne sont pas appropriés - Les indicateurs de faible volume qui n’atteignent jamais 100 événements déclarés au cours d’un mois donné, pour lesquels l’ajustement statistique n’est pas significatif
Sélection du scénario d’ajustement
Le module génère quatre scénarios d’ajustement pour tenir compte des différents contextes analytiques et des conditions de qualité des données :
- Pas d’ajustement : Pas d’ajustement** : conserve les valeurs déclarées et convient aux exercices de validation ou aux contextes dans lesquels la qualité des données est jugée élevée
- Ajustement des valeurs extremes uniquement : applique des corrections lorsque des valeurs extremes sont presentes mais que l’exhaustivite de la declaration est par ailleurs stable
- Ajustement de l’exhaustivite uniquement : corrige les lacunes dans la declaration tout en preservant les valeurs declarees dans les periodes ou les donnees sont completes
- Ajustement des valeurs aberrantes et de l’exhaustivite : applique les deux corrections lorsque des limitations de la qualite des donnees sont presentes dans les deux dimensions
Traitement des données et résultats
Section intitulée « Traitement des données et résultats »Structure d’entree Le module recoit les volumes de services mensuels au niveau de l’établissement ainsi que les indicateurs de qualité des données générés dans le module 1, y compris les indicateurs de valeurs aberrantes et l’état d’exhaustivité. Chaque combinaison établissement-indicateur-mois est traitée comme une observation distincte en vue d’un ajustement potentiel.
Application des ajustements Sur la base du scenario selectionne, des comptes de services ajustés sont générés. Les observations signalées comme aberrantes sont remplacées par des valeurs dérivées de moyennes historiques spécifiques à l’établissement, excluant les périodes anormales. Pour les mois où la déclaration est incomplète ou manquante, les valeurs sont imputées à l’aide de modèles historiques au niveau de l’établissement afin de maintenir la continuité de la série temporelle.
Generation d’ensembles de donnees paralleles Quatre versions paralleles des comptes ajustes sont produites : les valeurs non ajustées, les valeurs ajustées pour les valeurs aberrantes, les valeurs ajustées pour l’exhaustivité et les valeurs avec les deux ajustements appliqués. Cette structure permet aux analyses en aval d’évaluer explicitement la sensibilité aux différentes hypothèses de qualité des données.
Structure d’agrégation et de sortie Les données ajustées au niveau de l’établissement sont agrégées au niveau du district, au niveau sous-national et au niveau national, les quatre scénarios d’ajustement étant retenus. Chaque enregistrement de sortie comprend l’unité géographique, l’indicateur, la période de temps et les comptes de services correspondants pour chaque scénario, ce qui permet une analyse flexible des cas d’utilisation et des objectifs analytiques.
Résultats de l’analyse et visualisation
Section intitulée « Résultats de l’analyse et visualisation »L’analyse FASTR génère trois principaux résultats visuels comparant les volumes de services avant et après les ajustements :
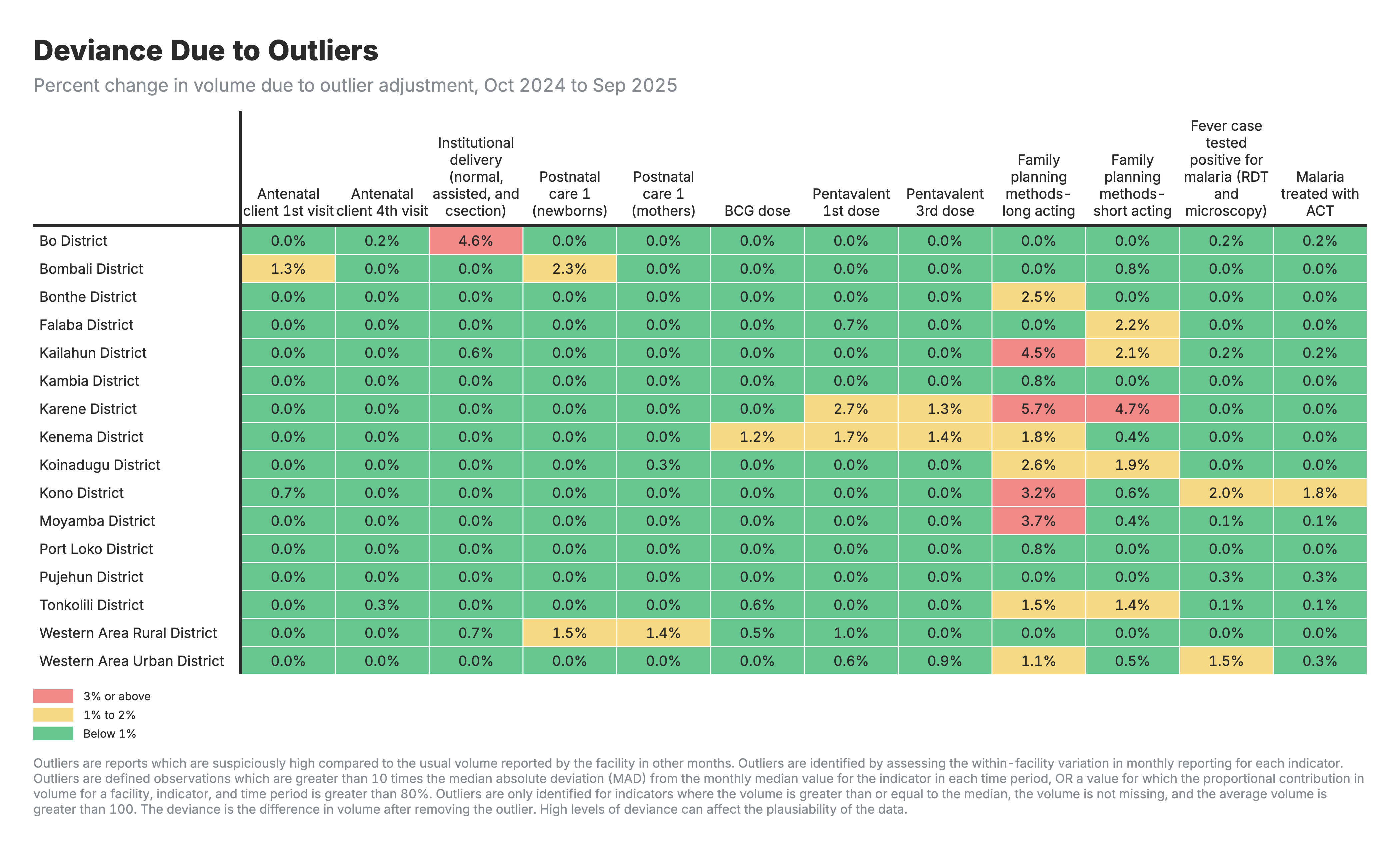
1. Impact de l’ajustement des valeurs aberrantes
Heatmap montrant le pourcentage de changement dans le volume de service dû à l’ajustement des valeurs aberrantes, par indicateur et par zone géographique.
