Analyse de l'utilisation des services
Contexte et objectif
Section intitulée « Contexte et objectif »Objectif du module
Section intitulée « Objectif du module »Le module Utilisation des services analyse les schémas de prestation des services de santé afin de détecter et de quantifier les perturbations des volumes de services au fil du temps. Il identifie les écarts par rapport aux schémas de prestation de services prévus et estime l’ampleur de ces perturbations aux niveaux national, provincial et du district.
À l’aide de méthodes de contrôle des processus statistiques et de régression, le module compare les volumes de services observés avec les niveaux attendus dérivés des tendances historiques et saisonnières. Cela permet de distinguer les variations régulières et prévisibles (telles que l’augmentation saisonnière des cas de paludisme) des perturbations importantes des services, y compris les baisses soudaines des services du SRMNIA-N - tels que la vaccination et les soins de santé maternelle ou infantile - pendant les périodes de conflit ou les urgences de santé publique.
L’analyse produit des estimations quantifiées des déficits et des excédents de services, ce qui permet de mesurer systématiquement les changements dans la prestation des services et de les comparer dans le temps et au niveau géographique.
Raison d’être de l’analyse
Section intitulée « Raison d’être de l’analyse »Les données sur l’utilisation des services donnent une idée de la manière dont les populations accèdent aux services de santé essentiels, mais les volumes observés peuvent varier pour de multiples raisons, notamment la saisonnalité, les changements de politique, les chocs extérieurs (tels que les pandémies, les catastrophes naturelles ou les conflits), les limites de la qualité des données et les changements dans la disponibilité des services. Sans analyse systématique, il est difficile de distinguer les variations normales des perturbations matérielles dans la prestation des services.
Ce module applique une approche standardisée, basée sur les données, pour identifier les déviations dans l’utilisation des services et pour quantifier leur ampleur. Les résultats permettent de détecter les problèmes émergents dans la prestation de services, de les comparer entre les différents niveaux géographiques et de les suivre dans le temps, y compris pendant les périodes de perturbation et de reprise. Les résultats sont structurés de manière à pouvoir être utilisés pour le suivi de routine, les rapports analytiques et l’évaluation des changements dans la performance des services de santé.
Points clés
Section intitulée « Points clés »| Composante | Détails |
|---|---|
| Entrées | Volumes de services ajustés du module 2 (M2_adjusted_data.csv et M2_adjusted_data_admin_area.csv)Indicateurs de valeurs aberrantes du module 1 ( M1_output_outliers.csv)SIGS brut ( hmis_ISO3.csv) - uniquement pour la correspondance entre facility_id et admin_area_1 |
| Sorties | Données ajustées en passage direct (M3_service_utilization.csv)Indicateurs de perturbation ( M3_chartout.csv)Impacts quantifiés par niveau géographique ( M3_disruptions_analysis_admin_area_1 à _4.csv)Résumés des déficits/excédents ( M3_all_indicators_shortfalls_admin_area_1 à _4.csv) |
| Objectif | Détecter et quantifier les perturbations dans la fourniture des services par une analyse en deux étapes : les cartes de contrôle identifient quand les perturbations se produisent, la régression par panel quantifie leur ampleur |
Flux de travail analytique
Section intitulée « Flux de travail analytique »Aperçu des étapes analytiques
Section intitulée « Aperçu des étapes analytiques »Le module fonctionne en deux parties séquentielles, chacune ayant un objectif distinct :
Partie 1 : Analyse de la carte de contrôle - Identifie les schémas inhabituels dans les volumes de service
-
Préparer les données : Charger les données sur les services de santé, supprimer les valeurs aberrantes précédemment identifiées, les agréger au niveau géographique approprié et compléter les mois manquants par interpolation.
-
Modéliser les modèles attendus : Pour chaque combinaison d’indicateur de santé et de zone géographique, utiliser des méthodes statistiques robustes pour estimer ce que les volumes de services devraient être sur la base des tendances historiques et saisonnières (par exemple, tenir compte des augmentations prévisibles des cas de paludisme pendant la saison des pluies).
-
Détecter les écarts : Comparer les volumes de services réels aux modèles attendus et identifier les écarts significatifs à l’aide de plusieurs règles de détection :
- Perturbations brutales : mois uniques présentant des écarts extrêmes
- Baisses prolongées : baisse graduelle sur plusieurs mois
- Baisses soutenues : périodes constamment inférieures aux niveaux attendus
- Hausses soutenues : périodes constamment supérieures aux niveaux attendus
- Données manquantes : lacunes dans les rapports qui peuvent signaler des problèmes
-
Signaler les périodes perturbées : Marquer les mois où un modèle de perturbation est détecté, en veillant à ce que les mois récents soient toujours signalés pour examen.
Partie 2 : Analyse des perturbations - Quantifie l’impact des perturbations identifiées
-
Appliquer des modèles de régression : Utiliser la régression par panel à plusieurs niveaux géographiques (national, provincial, district) pour estimer dans quelle mesure les volumes de services ont changé pendant les périodes de perturbation identifiées, en tenant compte des tendances et de la saisonnalité.
-
Calculer les déficits et les excédents : Comparer les volumes prévus aux volumes réels pour quantifier l’ampleur des perturbations en chiffres absolus et en pourcentages.
-
Générer des résultats : Créer des fichiers de synthèse montrant l’impact des perturbations à chaque niveau géographique, prêts à être visualisés et à faire l’objet de rapports.
Diagramme de flux de travail
Section intitulée « Diagramme de flux de travail »Points de décision clés
Section intitulée « Points de décision clés »Niveau d’analyse géographique
Le module prend en charge l’analyse des perturbations à plusieurs échelles géographiques. Les utilisateurs peuvent limiter l’analyse aux niveaux national et provincial, ce qui est plus rapide en termes de calcul et convient au suivi de routine, ou étendre l’analyse aux niveaux du district et de la circonscription pour obtenir des informations plus granulaires en vue d’une enquête et d’une réponse ciblées.
Sélection du niveau de la carte de contrôle
Le niveau auquel les cartes de contrôle sont calculées détermine où la modélisation statistique est effectuée. Il est configuré à l’aide de deux drapeaux et suit la convention FASTR selon laquelle les niveaux administratifs les plus élevés correspondent à des unités géographiques plus petites.
-
Configuration par défaut (les deux drapeaux sont à FALSE) Les cartes de contrôle sont calculées à un niveau infranational intermédiaire (admin_area_2). Les volumes de services sont agrégés à ce niveau, et l’estimation des tendances, le calcul des limites de contrôle et la détection des perturbations sont effectués pour chaque combinaison géographie-indicateur. Cette option est la plus efficace en termes de calcul et convient au suivi de routine.
-
RUN_DISTRICT_MODEL = TRUE Les cartes de contrôle sont calculées à un niveau infranational plus fin (admin_area_3). Les volumes de services sont agrégés à des unités géographiques plus petites, ce qui permet de détecter des perturbations localisées qui pourraient être masquées à des niveaux d’agrégation plus élevés. Cette option nécessite davantage de calculs, mais offre une meilleure résolution spatiale.
-
RUN_ADMIN_AREA_4_ANALYSIS = TRUE Les cartes de contrôle sont calculées au niveau géographique le plus granulaire disponible (admin_area_4). Cela permet d’identifier les perturbations très localisées ou au niveau des établissements. Il s’agit de l’option la plus gourmande en ressources et elle est généralement utilisée pour des analyses ciblées ou diagnostiques.
Le niveau de carte de contrôle sélectionné détermine l’endroit où la modélisation statistique est effectuée, y compris l’estimation des tendances, le calcul des limites de contrôle et le signalement des perturbations. Quel que soit le niveau auquel les cartes de contrôle sont calculées, les résultats des perturbations sont agrégés et présentés à tous les niveaux géographiques disponibles (national et infranational).
Paramètres de sensibilité
Le module utilise des seuils statistiques configurables pour définir ce qui constitue une perturbation. Les paramètres les plus sensibles (seuils inférieurs) signalent les écarts les plus faibles par rapport aux modèles attendus et conviennent à des fins d’alerte précoce. Les paramètres plus conservateurs (seuils plus élevés) limitent la détection aux écarts plus importants et sont utiles pour se concentrer sur les perturbations majeures.
Traitement de la complétude des rapports
Le module accepte des versions alternatives des comptages de services produits par le module 2, ce qui permet aux utilisateurs de choisir d’analyser les volumes bruts rapportés ou les volumes ajustés pour tenir compte de la complétude des rapports. Cela permet d’aligner l’analyse des perturbations sur différentes hypothèses de qualité des données.
Traitement des données et résultats
Section intitulée « Traitement des données et résultats »Transformation de l’entrée
Le module commence par le décompte mensuel des services au niveau de l’établissement (par exemple, les accouchements déclarés par chaque établissement). Ces données sont agrégées au niveau géographique sélectionné. Les observations identifiées comme aberrantes dans le module 1 sont exclues afin d’éviter que les valeurs anormales n’influencent l’estimation des tendances et les limites de contrôle.
