Estimations de la couverture
Contexte et objectif
Section intitulée « Contexte et objectif »Objectif du module
Section intitulée « Objectif du module »Le module Estimations de la couverture quantifie la couverture des services de santé en intégrant les volumes de services administratifs ajustés du Système d’information sur la gestion de la santé (SIGS), les projections démographiques des Perspectives de la population mondiale des Nations unies (UN WPP) et les données d’enquêtes auprès des ménages. Le module s’appuie actuellement sur les enquêtes démographiques et de santé (EDS) et les enquêtes en grappes à indicateurs multiples (MICS), mais il est conçu pour intégrer d’autres sources d’enquêtes représentatives au niveau national dès qu’elles seront disponibles. Le module estime la part de la population cible qui a bénéficié d’un service de santé donné, fournissant ainsi une mesure standardisée de la portée des services à des fins de suivi, de comparaison et d’analyse en aval. Le module est structuré en deux composantes.
La partie 1 construit les dénominateurs de la population cible en utilisant plusieurs approches méthodologiques et évalue leur performance en comparant les estimations de couverture obtenues avec les valeurs de référence des enquêtes disponibles pour chaque indicateur de santé.
La partie 2 permet aux utilisateurs de revoir et d’ajuster les choix de dénominateurs en fonction de considérations programmatiques et d’étendre dans le temps les estimations de couverture basées sur des enquêtes en utilisant les tendances dérivées des données administratives, lorsque les données d’enquête ne sont pas disponibles.
Ensemble, ces composantes convertissent les volumes de services administratifs en estimations de couverture standardisées qui peuvent être examinées dans le temps et à différents niveaux géographiques, et utilisées dans des contextes d’analyse et de suivi.
Raison d’être de l’analyse
Section intitulée « Raison d’être de l’analyse »La couverture des services de santé est une mesure essentielle pour évaluer la performance et l’équité du système de santé. Bien que le module 2 produise des volumes de services ajustés, ces chiffres n’indiquent pas à eux seuls dans quelle mesure les services atteignent les populations qu’ils sont censés desservir. Les estimations de la couverture placent la prestation de services dans son contexte en établissant un lien entre les volumes de services et les besoins de la population.
Ce module aborde les principaux défis liés à l’estimation de la couverture, notamment :
-
Multiples sources de données : Intégration des données SIGS avec les données d’enquête
-
L’incertitude du denominateur : Differentes methodes d’estimation des populations cibles peuvent donner des resultats differents ; le module evalue systematiquement les options
-
Lacunes temporelles : Les enquêtes ont lieu tous les 3 à 5 ans ; le module projette des estimations pour les années intermédiaires en utilisant les tendances administratives
-
Analyse infranationale : Permet le suivi de la couverture au niveau national, provincial et du district
Points clés
Section intitulée « Points clés »| Composante | Détails |
|---|---|
| Entrées | M2_adjusted_data (nationales et sous-nationales) du module 2 Données d’enquête (MICS/EDS) du dépôt GitHub Données de population (UN WPP) du dépôt GitHub |
| Sorties | M5 (Partie 1) — M5_denominators (national, admin2, admin3) : populations cibles calculées · M5_combined_results (national, admin2, admin3) : estimations de couverture avec tous les dénominateurs · M5_selected_denominator_per_indicator : meilleur dénominateur par indicateur et niveau M6 (Partie 2) — M6_coverage_estimation (national, admin2, admin3) : couverture finale avec estimations SIGS, enquête et projetées |
| Identifiants des modules | Partie 1 = m005 (requiert m002) · Partie 2 = m006 (requiert m005) |
| Objectif | Estimer la couverture des services de santé en comparant les volumes de services aux populations cibles, validés par rapport aux références de l’enquête |
!!! warning “Rappel : l’entrée SIGS doit être des volumes, pas des % de couverture”
L'estimation de la couverture fonctionne en divisant le nombre de services rendus (le **volume** qui passe par les modules 1, 2 et 3) par un dénominateur de population cible que la plateforme construit elle-même. Si votre extraction SIGS d'origine contenait des taux de couverture pré-calculés au lieu de volumes de services, il n'y a rien à calculer ici — le volume est le numérateur, et la plateforme fournit le dénominateur. Voir [Extraction des données](02_data_extraction) pour savoir quoi extraire de votre SIGS.Partie 1 et partie 2 expliquées
Section intitulée « Partie 1 et partie 2 expliquées »L’estimation de la couverture est répartie entre deux modules qui s’exécutent toujours en séquence : m005 (partie 1) produit toutes les options de dénominateur, et m006 (partie 2) sélectionne une chaîne de dénominateurs et la convertit en estimations de couverture finales.
Partie 1 — m005 calcul des dénominateurs et pré-sélection de la chaîne
-
Requiert :
m002(données SIGS ajustées) -
Calcule les populations cibles (dénominateurs) à l’aide de plusieurs approches : basées sur le SIGS (à partir de CPN1, accouchement, BCG, Penta1, naissances vivantes) et basées sur la population (UN WPP)
-
Compare chaque chaîne SIGS au UN WPP et pré-sélectionne la chaîne dont le rapport médian est le plus proche de 1,0 (la chaîne
best) — il s’agit d’une seule chaîne appliquée à tous les indicateurs, et non d’un choix par indicateur -
Génère toutes les valeurs de dénominateurs, plus un fichier
M5_combined_results_*.csvpar niveau géographique contenant la couverture estimée avec chaque dénominateur disponible, la couverture de la chaînebestet les valeurs brutes de l’enquête -
Sorties :
M5_denominators_national.csv,M5_denominators_admin2.csv,M5_denominators_admin3.csv,M5_combined_results_national.csv,M5_combined_results_admin2.csv,M5_combined_results_admin3.csv,M5_selected_denominator_per_indicator.csv
Partie 2 — m006 sélection de la chaîne et projection des enquêtes
-
Requiert :
m005(M5_combined_results_*.csvpour national / admin2 / admin3) -
Un seul paramètre utilisateur
DENOMINATOR_CHAIN(auto,anc1,delivery,bcg,penta1) —autoconserve la chaîne pré-sélectionnée parm005; toute autre valeur force une chaîne unique pour tous les indicateurs et tous les niveaux géographiques -
Calcule les deltas de couverture d’une année sur l’autre à partir de la chaîne sélectionnée et projette la valeur d’enquête la plus récente vers l’avant en utilisant ces deltas (méthode additive)
-
Sorties :
M6_coverage_estimation_national.csv,M6_coverage_estimation_admin2.csv,M6_coverage_estimation_admin3.csv— chaque ligne contient côte à côte la couverture SIGS, la valeur d’enquête originale et la valeur d’enquête projetée
Flux de travail analytique
Section intitulée « Flux de travail analytique »Aperçu des étapes analytiques
Section intitulée « Aperçu des étapes analytiques »Partie 1 : Calcul et sélection du dénominateur
Section intitulée « Partie 1 : Calcul et sélection du dénominateur »Étape 1 : Chargement et préparation des sources de données Le module commence par le chargement de trois sources de données et la vérification de leur compatibilité. Les données SIGS sont agrégées des totaux mensuels aux totaux annuels. Les données d’enquête sont harmonisées (priorité aux EDS par rapport aux MICS) et complétées pour créer des séries temporelles continues. Les données sur la population sont filtrées en fonction du pays cible.