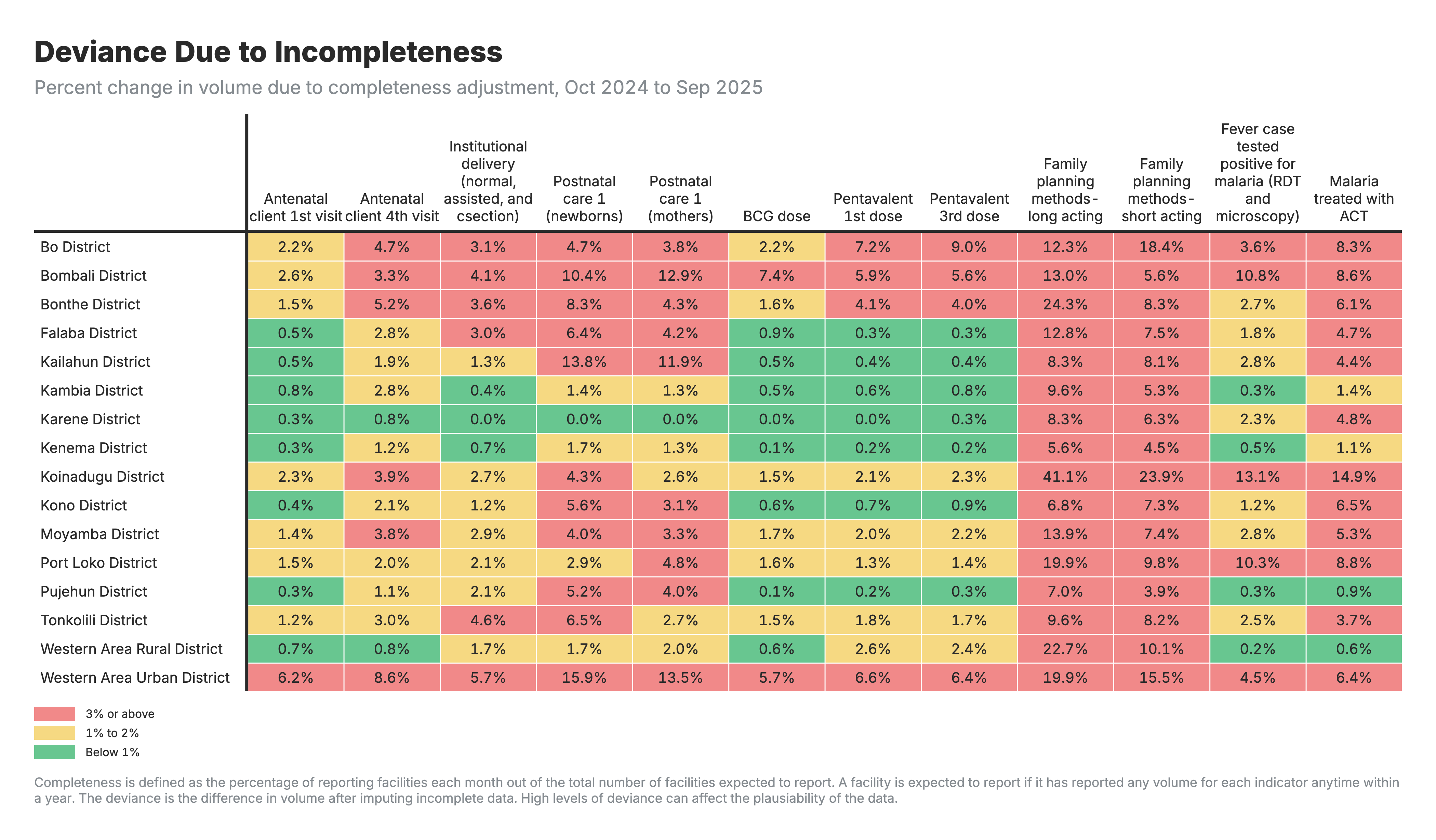
2. Impact de l’ajustement de l’exhaustivité
Heatmap montrant la variation en pourcentage du volume de services due à l’ajustement de l’exhaustivité (données manquantes), par indicateur et par zone géographique.