Estimation et détection des tendances
En utilisant des méthodes statistiques robustes, le module estime les modèles d’utilisation des services attendus pour chaque indicateur et unité géographique sur la base des données historiques, en tenant compte des tendances à long terme et de la saisonnalité. Les mois au cours desquels les volumes de services observés s’écartent de manière significative de ces modèles attendus sont signalés comme des perturbations potentielles.
Quantification de l’impact des perturbations
Pour les périodes identifiées comme perturbées, des modèles de régression sont utilisés pour estimer les volumes de service contrefactuels - représentant l’utilisation attendue en l’absence de perturbation. Les différences entre les volumes prédits et observés sont calculées pour quantifier les insuffisances ou les excédents de service.
Structure de sortie
Les résultats finaux présentent les mesures de perturbation à plusieurs niveaux géographiques, depuis les résumés nationaux jusqu’aux résultats locaux détaillés. Les données originales sont conservées, avec des champs supplémentaires fournissant les valeurs attendues, les indicateurs de perturbation et les impacts quantifiés.
Résultats de l’analyse et visualisation
Section intitulée « Résultats de l’analyse et visualisation »L’analyse FASTR génère quatre sorties visuelles principales pour l’utilisation des services :
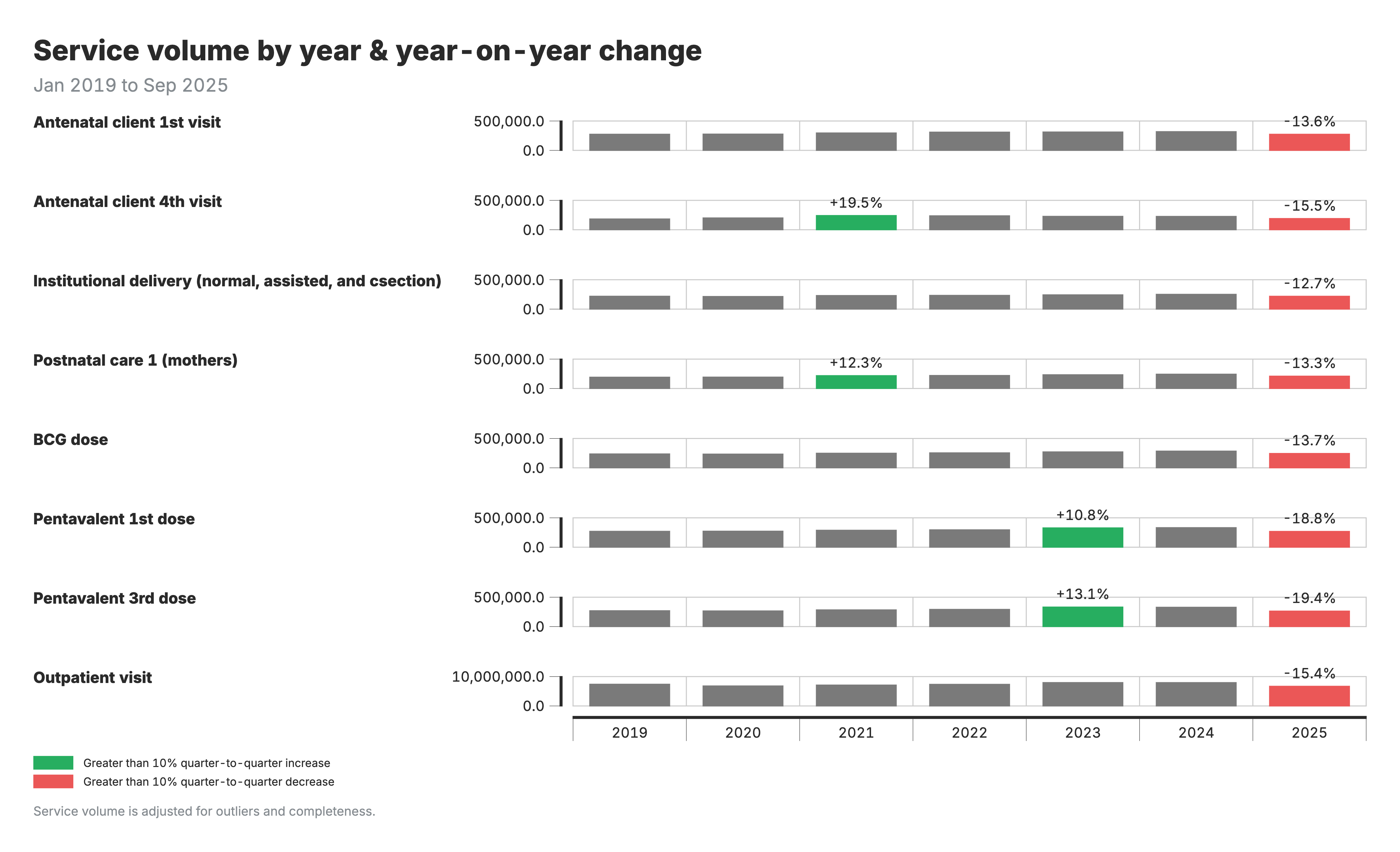
1. Changement dans le volume de service
Diagramme à barres montrant les volumes de services annuels par région et par indicateur, avec des annotations sur la variation en pourcentage d’une année sur l’autre.
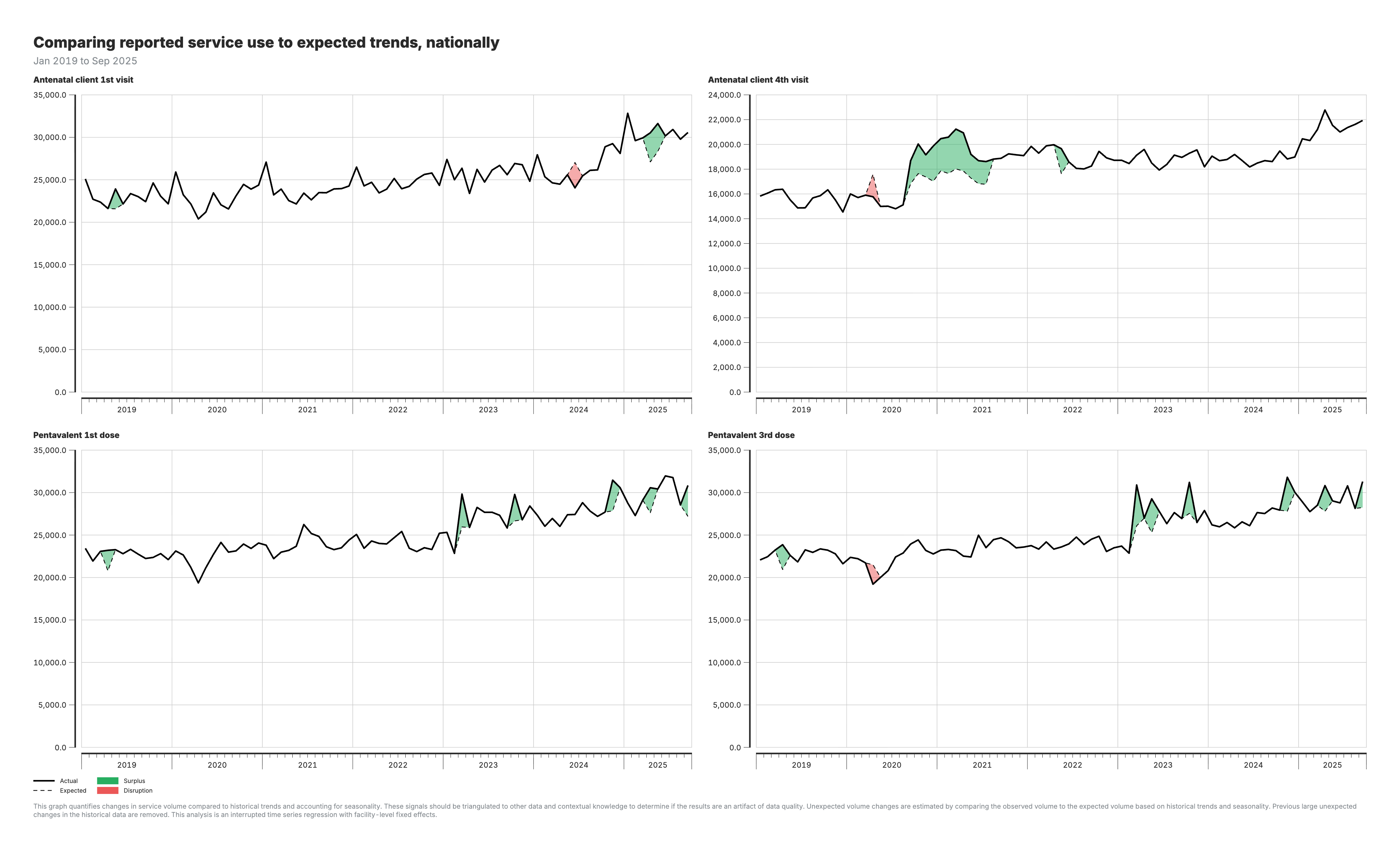
2. Services réels par rapport aux services prévus (national)
Graphique linéaire comparant les volumes de services observés aux prévisions du modèle au niveau national.