Étape 2 : Calculer les options de dénominateurs multiples Pour chaque indicateur de santé, le module calcule plusieurs populations cibles possibles :
-
Dénominateurs basés sur les services : Utilisation des volumes SIGS divisés par la couverture de l’enquête (par exemple, si 10 000 femmes ont reçu des soins prénatals1 et que l’enquête indique que la couverture est de 80 %, le nombre estimé de grossesses est de 10 000/0,80 = 12 500)
-
Dénominateurs basés sur la population : Utilisation des projections démographiques et des taux de natalité de l’ONU
-
Chaque dénominateur est ajusté en fonction de facteurs démographiques (perte de grossesse, mortinatalité, taux de mortalité) pour correspondre au groupe d’âge cible de l’indicateur
Étape 3 : Calculer la couverture pour chaque dénominateur Le module calcule la couverture en divisant le volume de services par chaque option de dénominateur. Il en résulte plusieurs estimations de couverture par indicateur, chacune basée sur une hypothèse de population différente.
Étape 4 : Pré-sélectionner une chaîne de dénominateurs unique Au niveau national, le module compare chaque chaîne SIGS (CPN1, accouchement, Penta1) aux estimations de population du UN WPP pour les mêmes populations cibles (grossesses, naissances vivantes, nourrissons éligibles au DTC). Pour chaque chaîne, il calcule le rapport médian des valeurs de la chaîne aux valeurs UN WPP, puis sélectionne la chaîne dont le rapport médian est le plus proche de 1,0. La chaîne BCG est nationale uniquement et est exclue de la comparaison automatique (elle peut toujours être forcée comme dérogation manuelle). Le UN WPP sert d’ancrage démographique indépendant, et non de “meilleure” valeur de couverture.
Étape 5 : Appliquer la chaîne à toutes les géographies La même chaîne sélectionnée au niveau national est réutilisée pour la zone administrative 2 et la zone administrative 3, garantissant qu’une seule source cohérente alimente chaque géographie. Si la chaîne est nationale uniquement (BCG), les lignes infranationales sont supprimées de cette sortie.
Étape 6 : Générer des résultats
Le module enregistre : les valeurs de dénominateurs par indicateur (M5_denominators_*.csv) ; les résultats combinés (M5_combined_results_*.csv) contenant la couverture pour chaque option de dénominateur, les entrées de la chaîne best utilisées par m006, et les valeurs brutes de l’enquête ; et un tableau récapitulatif (M5_selected_denominator_per_indicator.csv) listant le dénominateur que la chaîne attribue à chaque indicateur à chaque niveau.
Étape 7 : Répéter pour les niveaux sous-nationaux Si des données infranationales sont disponibles, le processus se répète pour les niveaux administratifs 2 (par exemple, les provinces) et 3 (par exemple, les districts), avec des mécanismes de repli pour gérer les données d’enquête locales manquantes.
Partie 2 : Sélection du dénominateur et projection de l’enquête
Section intitulée « Partie 2 : Sélection du dénominateur et projection de l’enquête »Étape 1 : Configuration par l’utilisateur
L’utilisateur définit un seul paramètre, DENOMINATOR_CHAIN. La valeur par défaut auto conserve la chaîne pré-sélectionnée par la partie 1 (les lignes best dans M5_combined_results_*.csv). Toute autre valeur (anc1, delivery, bcg, penta1) force cette chaîne unique à être utilisée pour chaque indicateur et chaque niveau géographique.
Étape 2 : Filtrer sur la chaîne sélectionnée
Le module lit M5_combined_results_*.csv et ne conserve que les lignes appartenant à la chaîne sélectionnée, en supprimant les lignes brutes survey. Cela produit une valeur de couverture par indicateur × année × géographie.
Étape 3 : Calculer les tendances de la couverture Les changements d’une année sur l’autre (deltas) dans la couverture basée sur le SIGS sont calculés. Cela permet de savoir si la couverture augmente, diminue ou est stable dans le temps.
Étape 4 : Identifier les données de référence de l’enquête Pour chaque zone géographique et chaque indicateur, l’observation la plus récente de l’enquête est identifiée comme le point d’ancrage de référence pour les projections.
Étape 5 : Projeter les estimations de l’enquête dans l’avenir Le module étend les estimations de la couverture de l’enquête aux années sans enquête en appliquant les tendances du système d’information sur les ménages. La projection utilise : La valeur de la dernière enquête + (couverture SIGS de l’année en cours - couverture SIGS de l’année de l’enquête). Cela permet de préserver le calibrage de l’enquête tout en incorporant les tendances observées.
Étape 6 : Combiner toutes les estimations Le résultat final fusionne trois types d’estimations :
-
Couverture basée sur le SIMMT : Calcul direct à partir des volumes de services et des dénominateurs sélectionnés
-
Valeurs originales de l’enquête : Observations réelles de l’enquête auprès des ménages
-
Couverture projetée de l’enquête : Estimations de l’enquête étendues à l’aide des tendances du système d’information sur les ménages
Etape 7 : Sauvegarde des resultats finaux Les resultats sont sauvegardes avec des structures de colonnes standardisées pour chaque niveau administratif, prêts pour la visualisation et les rapports.
Diagramme de flux de travail
Section intitulée « Diagramme de flux de travail »Points de décision clés
Section intitulée « Points de décision clés »1. Sélection des dénominateurs
Dans la partie 1 (m005), le module compare chaque chaîne de dénominateurs SIGS aux estimations de population UN WPP et pré-sélectionne la chaîne dont le rapport médian au UN WPP est le plus proche de 1,0. La même chaîne est ensuite appliquée à chaque indicateur et à chaque niveau géographique pour assurer la cohérence. Dans la partie 2 (m006), l’utilisateur peut conserver cette chaîne sélectionnée automatiquement ou forcer une chaîne spécifique (anc1, delivery, bcg ou penta1). Le choix détermine si les estimations de couverture sont principalement ancrées dans un ensemble de dénominateurs SIGS basés sur les services (par exemple, tout dérivé des visites CPN1) ou dans un autre (par exemple, tout dérivé des doses Penta1).
2. Traitement des écarts entre les enquêtes
Les enquêtes auprès des ménages sont menées à intervalles irréguliers, généralement tous les trois à cinq ans. Dans la partie 1, les valeurs de l’enquête sont reportées entre les années d’enquête, ce qui suppose implicitement une couverture constante jusqu’à la prochaine observation de l’enquête. Dans la partie 2, la couverture est projetée vers l’avant en utilisant les tendances dérivées des données SIGS, ce qui permet de refléter les changements dans la prestation de services au cours des périodes sans données d’enquête.