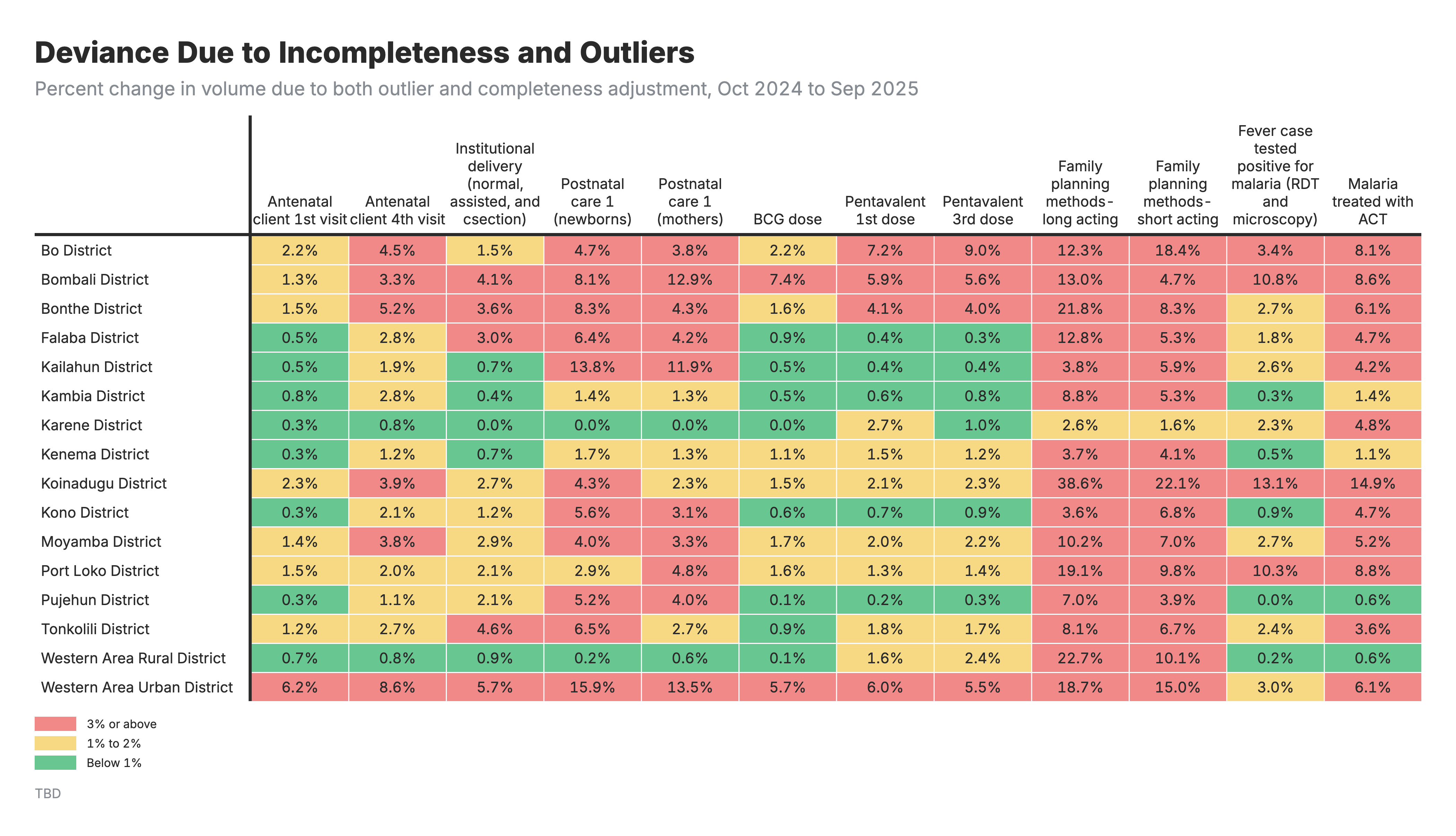
3. Impact de l’ajustement combiné
Heatmap montrant le pourcentage de changement dans le volume de services lorsque les ajustements des valeurs aberrantes et de l’exhaustivité sont appliqués.
Guide d’interpretation
Pour toutes les heatmaps :
- Lignes : Zones géographiques (zones/régions)
- Colonnes : Indicateurs de santé
- Valeurs : Pourcentage de variation du volume de services après ajustement
Pour la heatmap de l’ajustement des valeurs aberrantes (résultat 1) :
- Valeurs négatives : Les valeurs extrêmement élevées ont été remplacées par des estimations plus faibles
- Les valeurs proches de zéro indiquent que peu de valeurs aberrantes ont été détectées
Pour la heatmap des ajustements d’exhaustivité (résultat 2) :
- Valeurs positives : Les données manquantes ont été complétées, ce qui a permis d’augmenter le volume total
- Les valeurs proches de zéro indiquent que la déclaration était déjà complète
Pour la heatmap de l’ajustement combiné (résultat 3) :
- Montre l’effet net des deux ajustements
- Négatif = l’effet des valeurs aberrantes domine ; Positif = l’effet de l’exhaustivité domine
Référence détaillée
Section intitulée « Référence détaillée »Paramètres de configuration
Section intitulée « Paramètres de configuration »Le module m002 n’expose aucun paramètre configurable par l’utilisateur dans la plateforme FASTR — les ajustements s’exécutent avec la même logique interne pour chaque projet. Les paramètres documentés ci-dessous sont codés en dur dans le module et sont décrits ici à des fins de transparence, et non de configuration.
Indicateurs exclus (codé en dur)
Certains indicateurs sont exclus de tous les ajustements en raison de leur caractère sensible. L’exclusion est effectuée via une expression régulière insensible à la casse sur indicator_common_id :
EXCLUDED_PATTERN <- "death|still_birth"Ce motif correspond à tout indicateur dont le nom contient death (par exemple u5_deaths, maternal_deaths, neonatal_deaths) ou still_birth. Pour ces indicateurs, le count brut original est préservé dans toutes les colonnes de scénarios (count_final_none, count_final_outliers, count_final_completeness, count_final_both).
Justification : Les comptes de décès et de mortinaissances ne doivent pas être lissés ou imputés car ils représentent des événements discrets qui peuvent présenter une véritable variation temporelle. Leur ajustement pourrait masquer d’importantes tendances épidémiologiques ou des signaux d’épidémies.