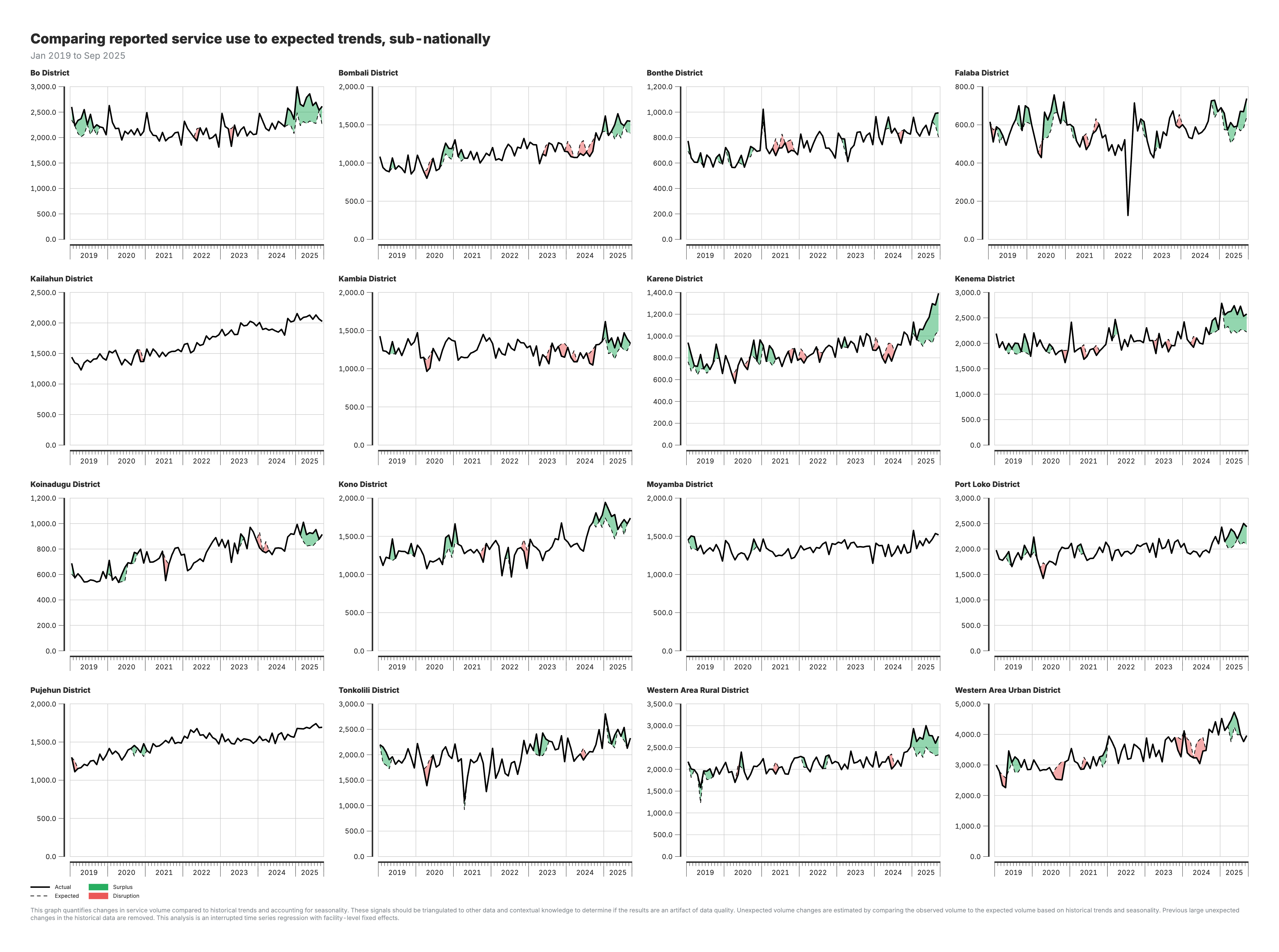
3. Services réels par rapport aux services attendus (au niveau infranational)
Graphiques linéaires par région comparant les volumes observés aux modèles attendus.
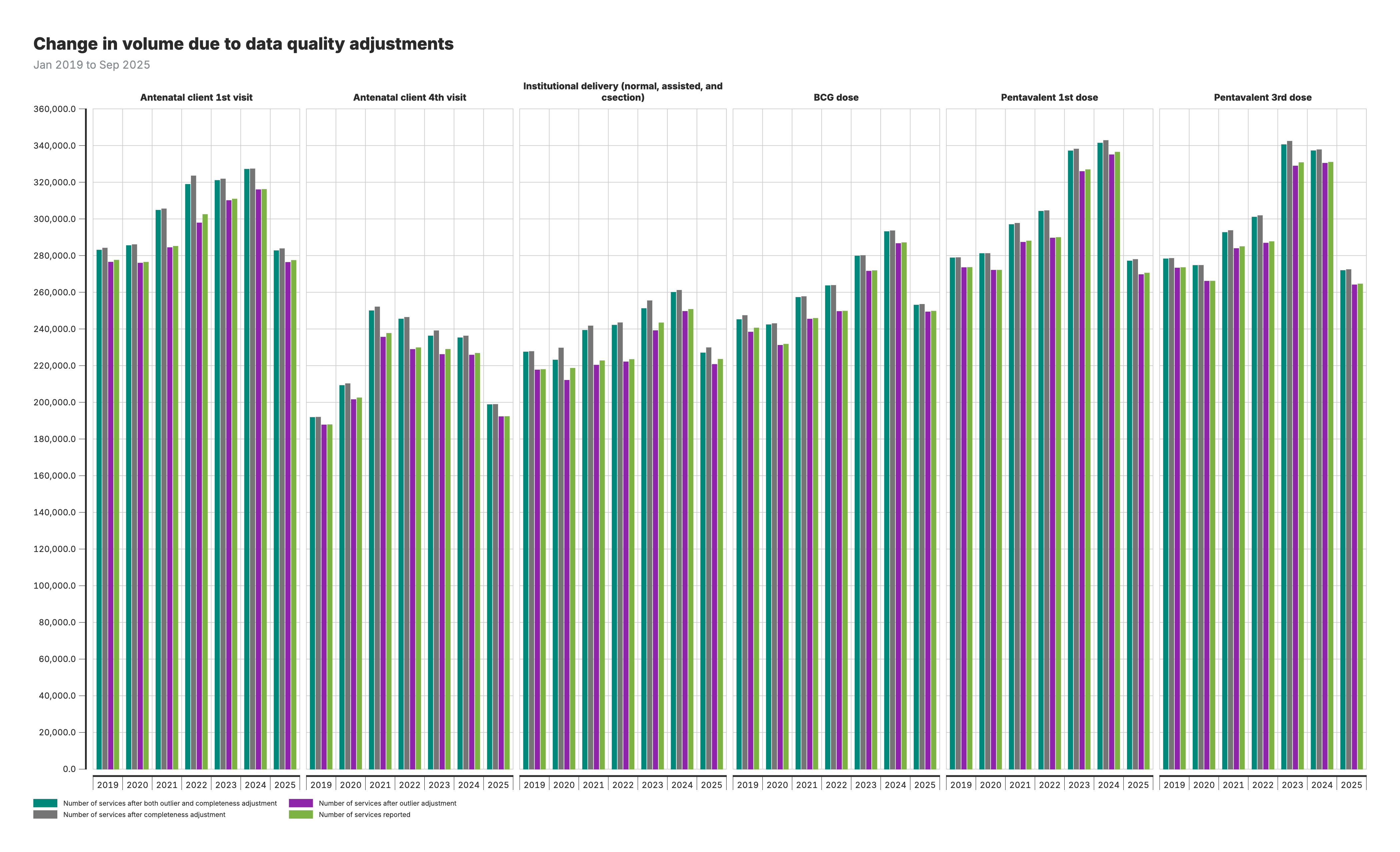
4. Variation de volume due aux ajustements de la qualité des données
Diagramme à barres groupées comparant les volumes de services selon quatre scénarios d’ajustement : pas d’ajustement, ajustement des valeurs aberrantes uniquement, ajustement de la complétude uniquement, et les deux ajustements.