3. Utilisation de données d’enquête nationales ou infranationales
L’estimation de la couverture aux niveaux infranationaux exige à la fois des volumes de services SIGS infranationaux (issus du Module 2) et des valeurs d’enquête de référence infranationales (EDS/MICS). Le module gère les données d’entrée manquantes à deux moments distincts :
-
Aucune donnée SIGS infranationale pour le pays — lorsque
M2_adjusted_data_admin_area.csvne contient aucune ligne infranationale exploitable, ou lorsque le jeu de données unifié EDS/MICS ne comporte aucune donnée d’enquête infranationale pour le pays, la partie 1 bascule enNATIONAL_ONLYet la partie 2 détecte les fichiersM5_combined_results_*.csvadmin2/admin3 vides et saute entièrement le bloc correspondant. Dans ce cas,M6_coverage_estimation_admin2.csvet/ouM6_coverage_estimation_admin3.csvsont tout de même écrits, mais sous forme de fichiers vides ne contenant que les en-têtes de colonnes corrects. -
Données SIGS infranationales présentes, mais aucune valeur d’enquête infranationale pour un indicateur donné — le module ne substitue pas la valeur d’enquête nationale aux zones infranationales. La colonne
*carrycorrespondante reste àNApour ce triplet géographie-indicateur-année, aucun dénominateur SIGS-implicite ne peut donc être calculé pour cet indicateur à ce niveau, et l’indicateur n’apparaît tout simplement pas dans les sorties de couverture infranationales. -
La pré-sélection de la chaîne n’a pas de résultat admin2/admin3 — lorsque
m005ne parvient pas à identifier une meilleure chaîne au niveau national (aucun chevauchement entre données HMIS et UN WPP), les entrées dénominateur-par-indicateur basculent àNOT_AVAILABLE. Lorsque la chaîne sélectionnée est nationale uniquement (BCG),denominator_admin2etdenominator_admin3dansM5_selected_denominator_per_indicator.csvsont explicitement positionnés àNOT_AVAILABLEet aucune ligne infranationale n’est produite pour cette chaîne.
Les substitutions au niveau de l’indicateur dans le jeu de données d’enquête lui-même sont plus restreintes et restent en place à chaque niveau géographique : lorsque SBA est absent, le module réutilise la valeur d’enquête delivery ; lorsque pnc1_mother est absent, il réutilise la valeur d’enquête pnc1.
4. Ajustement des dénominateurs pour les populations cibles
Chaque indicateur de santé correspond à une population cible spécifique (par exemple, les femmes enceintes pour les soins prénatals ou les nourrissons pour la vaccination des enfants). Le module applique des ajustements démographiques séquentiels - tels que la perte de grossesse, la mortinatalité et la mortalité - afin d’aligner les dénominateurs sur la population cible pertinente pour chaque indicateur.
Traitement des données et résultats
Section intitulée « Traitement des données et résultats »Intégration des données
Le module intègre trois sources de données primaires : les volumes annualisés de services SIGS agrégés par unité géographique ; les estimations de la couverture de l’enquête sur les ménages harmonisées entre les cycles d’enquête et complétées pour créer des séries temporelles continues ; et les projections démographiques filtrées pour extraire les populations spécifiques à l’âge et au sexe pertinentes pour chaque indicateur de santé.
Construction du denominateur
En utilisant la relation entre les volumes de services SIGS déclarés et les estimations de couverture basées sur l’enquête, le module dérive des dénominateurs implicites SIGS représentant la taille de la population cohérente avec la prestation de services observée et les niveaux de couverture de l’enquête. Ces dénominateurs sont ensuite ajustés pour refléter les populations cibles spécifiques à l’indicateur par le biais de corrections démographiques séquentielles, y compris la perte de grossesse, la mortinatalité et la mortalité.
Calcul de la couverture
Les estimations de couverture multiples sont calculées en divisant les volumes de services par des options de dénominateur alternatives, y compris des approches basées sur la population et des approches implicites SIGS. L’erreur quadratique par rapport aux valeurs d’enquête reportées est calculée pour la transparence diagnostique, tandis que la sélection effective de la chaîne dans m005 est déterminée par la proximité au UN WPP au niveau national.
Projection temporelle
Pour les annees au-dela de l’observation la plus récente de l’enquête, les estimations de couverture sont projetées en combinant la dernière valeur observée de l’enquête avec les tendances dérivées des données SIGS.
Résultats de l’analyse et visualisation
Section intitulée « Résultats de l’analyse et visualisation »L’analyse FASTR génère des visualisations d’estimations de couverture à plusieurs niveaux géographiques :
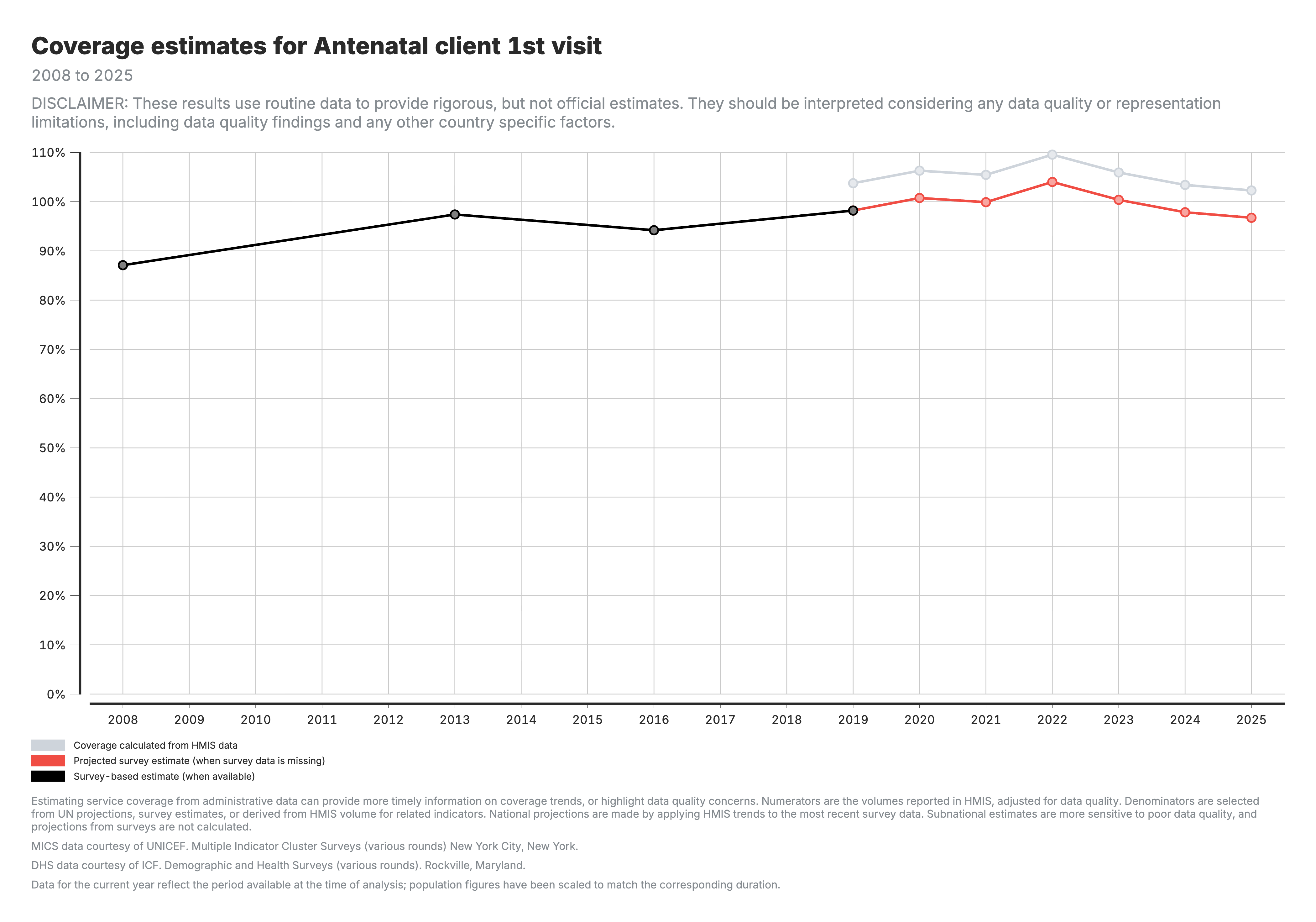
1. Couverture calculée à partir des données SIGS (national)
Tendances de la couverture au niveau national comparant les estimations dérivées du SIGS aux références de l’enquête.