Exclusions de faibles volumes (codé en dur)
Les indicateurs sont également automatiquement exclus des ajustements si aucune observation établissement-mois n’atteint jamais 100 (count >= 100) dans l’ensemble de la base de données. Cela permet d’éviter des ajustements statistiques inutiles sur des indicateurs dont le nombre d’observations est constamment faible. Pour les indicateurs à faible volume exclus, le count brut est préservé dans les quatre colonnes de scénarios, tout comme pour les indicateurs de mortalité/mortinaissance exclus.
Logique d’exclusion :
low_volume_check <- raw_data[, .(has_volume = any(count >= 100, na.rm = TRUE)), by = indicator_common_id]low_volume_check[, low_volume_exclude := !has_volume]LOW_VOLUME_INDICATORS <- low_volume_check[has_volume == FALSE, indicator_common_id]La liste complète (avec un indicateur low_volume_exclude TRUE/FALSE par indicateur) est enregistrée dans M2_low_volume_exclusions.csv pour des raisons de transparence.
Configuration de la fenêtre roulante (codé en dur)
Le module utilise une fenêtre de 6 mois pour toutes les moyennes glissantes. Ce choix permet d’équilibrer :
Avantages :
- Capture les tendances à moyen terme
- Réduit l’impact des fluctuations à court terme
- Suffisamment de points de données pour obtenir des moyennes stables
- Fonctionne bien pour les indicateurs stables et saisonniers
Les compromis :
- Peut ne pas saisir les changements rapides dans la prestation de services
- Risque de lissage excessif en cas de véritables changements programmatiques
- Nécessite au moins 6 observations valides pour une moyenne centrée optimale
Spécifications des entrées/sorties
Section intitulée « Spécifications des entrées/sorties »Fichiers d'entrée
Le module nécessite trois fichiers d’entrée provenant des étapes de traitement précédentes :
| Fichier | Source | Description | Variables clés |
|---|---|---|---|
hmis_ISO3.csv | Données brutes du SIGS | Volumes de services au niveau de l’établissement | facility_id, indicator_common_id, period_id, count, colonnes des zones administratives |
M1_output_outliers.csv | Module 1 | Indicateurs de valeurs aberrantes pour chaque combinaison établissement-mois-indicateur | facility_id, indicator_common_id, period_id, outlier_flag |
M1_output_completeness.csv | Module 1 | Indicateurs d’exhaustivité pour chaque combinaison établissement-mois-indicateur | facility_id, indicator_common_id, period_id, completeness_flag |
Structure des données d'entrée
Données brutes SIGS (hmis_ISO3.csv) :
facility_id | admin_area_1 | admin_area_2 | admin_area_3 | period_id | indicator_common_id | count------------|--------------|--------------|--------------|-----------|---------------------|-------FAC001 | ISO3 | Province_A | District_A | 202301 | anc1 | 145FAC001 | ISO3 | Province_A | District_A | 202302 | anc1 | 152FAC001 | ISO3 | Province_A | District_A | 202303 | anc1 | 890 # outlierDrapeaux de valeurs aberrantes (M1_output_outliers.csv) :
facility_id | indicator_common_id | period_id | outlier_flag------------|---------------------|-----------|-------------FAC001 | anc1 | 202301 | 0FAC001 | anc1 | 202302 | 0FAC001 | anc1 | 202303 | 1 # Flagged as outlierDrapeaux de complétude (M1_output_completeness.csv) :
facility_id | indicator_common_id | period_id | completeness_flag------------|---------------------|-----------|------------------FAC001 | anc1 | 202301 | 1 # CompleteFAC001 | anc1 | 202302 | 0 # IncompleteFAC001 | anc1 | 202303 | 1 # CompleteFichiers de sortie
Le module génère quatre fichiers de sortie :
| Fichier | Niveau | Description | Colonnes clés |
|---|---|---|---|
M2_adjusted_data.csv | Établissement | Volumes ajustés pour tous les scénarios au niveau de l’établissement | facility_id, zones administratives (excl. admin_area_1), period_id, indicator_common_id, count_final_* |
M2_adjusted_data_admin_area.csv | Sous-national | Volumes ajustés agrégés dans les zones administratives sous-nationales | Zones administratives (excl. admin_area_1), period_id, indicator_common_id, count_final_* |
M2_adjusted_data_national.csv | National | Volumes ajustés agrégés au niveau national | admin_area_1, period_id, indicator_common_id, count_final_* |
M2_low_volume_exclusions.csv | Métadonnées | Indicateurs exclus de l’ajustement en raison de la faiblesse des volumes | indicator_common_id, low_volume_exclude |
Structure des données de sortie
Sorties au niveau de l’établissement (M2_adjusted_data.csv) :
facility_id | admin_area_2 | admin_area_3 | period_id | indicator_common_id | count_final_none | count_final_outliers | count_final_completeness | count_final_both------------|--------------|--------------|-----------|---------------------|------------------|----------------------|--------------------------|------------------FAC001 | Province_A | District_A | 202301 | anc1 | 145 | 145 | 145 | 145FAC001 | Province_A | District_A | 202302 | anc1 | 152 | 152 | 148 | 148FAC001 | Province_A | District_A | 202303 | anc1 | 890 | 148 | 890 | 148Chaque colonne count_final_* représente un scénario d’ajustement différent :
count_final_none: Aucun ajustement n’est appliqué (valeurs originales)count_final_outliers: Seul l’ajustement des valeurs aberrantes est appliquécount_final_completeness: Seul l’ajustement d’exhaustivité est appliquécount_final_both: Ajustement des valeurs aberrantes et de l’exhaustivité appliqués
Documentation sur les fonctions clés
Section intitulée « Documentation sur les fonctions clés »Bibliothèques requises
Le module dépend des paquets R suivants :
data.table- Manipulation, agrégation de données haute performance, et calculs de fenêtres glissantes (frollmeanpour les moyennes glissantes)zoo- Chargé pour les utilitaires de séries temporelleslubridate- Traitement des dates (month(),year()) utilisé pour le repli même-mois-année-précédente
1. `apply_adjustments()`
Fonction de base qui met en œuvre la logique d’ajustement pour un scénario unique.