Guide d’interprétation
Pour le tableau de variation du volume des services (sortie 1) :
- Barres : Volumes annuels de services par région
- Annotations : Pourcentage de variation d’une année sur l’autre entre deux années consécutives
Pour les graphiques “réel” et “prévu” (résultats 2-3) :
- Ligne noire : Volumes de services réels (observés)
- Zones ombrées en rouge : Périodes de déficit (réel inférieur aux prévisions)
- Zones ombrées en vert : Périodes d’excédent (réel supérieur aux prévisions)
Pour le graphique de variation de volume (résultat 4) :
- Quatre barres par année : Chaque barre représente un scénario d’ajustement différent
- Comparer les hauteurs des barres pour voir comment les ajustements affectent les volumes déclarés
Référence détaillée
Section intitulée « Référence détaillée »Paramètres de configuration
Section intitulée « Paramètres de configuration »Paramètres d'analyse de base
| Paramètre | Valeur par défaut | Type | Description | Guide de réglage |
|---|---|---|---|---|
COUNTRY_ISO3 | ”ISO3” | Chaîne | Code de pays à trois lettres | Définissez votre code de pays (par exemple, “RWA”, “UGA”, “ZMB”) |
SELECTEDCOUNT | ”count_final_outliers” | Chaîne | Colonne de données utilisée pour la modélisation par régression | Options : count_final_none, count_final_outliers, count_final_completeness, count_final_both |
VISUALIZATIONCOUNT | ”count_final_outliers” | Chaîne | Colonne de données utilisée pour la visualisation | Mêmes options que SELECTEDCOUNT ; peut différer si vous souhaitez modéliser sur l’une et représenter graphiquement l’autre |
Paramètres de la carte de contrôle
| Paramètre | Valeur par défaut | Type | Description | Guide de réglage |
|---|---|---|---|---|
SMOOTH_K | 7 | Entier (impair) | Taille de la fenêtre médiane mobile en mois | Valeurs plus grandes = tendances plus lisses, moins de sensibilité. Il doit s’agir d’un nombre impair (par exemple, 5, 7, 9, 11) |
MADS_THRESHOLD | 1.5 | Numérique | Seuil des unités MAD pour les fortes perturbations | Plus bas = plus sensible (par exemple, 1.0), plus haut = plus conservateur (par exemple, 2.0) |
DIP_THRESHOLD | 0.90 | Numérique | Seuil de proportion pour les baisses soutenues | 0.90 = marquer si en dessous de 90% de la valeur attendue (baisse de 10%). Utiliser 0.80 pour un seuil de chute de 20% |
DIFFPERCENT | 10 | Numérique | Seuil de pourcentage pour le tracé des perturbations | Si la valeur réelle diffère de la valeur prédite de >10%, utiliser la valeur prédite dans les visualisations |
Note : RISE_THRESHOLD est automatiquement calculé comme 1 / DIP_THRESHOLD (par défaut : ~1.11) pour refléter symétriquement la détection de la baisse.
Paramètres d'analyse géographique
| Paramètre | Valeur par défaut | Type | Description | Guide de réglage |
|---|---|---|---|---|
CONTROL_CHART_LEVEL | Auto-défini | Chaîne | Niveau géographique pour les cartes de contrôle | Réglage automatique basé sur RUN_DISTRICT_MODEL et RUN_ADMIN_AREA_4_ANALYSIS |
RUN_DISTRICT_MODEL | FALSE | Logique | Exécuter ou non les régressions admin_area_3 | Mettre TRUE pour l’analyse au niveau du district (augmente le temps d’exécution) |
RUN_ADMIN_AREA_4_ANALYSIS | FALSE | Logique | Exécuter ou non l’analyse admin_area_4 | Mettre TRUE pour l’analyse au niveau le plus fin (très lent pour les grands ensembles de données) |
Paramètres de la source de données
| Paramètre | Valeur par défaut | Type | Description |
|---|---|---|---|
PROJECT_DATA_HMIS | ”hmis_ISO3.csv” | Chaîne | Nom de fichier pour les données SIGS brutes |
Guide de sélection des paramètres
Pour l’analyse à haute sensibilité (détection des petites perturbations) :
MADS_THRESHOLD = 1.0DIP_THRESHOLD = 0.95(baisse de 5%)SMOOTH_K = 5(moins de lissage)
Pour une analyse conservatrice (seulement les perturbations majeures) :
MADS_THRESHOLD = 2.0DIP_THRESHOLD = 0.80(baisse de 20%)SMOOTH_K = 9ou11(plus de lissage)
Pour une exécution plus rapide :
RUN_DISTRICT_MODEL = FALSERUN_ADMIN_AREA_4_ANALYSIS = FALSECONTROL_CHART_LEVEL = "admin_area_2"
Spécifications des entrées/sorties
Section intitulée « Spécifications des entrées/sorties »Exigences d'entrée
Entrées primaires
Section intitulée « Entrées primaires »-
M2_adjusted_data.csv(source de données principale)- Résultat du module 2 (Ajustements de la qualité des données)
- Contient des comptes de services ajustés avec différentes hypothèses de complétude
- Colonnes obligatoires :
facility_id,indicator_common_id,period_id,count_final_none,count_final_outliers,count_final_completeness,count_final_both
-
M1_output_outliers.csv- Résultat du module 1 (Évaluation de la qualité des données)
- Contient
outlier_flagpour identifier et exclure les points de données anormaux - Colonnes requises :
facility_id,indicator_common_id,period_id,outlier_flag
-
hmis_ISO3.csv(utilisé uniquement pour la recherche géographique)- Fichier SIGS brut utilisé uniquement pour extraire la correspondance facility_id → admin_area_1
- Requis car M2_adjusted_data.csv n’inclut pas admin_area_1
- Colonnes requises :
facility_id,admin_area_1
Exigences en matière de données
Section intitulée « Exigences en matière de données »- Couverture temporelle : Minimum 12 mois de données pour la modélisation saisonnière
- Complétude des données : Les mois manquants sont comblés par interpolation
- Complétude géographique : Données aux niveaux administratifs spécifiés
- Données de comptage : Chiffres entiers non négatifs (les prédictions sont limitées à zéro)
1. Résultats de la carte de contrôle
Section intitulée « 1. Résultats de la carte de contrôle »M3_chartout.csv
Objectif : Contient les perturbations signalées lors de l’analyse de la carte de contrôle
Colonnes :
admin_area_*: Identifiant géographique (le niveau dépend deCONTROL_CHART_LEVEL)indicator_common_id: Code de l’indicateur de service de santéperiod_id: Période au format AAAAMMtagged: Indicateur binaire (1 = perturbation détectée, 0 = normal)
Utilisation : Identifie les mois qui nécessitent un examen plus approfondi pour chaque combinaison indicateur-géographie
M3_service_utilization.csv
But : Copie de passage des données ajustées pour la visualisation
Source : Copie directe de M2_adjusted_data.csv
Utilisation : Fournit des données de base pour le tracé des volumes de service réels
M3_memory_log.txt
But : Suivi de l’utilisation de la mémoire tout au long de l’exécution
Utilisation : Diagnostics pour l’optimisation des performances et le dépannage
2. Résultats de l’analyse des perturbations
Section intitulée « 2. Résultats de l’analyse des perturbations »M3_disruptions_analysis_admin_area_1.csv (niveau national - toujours généré)
Colonnes :
admin_area_1: Nom du paysindicator_common_id: Indicateur de service de santéperiod_id: Période (YYYYMM)count_sum: Volume réel des services (somme de tous les établissements)count_expect_sum: Volume de service attendu (somme des prévisions)count_expected_if_above_diff_threshold: Valeur pour le tracé (attendue si |différence| > DIFFPERCENT, sinon réelle)
M3_disruptions_analysis_admin_area_2.csv (niveau province - toujours généré)
Colonne supplémentaire : admin_area_2 (nom de la province/région)
Même structure : Comme le fichier admin_area_1 mais désagrégé par province
M3_disruptions_analysis_admin_area_3.csv (niveau du district - conditionnel)
Généré quand : RUN_DISTRICT_MODEL = TRUE
Colonnes supplémentaires : admin_area_2, admin_area_3
Même structure : Comme ci-dessus mais désagrégé par district
M3_disruptions_analysis_admin_area_4.csv (niveau du quartier - conditionnel)
Généré quand : RUN_ADMIN_AREA_4_ANALYSIS = TRUE
Colonnes supplémentaires : admin_area_2, admin_area_3, admin_area_4
Avertissement : Fichier très volumineux pour les pays comportant de nombreuses circonscriptions
3. Fichiers de synthèse des déficits/excédents
Section intitulée « 3. Fichiers de synthèse des déficits/excédents »M3_all_indicators_shortfalls_admin_area_*.csv (un pour chaque niveau géographique)
But : Mesures pré-calculées des déficits et des excédents pour les rapports
Colonnes communes :
- Identifiant(s) géographique(s) :
admin_area_* indicator_common_id: Indicateur de service de santéperiod_id: Période (YYYYMM)count_sum: Volume de service réelcount_expect_sum: Volume de service attendushortfall_absolute: Nombre absolu de services manquants (si perturbation négative)shortfall_percent: Pourcentage d’insuffisance par rapport aux prévisionssurplus_absolute: Nombre absolu de services excédentaires (en cas de perturbation positive)surplus_percent: Pourcentage d’excédent par rapport aux prévisions
Note : Si les niveaux géographiques optionnels sont désactivés, des fichiers de remplacement vides sont créés pour assurer la compatibilité avec les processus en aval.
Fichiers temporaires (nettoyés automatiquement)
Section intitulée « Fichiers temporaires (nettoyés automatiquement) »Pendant l’exécution, le module crée des fichiers batch temporaires pour la gestion de la mémoire :
M3_temp_controlchart_batch_*.csvM3_temp_indicator_batch_*.csvM3_temp_province_batch_*.csvM3_temp_district_batch_*.csvM3_temp_admin4_batch_*.csv
Ces fichiers sont automatiquement supprimés en cas de succès. Si le script se plante, ces fichiers peuvent subsister et seront nettoyés lors de la prochaine exécution.
Documentation des fonctions clés
Section intitulée « Documentation des fonctions clés »`robust_control_chart(panel_data, selected_count)`
Objectif : Identifie les anomalies dans l’utilisation des services en utilisant une régression robuste et des limites de contrôle basées sur le MAD.