2. Couverture calculée à partir des données SIGS (zone administrative 2)
Modèles de couverture à un niveau infranational intermédiaire (admin_area_2), mettant en évidence les variations géographiques dans la prestation de services entre les régions.
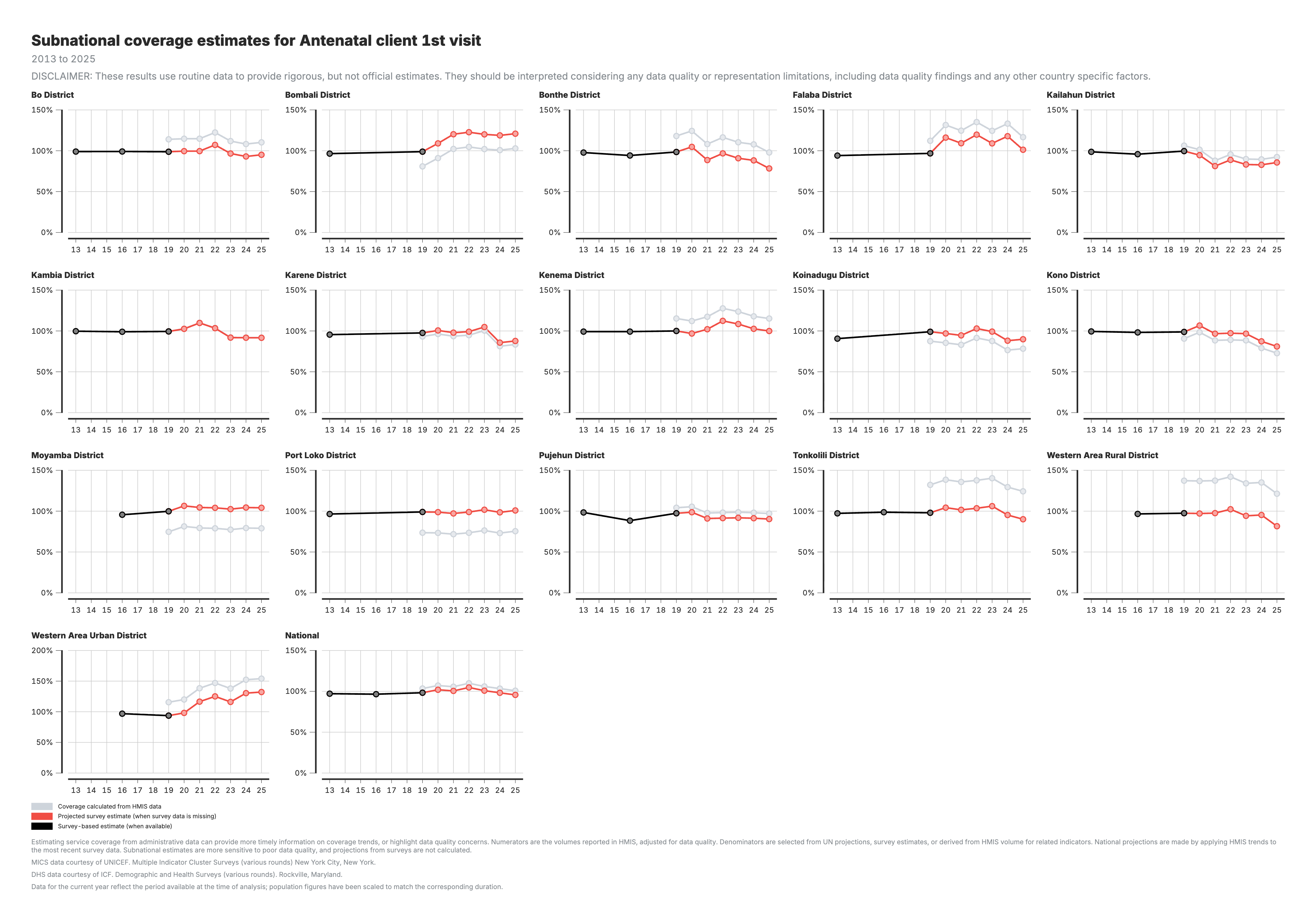
3. Couverture calculée à partir des données SIGS (zone administrative 3)
Estimations de la couverture à un niveau infranational plus fin (admin_area_3), permettant un suivi plus local et l’identification des disparités infranationales.
Guide d’interprétation
Pour tous les graphiques de couverture (sorties 1-3) :
- Ligne/points noirs : Couverture basée sur des enquêtes (EDS/MICS) - la norme de référence
- Ligne/points gris : Couverture basée sur le SIGS calculée à partir des données de l’établissement
- Ligne/points rouges : Ligne/points rouges** : Couverture projetée étendant les estimations de l’enquête en utilisant les tendances du SIGS
- Axe Y : Pourcentage de couverture (0-100%)
- Axe X : pourcentage de couverture (0-100%) Période (années)
Niveaux géographiques :
- Sortie 1 : Tendances au niveau national
- Sortie 2 : Ventilation de la zone administrative 2 (régionale/provinciale)
- Résultat 3 : Ventilation du domaine administratif 3 (district) pour le ciblage local
Référence détaillée
Section intitulée « Référence détaillée »Partie 1 : Calcul du dénominateur (détails techniques)
Section intitulée « Partie 1 : Calcul du dénominateur (détails techniques) »Paramètres de configuration
Section intitulée « Paramètres de configuration »Le module commence par plusieurs paramètres configurables qui contrôlent l’analyse :
COUNTRY_ISO3 <- "ISO3" # ISO3 country code (e.g., "RWA", "UGA", "ZMB")SELECTED_COUNT_VARIABLE <- "count_final_both" # Which adjusted count to useANALYSIS_LEVEL <- "NATIONAL_PLUS_AA2" # Geographic scopeOptions de niveau d’analyse:
NATIONAL_ONLY: Analyse au niveau national uniquementNATIONAL_PLUS_AA2: National + zone administrative 2 (par exemple, provinces)NATIONAL_PLUS_AA2_AA3: National + zone administrative 2 + zone administrative 3 (par exemple, districts)
Taux d’ajustement démographique:
PREGNANCY_LOSS_RATE <- 0.03 # 3% pregnancy lossTWIN_RATE <- 0.015 # 1.5% twin birthsSTILLBIRTH_RATE <- 0.02 # 2% stillbirthsP1_NMR <- 0.039 # Neonatal mortality rateP2_PNMR <- 0.028 # Post-neonatal mortality rateINFANT_MORTALITY_RATE <- 0.067 # Infant mortality rateUNDER5_MORTALITY_RATE <- 0.103 # Under-5 mortality rateOptions de la variable de comptage:
count_final_none: Aucun ajustement (données brutes déclarées)count_final_outliers: Ajustement des valeurs aberrantes uniquement (par défaut)count_final_completeness: Ajustement de l’exhaustivité uniquementcount_final_both: Les deux ajustements combinés
Sources des données d’entrée
Section intitulée « Sources des données d’entrée »La partie 1 intègre trois sources de données primaires :
1. Données ajustées SIGS (du module 2)
- Nationales :
M2_adjusted_data_national.csv - Sous-national :
M2_adjusted_data_admin_area.csv - Contient les volumes de services par indicateur, zone et période
2. Données d’enquête (EDS/MICS)
- Source : Dépôt GitHub (ensemble de données d’enquête unifiées) Dépôt GitHub (ensemble de données d’enquête unifiées)
- Fournit des repères de couverture pour la comparaison
- Les données de l’EDS sont privilégiées par rapport à celles des MICS lorsque les deux sont disponibles
3. Données sur la population (UN WPP)
- Source : GitHub Dépôt GitHub
- Fournit des dénominateurs basés sur la population
- Inclut la population totale, les naissances, les populations de moins de 1 an et de moins de 5 ans
Contexte de données supplémentaires:
Projections démographiques (UN WPP) Issues des Perspectives de la population mondiale des Nations unies, ces estimations fournissent des chiffres de population par âge et de population totale utilisés pour calculer les dénominateurs des estimations de couverture. Ces projections tiennent compte des tendances démographiques, notamment de la fécondité, de la mortalité et des migrations.