Objectif :
Remplace les valeurs aberrantes et/ou incomplètes en utilisant des moyennes mobiles et des modèles historiques.
Paramètres :
raw_data(data.table) : Données SIGS originales avec comptage des servicescompleteness_data(data.table) : Indicateurs d’exhaustivité du module 1outlier_data(data.table) : Indicateurs de valeurs aberrantes du module 1adjust_outliers(logique) : Application ou non de l’ajustement des valeurs aberrantesadjust_completeness(logique) : Appliquer ou non l’ajustement de l’exhaustivité
Retourne :
data.table avec les valeurs ajustées dans la colonne count_working et les métadonnées d’ajustement
Opérations clés :
- Fusionne les ensembles de données d’entrée par
facility_id,indicator_common_id, etperiod_id - Convertit les
period_iden dates pour l’ordonnancement temporel - Calcule les moyennes glissantes (centrées, en avant, en arrière) pour les valeurs valides
- Applique une hiérarchie d’ajustement basée sur la disponibilité des données
- Suivi de la méthode d’ajustement utilisée pour chaque valeur remplacée
2. `apply_adjustments_scenarios()`
Fonction enveloppante qui exécute les ajustements dans les quatre scénarios.
Objectif :
Appliquer la logique d’ajustement selon différentes combinaisons d’ajustements des valeurs aberrantes et de l’exhaustivité.
Paramètres :
raw_data(data.table) : Données SIGS d’originecompleteness_data(data.table) : Drapeaux d’exhaustivitéoutlier_data(data.table) : Indicateurs de valeurs aberrantes
Retourne :
data.table avec quatre colonnes count_final_*, une par scénario
Scénarios traités :
none: Pas d’ajustement (ligne de base)outliers: Ajustement des valeurs aberrantes uniquementcompleteness: Ajustement de l’exhaustivité uniquementboth: Valeur aberrante séquentielle puis ajustement de l’exhaustivité
Logique de traitement :
- Appelle
apply_adjustments()une fois par scénario - Préserve le
countbrut pour les indicateurs correspondant à la regexdeath|still_birthet pour les indicateurs de faible volume (en écrasant toutcount_workingspécifique au scénario) - Fusionne tous les résultats des scénarios dans un seul tableau au format large avec quatre colonnes
count_final_*
Méthodes statistiques et algorithmes
Section intitulée « Méthodes statistiques et algorithmes »Méthodologie d'ajustement des valeurs aberrantes
L’ajustement des valeurs aberrantes est appliqué à toute valeur du mois de l’établissement signalée dans le module 1 (outlier_flag == 1). L’objectif est de remplacer ces valeurs aberrantes par des données historiques valides provenant du même établissement et du même indicateur.
Approche statistique :
Les moyennes mobiles sont utilisées pour estimer les valeurs attendues. Une moyenne glissante (également appelée moyenne mobile) est la moyenne d’un ensemble de périodes entourant la période cible. Cette technique permet de lisser les fluctuations à court terme et de mettre en évidence les tendances à long terme.
Définition des valeurs valides :
Seules les valeurs répondant à TOUS les critères suivants sont utilisées dans les calculs :
!is.na(count)(non-missing)outlier_flag == 0(non signalées comme aberrantes)
Mise en œuvre :
Le module utilise frollmean() du paquet zoo pour des calculs de roulement efficaces :
data_adj[, valid_count := fifelse(outlier_flag == 0L & !is.na(count), count, NA_real_)]data_adj[, `:=`( roll6 = frollmean(valid_count, 6, na.rm = TRUE, align = "center"), fwd6 = frollmean(valid_count, 6, na.rm = TRUE, align = "left"), bwd6 = frollmean(valid_count, 6, na.rm = TRUE, align = "right"), fallback= mean(valid_count, na.rm = TRUE)), by = .(facility_id, indicator_common_id)]Hiérarchie d'ajustement pour les valeurs aberrantes
Le processus d’ajustement suit cet ordre hiérarchique (en s’arrêtant à la première méthode disponible) :
-
Moyenne centrée sur 6 mois (
roll6)- Utilise les trois mois précédant et les trois mois suivant le mois aberrant
- Fournit une moyenne équilibrée basée sur les tendances proches
- S’applique lorsqu’il existe suffisamment de valeurs valides de part et d’autre du mois
- Étiquette de la méthode :
roll6
-
Moyenne prévisionnelle sur 6 mois (
fwd6)- Utilisée si la moyenne centrée ne peut pas être calculée (par exemple, au début de la série temporelle)
- Prend la moyenne des six prochains mois valides
- Étiquette de la méthode :
forward
-
Moyenne des 6 mois rétrospectifs (
bwd6)- Utilisé si ni
roll6nifwd6ne sont disponibles - Prend la moyenne des six mois valides les plus récents avant la valeur aberrante
- Étiquette de la méthode :
backward
- Utilisé si ni
-
Même mois que l’année précédente
- S’il n’existe pas de moyenne valable sur 6 mois, la valeur du même mois civil de l’année précédente est utilisée (par exemple, janvier 2023 pour janvier 2024)
- Ne s’applique que si la valeur précédente est valide (non signalée comme aberrante et non manquante) et uniquement lorsqu’un seul enregistrement de l’année précédente correspond
- Particulièrement utile pour les indicateurs saisonniers (par exemple, paludisme, infections respiratoires)
- Étiquette de la méthode :
same_month_last_year - Mise en œuvre :
data_adj[, `:=`(mm = month(date), yy = year(date))]data_adj <- data_adj[, {for (i in which(outlier_flag == 1L & is.na(adj_method))) {j <- which(mm == mm[i] & yy == yy[i] - 1 & outlier_flag == 0L & !is.na(count))if (length(j) == 1L) {count_working[i] <- count[j]adj_method[i] <- "same_month_last_year"adjust_note[i] <- format(date[j], "%b-%Y")}}.SD}, by = .(facility_id, indicator_common_id)] -
Moyenne de toutes les valeurs historiques (repli)
- Si toutes les méthodes précédentes échouent, la moyenne de toutes les valeurs historiques valides pour cet indicateur dans cet établissement est utilisée
- Fournit une base de référence spécifique à l’établissement lorsqu’aucun modèle temporel n’est disponible
- Étiquette de la méthode :
fallback
Cas de figure :
Si même la moyenne de repli au niveau de l’établissement ne peut pas être calculée (par exemple, l’établissement n’a aucune observation valide non aberrante pour cet indicateur), la valeur aberrante reste à NA dans les colonnes de scénarios ajustées.