Entrées :
panel_data: Données de séries temporelles pour une combinaison spécifique indicateur-géographieselected_count: Nom de la colonne contenant les comptes de volume de services à analyser
Processus :
- Ajuste un modèle linéaire robuste (en utilisant
MASS::rlm()) avec des contrôles saisonniers et des tendances temporelles - Applique un lissage de la médiane roulante aux valeurs prédites pour réduire le bruit
- Calcule les résidus et les normalise en utilisant l’écart absolu médian (MAD)
- Applique une logique d’étiquetage basée sur des règles pour identifier les différents types de perturbations
- Signale automatiquement les mois récents afin d’assurer une détection rapide
Résultats :
count_predict: Prédiction du volume de services à partir d’une régression robustecount_smooth: Prédictions lissées à l’aide de la médiane roulanteresidual: Différence entre les valeurs réelles et les valeurs lisséesrobust_control: Résidu standardisé (résidu/MAD)tagged: Indicateur binaire (1 = perturbation détectée, 0 = variation normale)- Drapeaux supplémentaires :
tag_sharp,tag_sustained,tag_sustained_dip,tag_sustained_rise,tag_missing
Caractéristiques clés :
- Traite les données manquantes avec élégance grâce à l’interpolation
- Utilise une régression robuste pour minimiser l’influence des valeurs aberrantes
- Utilise plusieurs règles de détection des perturbations pour différents modèles
- Assure des prédictions non négatives (les comptes ne peuvent pas être négatifs)
Modèles de régression par panel
Section intitulée « Modèles de régression par panel »L’analyse des perturbations utilise des modèles de régression en panel (fixest::feols()) à plusieurs niveaux géographiques. Des régressions distinctes sont effectuées pour chaque unité géographique à chaque niveau, avec des erreurs types groupées pour tenir compte de la corrélation à l’intérieur de la zone.
Modèle national (admin_area_1) :
count ~ date + factor(month) + taggedRégression unique sur l’ensemble des établissements, avec erreurs standard groupées au niveau du district (admin_area_3) lorsque plus d’un district est disponible ; sinon, sans regroupement.
Modèles au niveau de la province (admin_area_2) :
count ~ date + factor(month) + taggedRégression séparée pour chaque province, avec erreurs standard groupées au niveau du district lorsque plus d’un district est disponible ; sinon, sans regroupement.
Modèles au niveau du district (admin_area_3 - optionnel) :
count ~ date + factor(month) + taggedRégression séparée pour chaque district (minimum 10 observations requises), avec erreurs standard groupées au niveau du quartier (admin_area_4) lorsque plus d’un quartier est disponible ; sinon, sans regroupement.
Modèles au niveau du quartier (admin_area_4 - optionnel) :
count ~ date + factor(month) + taggedRégression séparée pour chaque quartier/unité finale (minimum 8 observations requises, pas de regroupement).
Fonctions de soutien
Section intitulée « Fonctions de soutien »mem_usage(msg) : Suivi et enregistrement de la consommation de mémoire tout au long de l’exécution
Traitement des données :
- Traitement par lots avec des fichiers temporaires sur disque pour une meilleure efficacité de la mémoire
- Opérations data.table efficaces pour les grands ensembles de données
- Stratégies d’agrégation et de fusion progressives
Méthodes et algorithmes statistiques
Section intitulée « Méthodes et algorithmes statistiques »Analyse des cartes de contrôle
Les volumes de services sont agrégés au niveau géographique spécifié (configurable via CONTROL_CHART_LEVEL). Le pipeline supprime les valeurs aberrantes (outlier_flag == 1), complète les mois manquants et filtre les mois à faible volume (<50% du volume moyen global).
Un modèle de régression robuste estime les volumes de services attendus par indicateur × zone géographique (panelvar). Une médiane roulante centrée est appliquée pour lisser les valeurs prédites. Les résidus (réels - lissés) sont normalisés à l’aide de MAD. Les perturbations sont identifiées à l’aide d’un système de marquage basé sur des règles.
Règles de détection des perturbations
Section intitulée « Règles de détection des perturbations »Chaque règle est contrôlée par des paramètres définis par l’utilisateur, ce qui permet de personnaliser la sensibilité et le comportement de la logique de détection :
Perturbations brutales : Signale un mois unique lorsque le résidu standardisé (résidu divisé par MAD) dépasse un seuil :
$$ \left| \frac{\text{residual}}{\text{MAD}} \right| \geq \text{MADS_THRESHOLD} $$
- Paramètre :
MADS_THRESHOLD(par défaut :1.5) - Des valeurs plus faibles rendent la détection plus sensible aux pics ou aux creux soudains.
Chutes soutenues : Signale une baisse soutenue si :
- Trois mois consécutifs présentent de légères déviations (résidu standardisé >= 1 mais <
MADS_THRESHOLD), et - Le mois en cours a un résidu standardisé >= 1,5 (seuil codé en dur).
Cela permet de capter les baisses plus lentes et composées.
Baisses soutenues : Signale les périodes où le volume réel tombe constamment en dessous d’une proportion définie du volume attendu (prédiction lissée) :
$$ \text{count_original} < \text{DIP_THRESHOLD} \times \text{count_smooth} $$
- Paramètre :
DIP_THRESHOLD(par défaut :0.90) - Les utilisateurs peuvent ajuster ce paramètre pour détecter des baisses plus ou moins importantes (par exemple,
0.80pour une baisse de 20%).
Hausses soutenues : Symétrique aux baisses, signale les périodes de surperformance constante :
$$ \text{count_original} > \text{RISE_THRESHOLD} \times \text{count_smooth} $$
- Paramètre :
RISE_THRESHOLD(par défaut :1 / DIP_THRESHOLD, par exemple,1.11) - Les utilisateurs peuvent ajuster ce paramètre pour détecter les hausses de volume.
Données manquantes : Ce code est utilisé lorsque 2 mois ou plus sur les 3 derniers mois ont un volume de service manquant (NA) ou nul.
- Règle fixe.
Dérogation pour la période récente : Marquage automatique de tous les mois des 6 derniers mois de données pour s’assurer que les tendances récentes sont examinées, même si le marquage basé sur un modèle n’est pas concluant.
- Règle fixe.
Indicateur final : Un mois se voit attribuer tagged = 1 si l’une des conditions suivantes est remplie :
tag_sharp == 1tag_sustained == 1tag_sustained_dip == 1tag_sustained_rise == 1tag_missing == 1- Il se situe dans les 6 mois les plus récents (
last_6_months == 1)
Modèle de régression robuste
Section intitulée « Modèle de régression robuste »Ajustement du modèle :
Si >= 12 observations et > 12 dates uniques :
$$Y_{it} = \beta_0 + \sum \gamma_m \cdot \text{month}m + \beta_1 \cdot \text{date} + \epsilon{it}$$
S’il n’y a que >= 12 observations :
$$Y_{it} = \beta_0 + \beta_1 \cdot \text{date} + \epsilon_{it}$$
Si les données sont insuffisantes : utiliser la médiane des valeurs observées.
Appliquer le lissage de la médiane roulante aux prédictions :
$$ \text{count_smooth}{it} = \text{Median}(\text{count_predict}{t-k}, \dots, \text{count_predict}t, \dots, \text{count_predict}{t+k}) $$
- Paramètre :
SMOOTH_K(par défaut : 7, doit être impair) - Un
SMOOTH_Kplus grand lisse davantage ; un plus petit retient plus de variations.
Calculer les résidus :
$$ \text{residual}{it} = \text{count_original}{it} - \text{count_smooth}_{it} $$
Standardiser les résidus à l’aide de MAD :
$$ \text{robust_control}{it} = \text{residual}{it} / \text{MAD}_i $$
Modèles de régression pour l’analyse des perturbations
Section intitulée « Modèles de régression pour l’analyse des perturbations »Une fois les anomalies identifiées et enregistrées dans M3_chartout.csv, l’analyse des perturbations quantifie leur impact à l’aide de modèles de régression. Ces modèles estiment dans quelle mesure l’utilisation des services a changé au cours des périodes de perturbation signalées en tenant compte des tendances à long terme et des variations saisonnières.
Pour chaque indicateur, nous estimons :
$$ Y_{it} = \beta_0 + \beta_1 \cdot \text{date} + \sum_{m=1}^{12} \gamma_m \cdot \text{month}m + \beta_2 \cdot \text{tagged} + \epsilon{it} $$
où :
- $Y_{it}$ est le volume de service observé,
- $\text{date}$ capture les tendances temporelles,
- $\text{month}_m$ contrôle la saisonnalité,
- $\text{tagged}$ est la variable fictive de perturbation (issue de l’analyse de la carte de contrôle),
- $\epsilon_{it}$ est le terme d’erreur.
Le coefficient de tagged ($\beta_2$) mesure le changement relatif de l’utilisation des services pendant les perturbations signalées. Des régressions distinctes sont effectuées aux niveaux national, provincial et du district afin d’évaluer l’impact à différentes échelles géographiques.
Régression à l’échelle nationale
Section intitulée « Régression à l’échelle nationale »La régression à l’échelle nationale permet d’estimer l’évolution de l’utilisation des services au niveau national lorsqu’une perturbation se produit. Au lieu d’analyser séparément les provinces ou les districts, ce modèle prend en compte l’ensemble des données du pays dans une seule régression. Les erreurs sont regroupées au niveau géographique le plus bas disponible (lowest_geo_level), généralement les districts.