Données d’enquête - MICS Les MICS, menées par l’UNICEF, fournissent des estimations basées sur des enquêtes auprès des ménages pour les principaux indicateurs de santé, y compris la couverture des services de santé maternelle et infantile.
Données d’enquête - EDS Les EDS, menées par l’USAID, fournissent des données d’enquête sur l’utilisation des services de santé, y compris les taux de vaccination et la couverture des soins maternels.
Documentation sur les fonctions principales
Section intitulée « Documentation sur les fonctions principales »`process_hmis_adjusted_volume()`
Objectif : Préparer les données SIGS pour le calcul du dénominateur
Entrée :
- Données de volume ajustées du module 2
- Variable de comptage sélectionnée (par exemple,
count_final_both)
Traitement :
- Agrégation des données mensuelles en totaux annuels
- Compte le nombre de mois de déclaration par an
- Pivote les données en format large (une colonne par indicateur)
Résultat :
annual_hmis: Dénombrement annuel des services par zone et par annéehmis_countries: Liste des pays dans l’ensemble de donnéeshmis_iso3: Code(s) ISO3 présent(s)
Exemple de structure :
admin_area_1 admin_area_2 year countanc1 countdelivery ... nummonthCountry_Name Province_A 2020 12500 10200 ... 12Country_Name Province_A 2021 13000 10500 ... 11`process_survey_data()`
Objectif : Harmoniser et étendre les données d’enquête pour les utiliser comme points de référence en matière de couverture
Entrée :
- Données d’enquête (EDS/MICS)
- Noms des pays SIGS et codes ISO3
- Référence nationale facultative (pour le repli sous-national)
Principales étapes du traitement :
-
Harmonisation
- Recodage des noms d’indicateurs (par exemple,
polio1→opv1,vitamina→vitaminA) - Normalise les étiquettes des sources (
dhs,mics) - Filtre par pays et par date
- Recodage des noms d’indicateurs (par exemple,
-
Hiérarchisation des sources
- Lorsqu’il existe à la fois des EDS et des MICS pour la même année/zone/indicateur
- L’EDS est sélectionnée de préférence
- Préserve les détails de la source pour plus de transparence
-
Logique de repli
- Si
sbamanque, utilise les valeurs dedelivery - Si
pnc1_mothermanque, utilise les valeurs depnc1 - Aux niveaux infranationaux, les valeurs d’enquête manquantes pour un indicateur restent à
NA— aucune valeur nationale n’est substituée (les lacunes sont rapportées dans le journal d’exécution par indicateur)
- Si
-
Remplissage en amont
- Crée des séries chronologiques complètes pour chaque zone
- Reporte la dernière valeur observée (
na.locf) - Crée des colonnes de report (par exemple,
anc1carry,bcgcarry)
Sortie :
carried: Données d’enquête étendues avec des valeurs remplies à l’avanceraw: Observations brutes de l’enquête (format large)raw_long: Observations brutes de l’enquête (format long) avec détails de la source
`process_national_population_data()`
Objectif : Préparer les estimations de la population du WPP de l’ONU pour le calcul du dénominateur
Entrée :
- Estimations de la population (UN WPP)
- Identifiants du pays SIGS
Traitement :
- Filtre au niveau national et au pays cible
- Extrait les indicateurs clés de la population :
crudebr_unwpp: Taux brut de natalitépoptot_unwpp: Population totaletotu1pop_unwpp: Population de moins de 1 an
Sortie :
wide: Indicateurs de population en format largeraw_long: Données démographiques en format long avec suivi des sources
`calculate_denominators()`
Objectif : Calcule tous les dénominateurs possibles à partir des données du système d’information sur les ménages et de la population. Il s’agit de la fonction principale qui génère des estimations de dénominateurs multiples.
Entrée :
hmis_data: Dénombrement annuel des servicessurvey_data: Valeurs de référence de l’enquête (reportées)population_data: Estimations WPP de l’ONU (uniquement au niveau national)
Types de dénominateurs calculés :
A. Dénominateurs basés sur les services (en utilisant le numérateur SIGS ÷ la couverture de l’enquête) :
-
À partir de ANC1 :
danc1_pregnancy: Grossesses estiméesdanc1_delivery: Estimation des accouchementsdanc1_birth: Estimation des naissances (vivants + mort-nés)danc1_livebirth: Estimation des naissances vivantesdanc1_dpt: Éligible pour le DTC (ajusté pour la mortalité néonatale)danc1_measles1: Éligible pour le MCV1danc1_measles2: Éligible pour le MCV2
-
À partir de delivery :
ddelivery_livebirth,ddelivery_birth,ddelivery_pregnancyddelivery_dpt,ddelivery_measles1,ddelivery_measles2
-
À partir de SBA (accouchement assisté par un personnel qualifié) :
- Même structure que les dénominateurs d’accouchement
dsba_livebirth,dsba_birth,dsba_pregnancydsba_dpt,dsba_measles1,dsba_measles2
-
À partir de BCG (uniquement au niveau national) :
dbcg_pregnancy,dbcg_livebirth,dbcg_dpt
-
À partir de Penta1 :
dpenta1_dpt,dpenta1_measles1,dpenta1_measles2
B. Dénominateurs basés sur la population (nationaux uniquement) :
dwpp_pregnancy: Taux brut de natalité × population totale ÷ (1 + taux de gémellité)dwpp_livebirth: Du taux brut de natalité × population totaledwpp_dpt: Population de moins de 1 andwpp_measles1: Population de moins de 1 an ajustée pour la mortalité néonataledwpp_measles2: Ajusté pour la mortalité post-néonatale
C. Vitamine A et vaccination complète :
Pour chaque dénominateur de naissance vivante, des dénominateurs supplémentaires sont automatiquement créés :
d*_vitaminA: Naissances vivantes × (1 - U5MR) × 4,5 (enfants de 6 à 59 mois)d*_fully_immunized: Naissances vivantes × (1 - TMI)
Ajustement pour les déclarations incomplètes :
Lorsque nummonth < 12, les dénominateurs basés sur la population sont mis à l’échelle :
denominator_adjusted = denominator × (nummonth / 12)Sortie :
Base de données avec tous les dénominateurs calculés et les données originales du SIGS et de l’enquête
`classify_source_type()`
Objectif : Catégorise les dénominateurs pour éviter les références circulaires
Logique :
reference_based: Dénominateur calculé à partir du même indicateur (par exemple,danc1_pregnancypouranc1)unwpp_based: Dénominateur calculé à partir des données démographiques du WPP de l’ONUindependent: Dénominateur provenant d’un indicateur de service différent
Importance :
Cette classification garantit que lors de la sélection des “meilleurs” dénominateurs, nous évitons d’utiliser des dénominateurs basés sur des références (qui montreraient artificiellement une couverture à 100% égale à la valeur de l’enquête).