Méthodologie d'ajustement de l'exhaustivité
L’ajustement d’exhaustivité est appliqué à tout mois-établissement où le count_working est manquant (is.na(count_working)). Dans le scénario completeness, cela est déclenché par un count original NA (l’établissement n’a pas déclaré ce mois-là). Dans le scénario both, le count_working peut également être NA parce que l’étape de traitement des valeurs aberrantes n’a pas produit de remplacement. Le completeness_flag du module 1 est fusionné dans les données pour référence mais n’est pas utilisé comme déclencheur du remplacement.
Approche statistique :
La même méthodologie de moyenne mobile est appliquée, mais la définition des “valeurs valides” diffère légèrement :
Valeurs valides pour l’ajustement de l’exhaustivité :
!is.na(count_working)(non manquantes, peut-être déjà ajustées pour les valeurs aberrantes)outlier_flag == 0(non signalé comme aberrant dans les données d’origine)
Différence essentielle par rapport à l’ajustement des valeurs aberrantes :
- L’ajustement pour l’exhaustivité peut utiliser des valeurs qui ont déjà été ajustées pour les valeurs aberrantes (lorsque les scénarios incluent les deux ajustements)
- Aucune méthode du même mois et de la dernière année n’est utilisée (uniquement des moyennes glissantes et une méthode de repli)
**Mise en œuvre
data_adj[, valid_count := fifelse(!is.na(count_working) & outlier_flag == 0L, count_working, NA_real_)]data_adj[, `:=`( roll6 = frollmean(valid_count, 6, na.rm = TRUE, align = "center"), fwd6 = frollmean(valid_count, 6, na.rm = TRUE, align = "left"), bwd6 = frollmean(valid_count, 6, na.rm = TRUE, align = "right"), fallback= mean(valid_count, na.rm = TRUE)), by = .(facility_id, indicator_common_id)]Hiérarchie d'ajustement pour l'exhaustivité
Le remplacement suit cet ordre hiérarchique :
-
Moyenne centrée sur 6 mois (
roll6)- Utilise trois mois valides avant et après le mois manquant ou incomplet
- Méthode préférée lorsque les données environnantes sont suffisantes
- Étiquette de la méthode :
roll6
-
Moyenne prévisionnelle sur 6 mois (
fwd6)- Utilisé si la moyenne centrée ne peut pas être calculée (par exemple, au début de la série temporelle)
- Étiquette de la méthode :
forward
-
Moyenne rétrospective sur 6 mois (
bwd6)- Utilisée si aucune valeur centrée ou prospective n’est disponible (par exemple, à la fin de la série temporelle)
- Étiquette de la méthode :
backward
-
Moyenne de toutes les valeurs historiques (repli)
- Si aucune moyenne mobile ne peut être calculée, utilise la moyenne de toutes les valeurs valides pour cet indicateur dans cet établissement
- Fournit une base de référence spécifique à l’établissement
- Étiquette de la méthode :
fallback
Cas de figure :
Si l’établissement n’a aucune valeur valide pour cet indicateur, la moyenne de repli est elle-même NA et la valeur reste manquante dans les colonnes de scénarios ajustées.
Logique de traitement des scénarios
Le module traite simultanément les quatre scénarios d’ajustement à l’aide de la fonction apply_adjustments_scenarios() :
Scénario 1 : Aucun (count_final_none)
adjust_outliers = FALSE,adjust_completeness = FALSE- Données brutes originales sans aucune modification
- Sert de référence pour la comparaison
Scénario 2 : valeurs aberrantes (count_final_outliers)
adjust_outliers = TRUE,adjust_completeness = FALSE- Seules les valeurs aberrantes sont remplacées
- Les valeurs manquantes/incomplètes restent telles quelles
- Cas d’utilisation : Lorsque l’exhaustivité est élevée mais que les valeurs aberrantes posent problème
Scénario 3 : Exhaustivité (count_final_completeness)
adjust_outliers = FALSE,adjust_completeness = TRUE- Seules les valeurs manquantes/incomplètes sont imputées
- Les valeurs aberrantes sont conservées dans les données
- Cas d’utilisation : Lorsque la qualité des données est bonne mais que la déclaration est sporadique
Scénario 4 : Les deux (count_final_both)
adjust_outliers = TRUE,adjust_completeness = TRUE- Traitement séquentiel : Traitement séquentiel** : les valeurs aberrantes sont d’abord corrigées, puis l’exhaustivité
- Ajustement le plus complet
- Cas d’utilisation : Lorsque les deux problèmes de qualité des données sont prévalents
**Ordre de traitement pour le scénario “Les deux” :
- L’ajustement des valeurs aberrantes crée un
count_workingoù les valeurs aberrantes sont remplacées - L’ajustement de complétude opère ensuite sur
count_working, en utilisant les valeurs déjà ajustées - Cela garantit que l’imputation de l’exhaustivité utilise des valeurs nettoyées (non aberrantes) lorsqu’elles sont disponibles
Important :
Après les ajustements spécifiques au scénario, les indicateurs exclus sont réinitialisés à leur count brut original. Cela s’applique à la fois aux indicateurs de mortalité/mortinaissance (correspondant à la regex EXCLUDED_PATTERN) et aux indicateurs de faible volume :
dat[grepl(EXCLUDED_PATTERN, indicator_common_id, ignore.case = TRUE) | indicator_common_id %in% LOW_VOLUME_INDICATORS, count_working := count]Par conséquent, les quatre colonnes count_final_* pour ces indicateurs sont toutes égales à la valeur brute.