Spécification du modèle :
$$Y_{it} = \beta_0 + \beta_1 \cdot \text{date} + \sum_{m=1}^{12} \gamma_m \cdot \text{month} + \beta_2 \cdot \text{tagged} + \epsilon_{it}$$
Où :
- $Y_{it}$ = volume (par exemple, nombre d’accouchements)
- $\text{date}$ = tendance temporelle
- $\text{month}_m$ = contrôle de la saisonnalité (variable factorielle)
- $\text{tagged}$ = variable muette pour la période de perturbation
- $\epsilon_{it}$ = terme d’erreur, regroupé au niveau du district (
admin_area_3)
Régression au niveau de la province
Section intitulée « Régression au niveau de la province »La régression des perturbations au niveau de la province permet d’estimer comment l’utilisation des services change au niveau de la province lorsqu’une perturbation se produit. Contrairement au modèle national, cette approche utilise des régressions distinctes pour chaque province afin de saisir les variations régionales.
Spécification du modèle (exécuté séparément pour chaque province) :
$$Y_{it} = \beta_0 + \beta_1 \cdot \text{date} + \sum_{m=1}^{12} \gamma_m \cdot \text{month} + \beta_2 \cdot \text{tagged} + \epsilon_{it}$$
Où :
- $Y_{it}$ = volume (par exemple, nombre d’accouchements)
- $\text{date}$ = tendance temporelle
- $\text{month}_m$ = contrôle de la saisonnalité (variable factorielle)
- $\text{tagged}$ = variable muette pour la période de perturbation
- $\epsilon_{it}$ = terme d’erreur, regroupé au niveau du district
Régression au niveau du district
Section intitulée « Régression au niveau du district »La régression des perturbations au niveau du district permet d’estimer comment l’utilisation des services change au niveau du district lorsqu’une perturbation se produit. Cette approche consiste à effectuer des régressions distinctes pour chaque district afin de saisir les variations localisées.
Spécification du modèle (exécutée séparément pour chaque district) :
$$Y_{it} = \beta_0 + \beta_1 \cdot \text{date} + \sum_{m=1}^{12} \gamma_m \cdot \text{month} + \beta_2 \cdot \text{tagged} + \epsilon_{it}$$
Où :
- $Y_{it}$ = volume (par exemple, nombre d’accouchements)
- $\text{date}$ = tendance temporelle
- $\text{month}_m$ = contrôle de la saisonnalité (variable factorielle)
- $\text{tagged}$ = variable muette pour la période de perturbation
- $\epsilon_{it}$ = terme d’erreur, regroupé au niveau du quartier (
admin_area_4) si plusieurs regroupements sont disponibles
Résultats de la régression
Section intitulée « Résultats de la régression »Chaque niveau de régression produit les résultats suivants :
Valeurs attendues (expect_admin_area_*) : Volume de service prédit, ajusté pour tenir compte de la saisonnalité et des tendances.
Effet de perturbation (b_admin_area_*) : Estimation de la variation relative en cas de perturbations :
$$ b_{\text{admin_area_*}} = -\frac{\text{diff mean}}{\text{predict mean}} $$
Coefficient de tendance (b_trend_admin_area_*) : Reflète la tendance à long terme.
- Positif = augmentation de l’utilisation des services
- Négatif = baisse de l’utilisation des services
- Proche de zéro = tendance stable
P-value (p_admin_area_*) : Mesure la signification statistique de l’effet de perturbation.
- Des valeurs plus faibles = une preuve plus forte d’une véritable perturbation
Méthodes statistiques utilisées
Section intitulée « Méthodes statistiques utilisées »Régression robuste (MASS::rlm) :
- Utilise les moindres carrés repondérés de manière itérative (IRLS)
- Minimise l’influence des valeurs aberrantes et extrêmes
- Plus résistant à la mauvaise spécification du modèle que les moindres carrés ordinaires
- Par défaut : pondération de Huber avec un maximum de 100 itérations
MAD (écart absolu médian) :
- Mesure robuste de l’échelle/variabilité
- Formule :
MAD = median(|x - median(x)|) - Plus résistant aux valeurs aberrantes que l’écart-type
- Utilisé pour normaliser les résidus dans le cadre de la détection d’anomalies
Régression par panel (fixest::feols) :
- Estimation à effets fixes avec erreurs types groupées
- Tient compte de la corrélation des erreurs au sein du groupe
- Plus efficace que les packages traditionnels de régression en panel
- Traite gracieusement les panels déséquilibrés
Regroupement géographique :
- Les régressions utilisent des erreurs standard groupées au niveau géographique le plus bas disponible
- Cela permet de tenir compte de la corrélation entre les modèles de prestation de services à l’intérieur d’une même zone
- Exemple : Le modèle national est regroupé par district, le modèle provincial est regroupé par district
- Évite la sous-estimation des erreurs types et les faux positifs
Étapes de l’analyse détaillée
Section intitulée « Étapes de l’analyse détaillée »Partie 1 : Analyse des cartes de contrôle
Étape 1 : Préparer les données
Section intitulée « Étape 1 : Préparer les données »- Chargez les volumes de services ajustés à partir de
M2_adjusted_data.csv. - Charger les indicateurs de valeurs aberrantes à partir de
M1_output_outliers.csv. - Charger les données brutes du SIGS uniquement pour extraire la consultation
facility_id → admin_area_1(puis les rejeter). - Fusionner les indicateurs de valeurs aberrantes dans les données ajustées par établissement × indicateur × mois.
- Supprimer les lignes marquées comme aberrantes (
outlier_flag == 1). - Créer une variable
dateà partir deperiod_idet extraireyearetmonth. - Créer un
panelvarunique pour chaque combinaison zone géographique-indicateur. - Agréger les données au niveau géographique spécifié en additionnant les
count_model(sur la base duSELECTEDCOUNT) par date. - Compléter les mois manquants au sein de chaque panel pour assurer la continuité.
- Remplir les métadonnées manquantes à l’aide d’un remplissage en avant et en arrière.
Étape 2 : Filtrer les mois à faible volume
Section intitulée « Étape 2 : Filtrer les mois à faible volume »- Calculer le volume moyen global de services pour chaque
panelvar. - Si le
count_originalest < 50% de la moyenne globale, abandonner la valeur en la mettant àNA.
Étape 3 : Appliquer la régression et le lissage
Section intitulée « Étape 3 : Appliquer la régression et le lissage »Estimez le volume de service attendu à l’aide d’une régression robuste, puis lissez la tendance prédite.
- Ajuster la régression robuste (
rlm) pour chaque panel en utilisant l’une des trois spécifications du modèle en fonction de la disponibilité des données. - Appliquer le lissage de la médiane glissante aux prédictions en utilisant la taille de fenêtre
SMOOTH_K. - Si le lissage n’est pas possible (par exemple, sur les bords de la série), revenir aux prédictions du modèle.
- Calculer les résidus : réel - lissé
- Normaliser les résidus à l’aide de MAD
Cette variable de contrôle normalisée est utilisée pour détecter les anomalies à l’étape 4.
Étape 4 : Identifier les perturbations
Section intitulée « Étape 4 : Identifier les perturbations »Appliquer un marquage basé sur des règles pour identifier les perturbations potentielles. Chaque règle est régie par des paramètres définis par l’utilisateur et dont la sensibilité peut être ajustée :
- Perturbations nettes : Marquer si
|robust_control| >= MADS_THRESHOLD - Baisses prolongées : Marquer si 3 mois consécutifs ont des déviations légères (résidu >= 1 mais < MADS_THRESHOLD) et si le mois en cours a un résidu >= 1.5
- Baisses soutenues : Marquer toute la séquence si
count_original < DIP_THRESHOLD × count_smoothpendant 3+ mois - Hausse soutenue : Marquer toute la séquence si
count_original > RISE_THRESHOLD × count_smoothpendant 3+ mois - Données manquantes : Marquer si 2+ des 3 derniers mois sont manquants ou zéro
- Dérogation pour la période récente : Marquer automatiquement tous les mois des 6 derniers mois de données
Un mois se voit attribuer tagged = 1 si l’une des conditions ci-dessus est remplie. Les enregistrements marqués sont sauvegardés dans M3_chartout.csv et transmis à l’analyse des perturbations.
Partie 2 : Analyse des perturbations
Étape 1 : Préparation des données
Section intitulée « Étape 1 : Préparation des données »- L’ensemble de données
M3_chartoutest fusionné avec l’ensemble de données principal pour intégrer la variabletagged, qui identifie les perturbations signalées. - Le niveau géographique le plus bas disponible (
lowest_geo_level) est identifié pour le regroupement, sur la base de la colonneadmin_area_*de la plus haute résolution disponible.
Étape 2 : Régression au niveau national
Section intitulée « Étape 2 : Régression au niveau national »Pour chaque indicator_common_id, estimer le modèle au niveau national avec les erreurs regroupées au niveau du district.
- Un modèle de régression en panel est appliqué au niveau national, estimant le volume de services attendu (
expect_admin_area_1) pour chaque indicateur. - Le modèle contrôle les tendances à long terme et les modèles saisonniers d’utilisation des services.