`select_best_chain()` et `compare_coverage_to_survey()`
Objectif : select_best_chain() pré-sélectionne une chaîne de dénominateurs unique au niveau national. compare_coverage_to_survey() filtre ensuite toutes les estimations de couverture sur cette chaîne et joint les valeurs d’enquête pour une comparaison diagnostique.
Entrée (select_best_chain) :
- Tableau national des dénominateurs (avec colonnes
dwpp_*,danc1_*,ddelivery_*,dpenta1_*) - Paramètre
DENOMINATOR_CHAIN(par défautauto)
Algorithme de sélection (mode auto) :
- Pour chaque chaîne candidate (
anc1,delivery,penta1—bcgest exclu de l’auto car il est national uniquement), et pour chaque population cible disponible dans UN WPP (pregnancy,livebirth,dpt), calculer le rapport de la valeur de la chaîne à la valeur UN WPP lorsque les deux sont positives - Prendre le rapport médian sur toutes les années et populations cibles pour chaque chaîne
- Sélectionner la chaîne dont le rapport médian est le plus proche de 1,0
- Si
DENOMINATOR_CHAINest défini sur une chaîne spécifique (par ex.anc1), ignorer la comparaison et utiliser cette chaîne directement
Sortie (select_best_chain) : le nom de la chaîne sélectionnée (par ex. delivery) et son préfixe (par ex. ddelivery_)
compare_coverage_to_survey() ensuite :
- Filtre les lignes de couverture sur celles dont le dénominateur commence par le préfixe de la chaîne
- Joint les valeurs de référence d’enquête reportées
- Calcule
squared_error = (coverage - survey)²comme colonne diagnostique (non utilisée pour la sélection) - Retourne la couverture filtrée et un tableau de correspondance des dénominateurs listant le dénominateur de la chaîne pour chaque indicateur
Décisions clés de conception :
- La sélection se fait par chaîne (une chaîne pour tous les indicateurs et toutes les géographies), pas par indicateur
- UN WPP sert d’ancrage pour la sélection de la chaîne ; les valeurs d’enquête ne sont pas utilisées pour choisir la chaîne
- La même chaîne est appliquée aux niveaux infranationaux pour la cohérence géographique
- Si la chaîne est nationale uniquement (BCG), les résultats infranationaux sont supprimés
`create_combined_results_table()`
Objectif : Fusionne les estimations de couverture et les observations d’enquête en une sortie unifiée
Entrée :
- Résultats de la comparaison de la couverture (choix du meilleur dénominateur)
- Observations brutes de l’enquête
- Toutes les données de couverture (facultatif, comprend tous les dénominateurs)
Structure de sortie :
admin_area_1 year indicator_common_id denominator_best_or_survey valueCountry_Name 2020 anc1 best 85.3Country_Name 2020 anc1 survey 84.2Country_Name 2020 anc1 danc1_pregnancy 85.3Country_Name 2020 anc1 dwpp_pregnancy 82.1Catégories de dénominateurs :
best: Dénominateur optimal sélectionnésurvey: Observation réelle de l’enquêted*_*: Résultats du dénominateur individuel (toutes les options)
Méthodes statistiques et algorithmes
Section intitulée « Méthodes statistiques et algorithmes »Remplissage (dernière observation reportée)
Les données d’enquête présentent généralement des lacunes (par exemple, l’enquête démographique et sanitaire tous les 5 ans). Pour créer des dénominateurs continus :
na.locf(survey_value, na.rm = FALSE)Exemple :
Year: 2015 2016 2017 2018 2019 2020Raw: 85.3 NA NA NA 87.2 NAFilled: 85.3 85.3 85.3 85.3 87.2 87.2Cela suppose que la couverture reste constante jusqu’à la prochaine observation.
Sélection de chaîne par proximité au UN WPP (mode auto)
Pour choisir la chaîne de dénominateurs à appliquer à tous les indicateurs :
$$ \text{Chaîne sélectionnée} = \arg \min_{c} \left| \operatorname{median}{t,p} \left( \frac{D{c,p,t}}{D_{\text{wpp},p,t}} \right) - 1 \right| $$
Où :
- $D_{c,p,t}$ = dénominateur de la chaîne $c$ pour la population cible $p$ dans l’année $t$ (valeurs positives uniquement)
- $D_{\text{wpp},p,t}$ = dénominateur UN WPP correspondant
- $c \in {\text{anc1}, \text{delivery}, \text{penta1}}$ (BCG exclu car national uniquement)
- $p$ itère sur les populations cibles disponibles dans UN WPP (
pregnancy,livebirth,dpt)
La chaîne dont le rapport médian est le plus proche de 1,0 à travers les années et les populations cibles est sélectionnée. L’erreur quadratique par rapport aux valeurs d’enquête est toujours calculée et exposée dans les sorties de la partie 1, mais uniquement à titre diagnostique — elle ne détermine pas la sélection.
Cadre conceptuel : Cascades démographiques
Section intitulée « Cadre conceptuel : Cascades démographiques »Avant de présenter les formules spécifiques, il est important de comprendre le flux conceptuel des calculs des dénominateurs. Les dénominateurs sont dérivés d’ajustements démographiques séquentiels qui reflètent la cascade biologique de la grossesse aux populations cibles des services de santé spécifiques.
Exemple illustratif : De la grossesse à la population éligible au DTC
Considérons comment une estimation de 10 000 grossesses se traduit en population éligible à la vaccination DTC :
Starting point (pregnancies): 10,000→ After pregnancy loss (3%): 10,000 × (1 - 0.03) = 9,700 deliveries→ After twin adjustment (1.5% rate): 9,700 × (1 - 0.015/2) = 9,627 births→ After stillbirths (2%): 9,627 × (1 - 0.02) = 9,435 live births→ After neonatal deaths (3.9%): 9,435 × (1 - 0.039) = 9,067 DTC-eligible childrenCette cascade montre comment chaque facteur démographique réduit séquentiellement la taille de la population au fur et à mesure que l’on passe d’un stade de vie à l’autre. Les formules mathématiques détaillées dans les sections suivantes suivent la même logique, mais fonctionnent dans les deux sens :
- Cascade ascendante : En partant des indicateurs antérieurs (CPN1, accouchement) et en les ajustant en fonction des populations cibles ultérieures
- Cascade rétrospective : En partant d’indicateurs plus récents (BCG, Penta1) et en revenant en arrière pour estimer les populations plus anciennes
Les taux spécifiques et les formules pour chaque source de dénominateur sont détaillés ci-dessous.