Méthodes d'agrégation
Toutes les agrégations géographiques utilisent des sommes simples :
sum(count_final_both, na.rm = TRUE)Raison d’être :
- Les volumes de services sont additifs (par exemple, les livraisons totales = la somme des livraisons des installations)
- Les valeurs manquantes (
NA) sont considérées comme nulles dans l’agrégation - Conforme aux pratiques standard de reporting du SIGS
Avertissement :
Si de nombreux établissements ont des valeurs NA après ajustement, les totaux sous-nationaux/nationaux peuvent être sous-estimés. Le scénario count_final_none fournit un point de référence pour évaluer l’impact.
Traitement des données manquantes dans les calculs
Le module applique na.rm = TRUE dans tous les calculs de roulement :
frollmean(valid_count, 6, na.rm = TRUE, align = "center")Implication :
Les moyennes glissantes sont calculées à partir des seules valeurs valides disponibles. S’il existe moins de 6 valeurs, la moyenne est calculée à partir de toutes les valeurs disponibles. Si aucune valeur valide n’existe, le résultat est NA.
Exemples de code
Section intitulée « Exemples de code »Exemple 1 : Ajustement des valeurs aberrantes
Scénario :
Une structure sanitaire signale un nombre anormalement élevé de premières visites de soins prénatals (CPN1) en mars 2023.
Données :
period_id | count | outlier_flag | Surrounding valid values----------|-------|--------------|-------------------------202301 | 145 | 0 | valid202302 | 152 | 0 | valid202303 | 890 | 1 | outlier202304 | 148 | 0 | valid202305 | 155 | 0 | valid202306 | 147 | 0 | validCalcul de l’ajustement (moyenne centrée sur 6 mois) :
- Valeurs valides : [145, 152, 148, 155, 147] (exclut la valeur aberrante 890)
- Moyenne : (145 + 152 + 148 + 155 + 147) / 5 = 149,4
- Valeur ajustée : 149.4
**Méthode utilisée
roll6
Exemple 2 : Ajustement de la complétude
Scénario :
Un établissement ne déclare pas les tests de dépistage du paludisme en février 2023.
Données :
period_id | count | completeness_flag | Surrounding valid values----------|-------|-------------------|-------------------------202301 | 45 | 1 | valid202302 | NA | 0 | INCOMPLETE202303 | 48 | 1 | valid202304 | 52 | 1 | valid202305 | 50 | 1 | validCalcul de l’ajustement (moyenne centrée sur 6 mois) :
- Valeurs valides : [45, 48, 52, 50, …]
- Moyenne : 48.75 (en utilisant les mois environnants disponibles)
- Valeur calculée : 48.75
**Méthode utilisée
roll6
Exemple 3 : Indicateur saisonnier avec même mois-dernière année
Scénario :
Les cas de paludisme présentent une forte saisonnalité et une valeur aberrante de juin 2023 doit être ajustée.
Données :
period_id | count | outlier_flag | Notes----------|-------|--------------|-------202206 | 234 | 0 | June 2022 (valid)202306 | 1850 | 1 | June 2023 (outlier)Logique d’ajustement :
- Les moyennes mobiles centrées, avant et arrière ne sont pas disponibles (données insuffisantes)
- Méthode du même mois et de la dernière année activée
- Valeur juin 2022 = 234 (valide)
- Valeur ajustée : 234
Méthode utilisée :
same_month_last_year
Exemple 4 : Comparaison de scénarios
établissement :
FAC001
Indicateur :
Livraisons institutionnelles
Période :
Q1 2023
Données originales :
Month | Count | outlier? | Complete?---------|-------|----------|----------Jan 2023 | 78 | No | YesFeb 2023 | 450 | Yes | Yes # outlierMar 2023 | NA | - | No # IncompleteScénario de résultats :
| Mois - Aucun - Valeurs aberrantes - Exhaustivité - Les deux - Les deux - Les deux |----------|------|----------|--------------|------| | Janv. 2023 - 78 - 78 - 78 - 78 - 78 - 78 - 78 - 78 - 78 - 78 - 78 - 78 - 78 - 78 - 78 - 78 - 78 - 78 | Fév 2023 | 450 | 82* | 450 | 82* | | Mar 2023 | NA | NA | 80** | 80** | 80** | 80** | 80** | 80** | 80** | 80** | 80**
*Ajusté en utilisant la moyenne mobile
**Calculé sur la base d’une moyenne mobile
Interprétation :
- Aucune : Données brutes avec des problèmes évidents
- valeurs aberrantes : Février corrigé, mais mars reste manquant
- Complétude : mars est complété, mais la valeur aberrante de février est conservée : Mars est complété, mais la valeur aberrante de février est conservée
- Les deux : Ensemble de données le plus complet et le plus propre
Exemple 5 : Agrégation géographique
Code d’agrégation sous-nationale :
adjusted_data_admin_area_final <- adjusted_data_export[ , .( count_final_none = sum(count_final_none, na.rm = TRUE), count_final_outliers = sum(count_final_outliers, na.rm = TRUE), count_final_completeness = sum(count_final_completeness, na.rm = TRUE), count_final_both = sum(count_final_both, na.rm = TRUE) ), by = c(geo_admin_area_sub, "indicator_common_id", "period_id")]Code d’agrégation nationale :
adjusted_data_national_final <- adjusted_data_export[ , .( count_final_none = sum(count_final_none, na.rm = TRUE), count_final_outliers = sum(count_final_outliers, na.rm = TRUE), count_final_completeness = sum(count_final_completeness, na.rm = TRUE), count_final_both = sum(count_final_both, na.rm = TRUE) ), by = .(admin_area_1, indicator_common_id, period_id)]Dépannage
Section intitulée « Dépannage »Problèmes courants
Problème 1 : Toutes les valeurs restent non ajustées
Causes possibles :
- Le nom de l’indicateur correspond au motif d’exclusion