- Lorsqu’une perturbation (
tagged = 1) est identifiée, les volumes de services prévus sont ajustés en supprimant l’effet estimé de la perturbation afin d’isoler son impact.
Étape 3 : Régression intermédiaire au niveau infranational
Section intitulée « Étape 3 : Régression intermédiaire au niveau infranational »Pour chaque combinaison indicator_common_id × admin_area_2, des modèles infranationaux sont estimés, avec des erreurs standard regroupées à un niveau administratif inférieur.
- Un modèle de régression en panel à effets fixes est appliqué à un niveau infranational intermédiaire, estimant les volumes de service attendus (
expect_admin_area_2) tout en tenant compte des caractéristiques géographiques invariantes dans le temps. - Le modèle contrôle les tendances historiques et la saisonnalité.
- Lorsqu’une perturbation est identifiée, les volumes prédits sont ajustés pour isoler l’effet de la perturbation.
Étape 4 : Régression fine au niveau infranational (si RUN_DISTRICT_MODEL = TRUE)
Section intitulée « Étape 4 : Régression fine au niveau infranational (si RUN_DISTRICT_MODEL = TRUE) »Pour chaque combinaison indicator_common_id × admin_area_3, des modèles infranationaux sont estimés, avec des erreurs standard regroupées au niveau du quartier (admin_area_4) lorsque plus d’un quartier est disponible.
- Un modèle de régression en panel à effets fixes est appliqué à un niveau infranational fin, estimant les volumes de service attendus (
expect_admin_area_3). - Les panels comportant moins de 10 observations sont ignorés.
- Le modèle contrôle les tendances historiques et la saisonnalité.
- Lorsqu’une perturbation est identifiée, les volumes prédits sont ajustés pour isoler l’effet de la perturbation.
Étape 5 : Régression au niveau du quartier (si RUN_ADMIN_AREA_4_ANALYSIS = TRUE)
Section intitulée « Étape 5 : Régression au niveau du quartier (si RUN_ADMIN_AREA_4_ANALYSIS = TRUE) »Pour chaque combinaison indicator_common_id × admin_area_4, des modèles au niveau du quartier sont estimés, sans regroupement.
- Un modèle de régression en panel est appliqué au niveau géographique le plus fin, estimant les volumes de service attendus (
expect_admin_area_4). - Les panels comportant moins de 8 observations sont ignorés.
- Le modèle contrôle les tendances historiques et la saisonnalité.
- Lorsqu’une perturbation est identifiée, les volumes prédits sont ajustés pour isoler l’effet de la perturbation.
Étape 6 : Préparer les résultats pour la visualisation
Section intitulée « Étape 6 : Préparer les résultats pour la visualisation »Une fois que les valeurs attendues ont été calculées pour chaque niveau (pays, province, district), le pipeline compare les valeurs prédites et les valeurs réelles pour évaluer l’ampleur de la perturbation.
Pour chaque mois et chaque indicateur, le pipeline calcule :
- La différence absolue et en pourcentage entre les valeurs prévues et les valeurs réelles :
$$ \text{diff_percent} = 100 \times \frac{\text{predicted} - \text{actual}}{\text{predicted}} $$
-
Un paramètre de seuil configurable
DIFFPERCENT(par défaut :10) est utilisé pour déterminer si une perturbation est significative.Si la différence en pourcentage dépasse ±10%, la valeur attendue (prédite) est conservée et utilisée pour le tracé et les statistiques récapitulatives. Dans le cas contraire, c’est la valeur réelle observée qui est utilisée.
Cela permet d’éviter que des fluctuations mineures n’entraînent des perturbations artificielles dans la visualisation, tout en préservant les écarts significatifs.
-
La valeur finale ajustée pour le tracé est stockée dans un champ tel que
count_expected_if_above_diff_threshold.Cette valeur reflète soit :
- Le nombre prédit (si l’écart est supérieur au seuil), ou
- Le comptage réel (s’il se situe dans une fourchette acceptable).
Cette logique est appliquée de manière cohérente à tous les niveaux d’administration. Ces valeurs ajustées sont ensuite exportées dans le cadre des fichiers de sortie finaux pour chaque niveau.
Exemples de code
Section intitulée « Exemples de code »Exemple 1 : Exécution du module avec les paramètres par défaut
# Set working directorysetwd("/path/to/module/directory")
# Load required librarieslibrary(data.table)library(lubridate)library(zoo)library(MASS)library(fixest)library(stringr)library(dplyr)library(tidyr)
# Configure countryCOUNTRY_ISO3 <- "SLE"PROJECT_DATA_HMIS <- "hmis_SLE.csv"
# Use default settings (admin_area_2 level analysis)RUN_DISTRICT_MODEL <- FALSERUN_ADMIN_AREA_4_ANALYSIS <- FALSE
# Run the modulesource("03_module_service_utilization.R")Avec les paramètres par défaut, le module exécute l’analyse de la carte de contrôle au niveau admin_area_2 et produit des estimations de perturbations pour les niveaux national et régional.
Exemple 2 : Ajustement de la sensibilité de la détection des perturbations
# Make disruption detection more sensitive (lower thresholds)MADS_THRESHOLD <- 1.0 # Flag at 1 MAD (default: 1.5)DIP_THRESHOLD <- 0.95 # Flag if <95% of expected (default: 0.90)SMOOTH_K <- 5 # Smaller smoothing window (default: 7)
# Make disruption detection less sensitive (higher thresholds)MADS_THRESHOLD <- 2.0 # Flag only at 2 MADsDIP_THRESHOLD <- 0.80 # Flag only if <80% of expectedSMOOTH_K <- 9 # Larger smoothing window
source("03_module_service_utilization.R")Cas d’utilisation : Ajuster la sensibilité en fonction de la qualité des données. Les données plus bruyantes peuvent nécessiter des seuils moins sensibles pour éviter les faux positifs.
Exemple 3 : Exécution d'une analyse au niveau du district
# Enable district-level analysis (slower but more detailed)RUN_DISTRICT_MODEL <- TRUERUN_ADMIN_AREA_4_ANALYSIS <- FALSE
source("03_module_service_utilization.R")Cas d’utilisation : Lorsque des modèles de perturbation au niveau du district sont nécessaires pour la planification de programmes infranationaux.
Remarque : L’analyse au niveau du district augmente considérablement la durée d’exécution. Pour les pays de grande taille, il est possible d’envisager une exécution pendant la nuit.
Exemple 4 : Sélection d'un scénario d'ajustement pour l'analyse
# Use unadjusted data for sensitivity analysisSELECTEDCOUNT <- "count_final_none"VISUALIZATIONCOUNT <- "count_final_none"
# Use outlier-adjusted onlySELECTEDCOUNT <- "count_final_outliers"VISUALIZATIONCOUNT <- "count_final_outliers"
# Use fully adjusted data (default)SELECTEDCOUNT <- "count_final_both"VISUALIZATIONCOUNT <- "count_final_both"
source("03_module_service_utilization.R")Cas d’utilisation : Comparer les estimations de perturbations entre différents scénarios d’ajustement de la qualité des données.
Exemple 5 : Optimisation de la mémoire pour les grands ensembles de données
# Reduce batch sizes for memory-constrained environmentsBATCH_SIZE_CC <- 50 # Control chart batches (default: 100)BATCH_SIZE_IND <- 3 # Indicator batches (default: 5)BATCH_SIZE_PROV <- 10 # Province batches (default: 20)BATCH_SIZE_DIST <- 10 # District batches (default: 15)
# Disable memory-intensive analysesRUN_DISTRICT_MODEL <- FALSERUN_ADMIN_AREA_4_ANALYSIS <- FALSE
source("03_module_service_utilization.R")Cas d’utilisation : Exécution sur des machines avec une RAM limitée (<8GB).