Calculs du dénominateur basés sur le SIGS
Section intitulée « Calculs du dénominateur basés sur le SIGS »Dénominateurs dérivés de ANC1
À partir du nombre de services ANC1 et de la couverture de l’enquête, nous calculons :
Grossesses estimées (calcul de base) :
$$ d_{\text{anc1-pregnancy}} = \frac{\text{count}{\text{anc1}} \times 100}{\text{coverage}{\text{anc1}}} $$
Accouchements estimés (ajustés pour les pertes de grossesse) :
$$ d_{\text{anc1-delivery}} = d_{\text{anc1-pregnancy}} \times (1 - \text{taux de perte de grossesse}) $$
Naissances estimées (ajustées pour les naissances gémellaires) :
$$ d_{\text{anc1-birth}} = d_{\text{anc1-delivery}} / (1 - 0.5 \times \text{taux de gémellité}) $$
Naissances vivantes estimées (ajustées pour les mort-nés) :
$$ d_{\text{anc1-livebirth}} = d_{\text{anc1-birth}} \times (1 - \text{taux de mortinatalité}) $$
Population éligible pour les vaccins DTC/Penta (ajusté pour la mortalité néonatale) :
$$ d_{\text{anc1-dpt}} = d_{\text{anc1-livebirth}} \times (1 - \text{taux de mortalité néonatale}) $$
Population éligible pour le MCV1 (ajusté pour la mortalité post-néonatale) :
$$ d_{\text{anc1-measles1}} = d_{\text{anc1-dpt}} \times (1 - \text{taux de mortalité post-néonatale}) $$
Population éligible pour le MCV2 (ajusté pour la mortalité post-néonatale supplémentaire) :
$$ d_{\text{anc1-measles2}} = d_{\text{anc1-dpt}} \times (1 - 2 \times \text{taux de mortalité post-néonatale}) $$
Dénominateurs dérivés de delivery
À partir du nombre d’accouchements institutionnels et de la couverture de l’enquête :
Naissances vivantes estimées (calcul de base) :
$$ d_{\text{delivery-livebirth}} = \frac{\text{count}{\text{delivery}} \times 100}{\text{coverage}{\text{delivery}}} $$
Naissances estimées (ajustées pour la mortinatalité) :
$$ d_{\text{delivery-birth}} = d_{\text{delivery-livebirth}} / (1 - \text{taux de mortinatalité}) $$
Grossesses estimées (ajustées pour les naissances gémellaires et les pertes de grossesse) :
$$ d_{\text{delivery-pregnancy}} = d_{\text{delivery-birth}} \times (1 - 0.5 \times \text{taux de gémellité}) / (1 - \text{taux de perte de grossesse}) $$
Population éligible pour les vaccins DTC/Penta :
$$ d_{\text{delivery-dpt}} = d_{\text{delivery-livebirth}} \times (1 - \text{taux de mortalité néonatale}) $$
Population éligible pour le MCV1 :
$$ d_{\text{delivery-measles1}} = d_{\text{delivery-dpt}} \times (1 - \text{taux de mortalité post-néonatale}) $$
Population éligible pour le MCV2 :
$$ d_{\text{delivery-measles2}} = d_{\text{delivery-dpt}} \times (1 - 2 \times \text{taux de mortalité post-néonatale}) $$
Note : Les dénominateurs dérivés du accouchement assisté par un personnel qualifié (SBA) suivent les mêmes formules que les dénominateurs d’accouchement.
Dénominateurs dérivés de BCG (analyse nationale uniquement)
À partir des chiffres de la vaccination BCG et de la couverture de l’enquête :
Naissances vivantes estimées (calcul de base) :
$$ d_{\text{bcg-livebirth}} = \frac{\text{count}{\text{bcg}} \times 100}{\text{coverage}{\text{bcg}}} $$
Grossesses estimées (en remontant les ajustements démographiques) :
$$ d_{\text{bcg-pregnancy}} = \frac{d_{\text{bcg-livebirth}}}{(1 - \text{taux de perte de grossesse}) \times (1 + \text{taux de gémellité}) \times (1 - \text{taux de mortinatalité})} $$
Population éligible pour les vaccins DTC/Penta :
$$ d_{\text{bcg-dpt}} = d_{\text{bcg-livebirth}} \times (1 - \text{taux de mortalité néonatale}) $$
Dénominateurs dérivés de Penta1
À partir des chiffres de vaccination de Penta1 et de la couverture de l’enquête :
Population éligible pour les vaccins DTC/Penta (calcul de base) :
$$ d_{\text{penta1-dpt}} = \frac{\text{count}{\text{penta1}} \times 100}{\text{coverage}{\text{penta1}}} $$
Population éligible pour le MCV1 :
$$ d_{\text{penta1-measles1}} = d_{\text{penta1-dpt}} \times (1 - \text{taux de mortalité post-néonatale}) $$
Population éligible pour le MCV2 :
$$ d_{\text{penta1-measles2}} = d_{\text{penta1-dpt}} \times (1 - 2 \times \text{taux de mortalité post-néonatale}) $$
Dénominateurs dérivés du nombre de naissances vivantes
Lorsque les données sur les naissances vivantes sont directement déclarées dans le SIGS :
Naissances vivantes estimées (calcul de base) :
$$ d_{\text{livebirths-livebirth}} = \frac{\text{count}{\text{livebirth}} \times 100}{\text{coverage}{\text{livebirth}}} $$
Grossesses estimées (à rebours) :
$$ d_{\text{livebirths-pregnancy}} = \frac{d_{\text{livebirths-livebirth}} \times (1 - 0.5 \times \text{taux de gémellité})}{(1 - \text{taux de mortinatalité}) \times (1 - \text{taux de perte de grossesse})} $$
Accouchements estimés :
$$ d_{\text{livebirths-delivery}} = d_{\text{livebirths-pregnancy}} \times (1 - \text{taux de perte de grossesse}) $$
Naissances estimées :
$$ d_{\text{livebirths-birth}} = d_{\text{livebirths-livebirth}} / (1 - \text{taux de mortinatalité}) $$
Population éligible pour les vaccins DTC/Penta :
$$ d_{\text{livebirths-dpt}} = d_{\text{livebirths-livebirth}} \times (1 - \text{taux de mortalité néonatale}) $$
Population éligible pour le MCV1 :
$$ d_{\text{livebirths-measles1}} = d_{\text{livebirths-dpt}} \times (1 - \text{taux de mortalité post-néonatale}) $$
Population éligible pour le MCV2 :
$$ d_{\text{livebirths-measles2}} = d_{\text{livebirths-dpt}} \times (1 - 2 \times \text{taux de mortalité post-néonatale}) $$
Calculs du dénominateur basés sur l’UNWPP
Section intitulée « Calculs du dénominateur basés sur l’UNWPP »Dénominateurs dérivés de l’UN WPP (analyse nationale uniquement)
Au lieu d’utiliser les volumes de services, ces dénominateurs sont calculés directement à partir des projections de population et des taux démographiques :
Grossesses estimées (à partir du taux brut de natalité et de la population totale) :
$$ d_{\text{wpp-pregnancy}} = \frac{\text{Taux brut de natalité}}{1000} \times \text{Population totale} \times \frac{1}{1 + \text{taux de gémellité}} $$
Naissances vivantes estimées (à partir du taux brut de natalité) :
$$ d_{\text{wpp-livebirth}} = \frac{\text{Taux brut de natalité}}{1000} \times \text{Population totale} $$
Population éligible pour les vaccins DTC/Penta (population de moins de 1 an) :
$$ d_{\text{wpp-dpt}} = \text{Population totale des moins de 1 an du WPP} $$
Population éligible pour le MCV1 (ajusté pour la mortalité néonatale) :
$$ d_{\text{wpp-measles1}} = d_{\text{wpp-dpt}} \times (1 - \text{taux de mortalité néonatale}) $$
Population éligible pour le MCV2 (ajusté pour la mortalité post-néonatale) :
$$ d_{\text{wpp-measles2}} = d_{\text{wpp-dpt}} \times (1 - \text{taux de mortalité néonatale}) \times (1 - 2 \times \text{taux de mortalité post-néonatale}) $$
Ajustement pour les rapports incomplets:
Lorsque les données SIGS contiennent moins de 12 mois de données rapportées dans une année, tous les dénominateurs de l’UNWPP sont mis à l’échelle pour correspondre à la période de rapport :
$$ d_{\text{adjusted}} = d_{\text{wpp}} \times \frac{\text{months reported}}{12} $$
Cet ajustement garantit que les dénominateurs sont comparables aux volumes de services qui peuvent ne représenter qu’une partie de l’année.