death|still_birth - Indicateur marqué comme étant de faible volume (aucune observation n’a jamais atteint
count >= 100) - Aucun indicateur aberrant (
outlier_flag == 1) et aucune valeur manquante dans les données d’entrée
Solution :
Vérifier M2_low_volume_exclusions.csv et vérifier que les sorties du module 1 contiennent des indicateurs
**Problème 2 : Les valeurs ajustées semblent déraisonnables
Causes possibles :
- Insuffisance de données historiques valides pour les moyennes mobiles
- Les modifications réelles du programme sont lissées
- Les tendances saisonnières ne sont pas prises en compte dans la fenêtre de 6 mois
Solution :
- Examiner les graphiques de séries chronologiques propres à l’établissement
- Envisager d’utiliser le scénario “valeurs aberrantes uniquement” si l’exhaustivité est bonne
- Valider par rapport aux registres de mise en œuvre du programme
Problème 3 : Nombreuses valeurs NA après ajustement
Causes possibles :
- L’installation dispose de très peu de données
- Aucune valeur valide n’est disponible pour aucune méthode d’ajustement
- Les premiers mois de la série chronologique manquent de données historiques
Solution :
- Attendu pour les établissements ayant un historique de déclaration limité
- Envisager un filtrage de la qualité des données au niveau de l’établissement
- Les agrégats nationaux/sous-nationaux additionneront les valeurs disponibles
Problème 4 : Les totaux sous-nationaux/nationaux ne correspondent pas aux attentes
Causes possibles :
- Les valeurs NA sont considérées comme nulles lors de l’agrégation
- Différents scénarios produisent des totaux différents
- Faible exhaustivité des rapports dans l’ensemble
Solution :
- Comparer
count_final_nonevscount_final_bothpour évaluer l’impact de l’ajustement - Examiner les statistiques sur l’exhaustivité du module 1
- Considérer le seuil de qualité des données pour l’inclusion
Contrôles d'assurance qualité
Le module comprend plusieurs contrôles de qualité :
- Exclusions des faibles volumes : Identifie et exclut automatiquement les indicateurs qui n’atteignent jamais
count >= 100 - Suivi des ajustements : Compte et rapporte le nombre de valeurs ajustées par chaque méthode (
roll6,forward,backward,same_month_last_year,fallback) - Indicateurs exclus : Assure que les indicateurs de mortalité et de mortinaissance (correspondant à la regex
death|still_birth) ne sont jamais ajustés - Journalisation de la console : Fournit des statistiques détaillées sur l’état d’avancement et des statistiques sommaires
Exemple de sortie de la console :
Running adjustments... -> Adjusting outliers... Roll6 adjusted: 1,245 Forward-filled: 89 Backward-filled: 67 Same-month LY: 34 Fallback mean: 12 -> Adjusting for completeness... Roll6 filled: 2,103 Forward-filled: 234 Backward-filled: 178 Fallback mean: 45Notes d’utilisation
Section intitulée « Notes d’utilisation »Choisir le bon scénario
| Situation | Scénario recommandé | Raison d’être |
|---|---|---|
| Données de haute qualité, problèmes minimes | none | Aucun ajustement n’est nécessaire |
| Valeurs aberrantes sporadiques, bonne exhaustivité | outliers | Traiter la qualité sans imputation |
| Bonne qualité, faible fréquence de déclaration | completeness | Combler les lacunes tout en préservant les valeurs réelles |
| Qualité et exhaustivité médiocres | both | Nettoyage complet |
| Incertitude sur la qualité des données | Comparer tous les scénarios | Analyse de sensibilité |
Étapes de validation
Après avoir exécuté ce module, considérez :
- Comparer les scénarios : Examiner les différences entre
count_final_noneetcount_final_both - Examiner les exclusions : Vérifier que
M2_low_volume_exclusions.csvne contient pas d’indicateurs inattendus - Analyse agrégée : S’assurer que les totaux infranationaux et nationaux sont raisonnables
- Graphiques temporels : Visualiser les tendances avant/après l’ajustement pour identifier le lissage excessif
- Vérifications ponctuelles au niveau de l’établissement : Examiner les ajustements pour un échantillon d’installations
Limites
-
Les fenêtres mobiles supposent la stabilité : Les ajustements fonctionnent mieux lorsque la prestation de services est relativement stable. De véritables changements de programme (par exemple, de nouvelles campagnes) peuvent être lissés de manière incorrecte.
-
Pas d’incertitude sur les ajustements : Le module fournit des estimations ponctuelles sans intervalles de confiance. Les valeurs ajustées doivent être considérées comme des estimations.
-
Ajustements spécifiques à l’installation : Il n’y a pas d’emprunt d’informations entre les établissements. Les établissements disposant de très peu de données peuvent avoir des ajustements instables.
-
Modèles saisonniers : Bien qu’il soit utile d’avoir le même mois que l’année précédente, une forte saisonnalité au sein de l’année peut ne pas être entièrement prise en compte par des fenêtres de 6 mois.
-
Traitement des données manquantes dans l’agrégation : Les valeurs manquantes sont considérées comme nulles lorsqu’elles sont additionnées à des niveaux géographiques plus élevés, ce qui peut entraîner une sous-estimation des totaux si les valeurs manquantes sont élevées.
Dernière mise à jour : 20-05-2026 Contact : fastr@worldbank.org