Exemple 6 : Utilisation programmatique des sorties
# Load disruption analysis outputsdisruptions_national <- read.csv("M3_disruptions_analysis_admin_area_1.csv")shortfalls_national <- read.csv("M3_all_indicators_shortfalls_admin_area_1.csv")
# Calculate total service shortfall by indicatorannual_shortfalls <- shortfalls_national %>% mutate(year = period_id %/% 100) %>% group_by(indicator_common_id, year) %>% summarise( total_expected = sum(count_expect_sum, na.rm = TRUE), total_actual = sum(count_sum, na.rm = TRUE), total_shortfall = sum(shortfall_absolute, na.rm = TRUE), avg_shortfall_pct = mean(shortfall_percent, na.rm = TRUE), .groups = "drop" )
# Identify months with largest disruptionsworst_months <- shortfalls_national %>% filter(shortfall_percent > 10) %>% arrange(desc(shortfall_percent)) %>% head(20)
# Load control chart results for detailed analysiscontrol_chart <- read.csv("M3_chartout.csv")
# Count tagged periods by indicatortagged_summary <- control_chart %>% group_by(indicator_common_id) %>% summarise( total_periods = n(), tagged_periods = sum(tagged, na.rm = TRUE), pct_tagged = 100 * tagged_periods / total_periods, .groups = "drop" )Dépannage
Section intitulée « Dépannage »Problèmes courants et solutions
Problème : Le script se bloque avec l’erreur “out of memory” (manque de mémoire)
Section intitulée « Problème : Le script se bloque avec l’erreur “out of memory” (manque de mémoire) »Solutions :
- Réduire la taille des lots (par exemple,
BATCH_SIZE_IND <- 3) - Définir
RUN_DISTRICT_MODEL <- FALSE - Définir
RUN_ADMIN_AREA_4_ANALYSIS <- FALSE - Fermer les autres applications
- Exécuter sur une machine avec plus de RAM
Problème : Avertissement “le modèle n’a pas réussi à converger”
Section intitulée « Problème : Avertissement “le modèle n’a pas réussi à converger” »Explication : La régression robuste n’a pas complètement convergé dans les 100 itérations
Impact : Généralement minime - une convergence partielle est souvent suffisante
Solutions :
- Vérifier la qualité des données pour ce panel
- Augmenter le paramètre
maxitdans l’appelrlm()(ligne 229, 247) - Il est généralement possible de l’ignorer si seuls quelques panels sont concernés
Problème : Nombreuses lignes vides dans les fichiers de sortie
Section intitulée « Problème : Nombreuses lignes vides dans les fichiers de sortie »Explication : Données insuffisantes pour certaines combinaisons indicateur-géographie
Solutions :
- Comportement attendu pour les indicateurs peu nombreux
- Filtrer les sorties sur les valeurs non manquantes
- Envisager l’agrégation à un niveau géographique plus élevé
Problème : Tous les mois récents sont signalés comme perturbations
Section intitulée « Problème : Tous les mois récents sont signalés comme perturbations »Explication : Marquage automatique des 6 derniers mois
But : Permet d’examiner les tendances récentes, même en l’absence de preuves statistiques solides
Solutions :
- Comportement attendu, pas un bogue
- Examiner les mois récents manuellement
- Ajuster la logique
last_6_monthssi nécessaire (ligne 333)
Problème : la variable tagged a été supprimée de la régression
Section intitulée « Problème : la variable tagged a été supprimée de la régression »Message : La variable est automatiquement mise à 0
Explication : Aucune variation de tagged dans ce panneau (tout 0 ou tout 1)
Solutions :
- Attendu dans les panels sans perturbations ou avec des perturbations constantes
- Il ne s’agit pas d’une erreur - l’effet de perturbation est correctement fixé à 0
Problème : Des fichiers temporaires subsistent après l’exécution
Section intitulée « Problème : Des fichiers temporaires subsistent après l’exécution »Cause : Le script s’est arrêté avant le nettoyage
Solutions :
- Supprimer manuellement :
M3_temp_*.csv - Ou réexécuter le script (nettoyage automatique au démarrage)
Problème : Résultats très différents selon le niveau géographique
Section intitulée « Problème : Résultats très différents selon le niveau géographique »Explication : Des agrégations géographiques différentes permettent de saisir des modèles différents
Exemple : La tendance nationale peut être stable alors que certains districts connaissent d’importantes perturbations
Solutions :
- Comportement attendu - ce n’est pas un bogue
- Utiliser le niveau approprié pour votre question de recherche
- Recouper les modèles entre les différents niveaux pour en vérifier la robustesse
Notes d’utilisation
Section intitulée « Notes d’utilisation »Directives d'interprétation
Effets de perturbation (b_admin_area_*) :
- Les valeurs négatives indiquent des déficits de volume de service pendant les périodes de perturbation
- Les valeurs positives indiquent des excédents de volume de service pendant les périodes de perturbation
- Les valeurs proches de zéro indiquent des effets de perturbation moindres
Valeurs P (p_admin_area_*) :
- Les valeurs < 0,05 indiquent des perturbations statistiquement significatives
- Les valeurs > 0,05 peuvent indiquer une variation normale plutôt que de véritables perturbations
Coefficients de tendance (b_trend_admin_area_*) :
- Les valeurs positives indiquent une augmentation de l’utilisation des services au fil du temps
- Les valeurs négatives indiquent une diminution de l’utilisation des services au fil du temps
- Les valeurs proches de zéro indiquent des schémas d’utilisation stables
Considérations sur les performances
Section intitulée « Considérations sur les performances »Facteurs de temps de fonctionnement :
- Nombre d’indicateurs : Mise à l’échelle linéaire
- Nombre d’unités géographiques : Échelle linéaire à l’intérieur de chaque niveau
- Longueur de la série temporelle : Impact minimal (régression efficace)
- Détails géographiques : Échelle exponentielle (beaucoup plus d’unités à des niveaux plus fins)
Temps d’exécution estimés (exemple de données : 50 indicateurs, 100 districts) :
- Modèles nationaux + provinciaux : ~5-10 minutes
- Ajouter des modèles de district : ~30-60 minutes
- Ajouter des modèles de quartiers : Plusieurs heures (en fonction du nombre de quartiers)
Stratégies d’optimisation :
- Définir
RUN_DISTRICT_MODEL = FALSEpour une exécution plus rapide (sauter le niveau du district) - Régler
RUN_ADMIN_AREA_4_ANALYSIS = FALSE(par défaut) pour éviter l’analyse au niveau de la circonscription - Réduire
SMOOTH_Kpour un calcul plus rapide de la médiane glissante - Utiliser
SELECTEDCOUNT = "count_final_none"pour éviter les ajustements de complétude
Détails du traitement des données
Section intitulée « Détails du traitement des données »Gestion de la mémoire :
- Utilise
data.tablepour des opérations efficaces sur de grands ensembles de données - Traitement par lots : Résultats sauvegardés sur disque périodiquement
- Nettoyage progressif : Objets supprimés lorsqu’ils ne sont plus nécessaires
- Les fichiers temporaires permettent de traiter des ensembles de données plus grands que la RAM
Taille des lots (ajustable en fonction des contraintes de mémoire) :
- Carte de contrôle : 100 panneaux par lot
- Indicateurs : 5 indicateurs par lot
- Provinces : 20 résultats par lot
- Districts : 15 résultats par lot
- Zone administrative 4 : 10 résultats par lot
Traitement des données manquantes :
- Les mois manquants sont remplis via
tidyr::complete() - Remplissage avant/arrière pour les métadonnées
- Interpolation linéaire (
zoo::na.approx) pour les valeurs de comptage - Écart maximal : Illimité (règle = 2 étend les points d’extrémité)
Logique de repli du modèle
Section intitulée « Logique de repli du modèle »L’analyse de la carte de contrôle utilise une sélection de modèle adaptative basée sur la disponibilité des données :
Modèle complet (nécessite >= 12 obs ET > 12 dates uniques) :
count ~ month_factor + as.numeric(date)Tient compte à la fois de la saisonnalité et de la tendance linéaire
Modèle tendance uniquement (nécessite >= 12 obs) :
count ~ as.numeric(date)Tient compte uniquement de la tendance linéaire (données insuffisantes pour la saisonnalité)
Retour à la médiane (< 12 observations) :
count_predict = median(count)Utilise la médiane globale lorsque les données sont insuffisantes pour la régression
Vérifications de convergence :
- Modèles dont l’état de convergence a été vérifié
- Avertissements émis pour les modèles non convergents
- Les modèles non convergents sont encore utilisés (une convergence partielle est souvent suffisante)
Assurance qualité
Section intitulée « Assurance qualité »Nettoyage des données :
- Les valeurs aberrantes ont été supprimées avant l’analyse de la carte de contrôle (sur la base des indicateurs du module 1)
- Les mois à faible volume (< 50% de la moyenne) ont été exclus pour améliorer la stabilité du modèle
- Prédictions limitées à zéro (les comptes ne peuvent pas être négatifs)
Marquage automatique :
- Les mois récents (6 derniers mois) sont automatiquement marqués pour garantir la prise en compte des perturbations actuelles
- Évite de manquer des perturbations en cours en raison d’un écart insuffisant par rapport à la tendance
Contrôles de robustesse :
- Les coefficients du modèle sont vérifiés pour les valeurs
NAavant d’être utilisés - Si la variable
taggedest éliminée du modèle (pas de variation), l’effet de perturbation est fixé à 0 - Les valeurs P ne sont calculées que si des erreurs standard valides sont disponibles
Traitement des cas limites :
- Panneaux à un seul cluster : Aucun regroupement n’est appliqué (l’analyse échouerait)
- Données insuffisantes : Sauter l’analyse pour ce panel/niveau
- Prédictions manquantes : Complétées par les valeurs originales dans la mesure du possible
Intégration du flux de travail
Section intitulée « Intégration du flux de travail »Ce module est le module 3 du pipeline analytique FASTR :
Prérequis :
- Module 1 : Évaluation de la qualité des données (génère
M1_output_outliers.csv) - Module 2 : Ajustements de la qualité des données (génère
M2_adjusted_data.csv)
Dépendances
Section intitulée « Dépendances »Packages R requis :
data.table: Manipulation efficace des donnéeslubridate: Traitement des dateszoo: Statistiques roulantes et interpolationMASS: Régression robuste (rlm)fixest: Régression de panel à effets fixesdplyr: Manipulation des donnéestidyr: Nettoyage des données
Dernière mise à jour : 06-05-2026 Contact : fastr@worldbank.org