Dénominateurs dérivés des estimations de naissances vivantes (calculs secondaires)
Une fois que tous les dénominateurs primaires des naissances vivantes ont été calculés (à partir des CPN1, des accouchements, du BCG, du Penta1, du nombre de naissances vivantes et du WPP), le module génère des estimations supplémentaires de la population cible pour des interventions spécifiques en appliquant des ajustements de la mortalité en fonction de l’âge :
Enfants âgés de 6 à 59 mois (population cible pour la supplémentation en vitamine A)
Pour chaque source de dénominateur de naissances vivantes, le nombre estimé d’enfants âgés de 6 à 59 mois est calculé :
$$ d_{\text{source-vitaminA}} = d_{\text{source-livebirth}} \times (1 - \text{taux de mortalité des enfants de moins de 5 ans}) \times 4.5 $$
Où :
sourcereprésente l’un des éléments suivants :anc1,delivery,bcg,penta1,livebirthsouwpp- Le facteur 4,5 représente la durée approximative (en années) de la tranche d’âge cible pour la vitamine A (6-59 mois ≈ 4,5 ans)
- Le taux de mortalité des moins de 5 ans tient compte de la survie de l’enfant pour atteindre la tranche d’âge de 6 à 59 mois
- Résultat : Population estimée d’enfants âgés de 6 à 59 mois éligibles à une supplémentation en vitamine A
Nourrissons de moins de 12 mois (population cible d’enfants complètement vaccinés)
Pour chaque source de dénominateur de naissances vivantes, le nombre estimé de nourrissons de moins de 12 mois est calculé :
$$ d_{\text{source-fully-immunized}} = d_{\text{source-livebirth}} \times (1 - \text{taux de mortalité infantile}) $$
Où :
sourcereprésente l’un des éléments suivants :anc1,delivery,bcg,penta1,livebirthsouwpp- Le taux de mortalité infantile est ajusté pour tenir compte de la survie jusqu’à l’âge de 12 mois
- Résultat : Population estimée de nourrissons de moins d’un an pouvant bénéficier d’une évaluation complète de la vaccination
Ces estimations de la population cible sont calculées automatiquement pour tous les dénominateurs de naissances vivantes disponibles, ce qui garantit une méthodologie cohérente entre les différents indicateurs sources.
Étapes d’exécution du flux de travail
Section intitulée « Étapes d’exécution du flux de travail »La partie 1 exécute le flux de travail suivant pour chaque niveau administratif (national, admin2, admin3) :
Étape 1 : Chargement et validation des données d’entrée
- Charger les données ajustées du module 2 du SIGS (fichiers nationaux et infranationaux)
- Charger les données d’enquête à partir du dépôt GitHub (ensemble de données EDS/MICS unifiées)
- Charger les données de population du WPP de l’ONU à partir du dépôt GitHub
- Valider la correspondance des codes ISO3 entre les ensembles de données
- Agréger les données mensuelles du SIGS en totaux annuels
- Harmoniser les données d’enquête (priorité à l’EDS par rapport à l’enquête MICS)
- Remplir les valeurs de l’enquête pour créer des séries temporelles continues
Étape 2 : Calculer les dénominateurs basés sur le SIGS
- Pour chaque indicateur de santé avec des données de couverture d’enquête :
- Calculer le dénominateur de base :
count ÷ survey_coverage - Appliquer les cascades démographiques pour dériver les dénominateurs correspondants
- Générer des dénominateurs à partir de tous les indicateurs sources disponibles (
anc1,delivery,bcg,penta1,livebirths)
- Calculer le dénominateur de base :
Étape 3 : Calculer les dénominateurs basés sur le WPP
- Extraire les projections démographiques pour le pays cible
- Calculer les estimations de grossesses à partir du taux brut de natalité
- Calculer les estimations de naissances vivantes
- Générer des dénominateurs pour la population de moins de 1 an
- Appliquer les ajustements de mortalité pour les populations éligibles à la vaccination
- Ajuster pour les périodes de déclaration incomplètes (mois déclarés < 12)
Étape 4 : Calcul des dénominateurs secondaires
- Pour chaque dénominateur
*_livebirth:- Calculer le dénominateur de la vitamine A :
livebirth × (1 - U5MR) × 4.5 - Calculer le dénominateur de la vaccination complète :
livebirth × (1 - IMR)
- Calculer le dénominateur de la vitamine A :
Étape 5 : Calculer les estimations de couverture
- Diviser le volume de services SIGS par chaque option de dénominateur
- Créer des estimations de couverture pour toutes les combinaisons indicateur-dénominateur
- Conserver la couverture basée sur l’enquête comme référence
Étape 6 : Pré-sélectionner la chaîne de dénominateurs (au niveau de la chaîne, pas par indicateur)
- Au niveau national, pour chaque chaîne SIGS candidate (
anc1,delivery,penta1), calculer le rapport médian des valeurs de la chaîne aux valeurs UN WPP pour les populations ciblespregnancy,livebirthetdpt - Sélectionner la chaîne dont le rapport médian est le plus proche de 1,0 ; elle devient la chaîne
best - Appliquer la même chaîne à la zone administrative 2 et à la zone administrative 3 (supprimer les lignes infranationales si la chaîne est BCG, qui est nationale uniquement)
- Enregistrer la correspondance dénominateur-par-indicateur de la chaîne dans
M5_selected_denominator_per_indicator.csv - Calculer l’erreur quadratique par rapport aux valeurs d’enquête comme colonne diagnostique (non utilisée pour la sélection)
Étape 7 : Formatage et enregistrement des résultats
- Sauvegarder les fichiers de dénominateurs avec les métadonnées de la source et de la cible
- Enregistrer les résultats combinés avec toutes les estimations de couverture
- Marquer le meilleur dénominateur pour faciliter le filtrage
- Inclure les valeurs de l’enquête dans les résultats
- Créer des fichiers séparés pour les niveaux national, admin2 et admin3
- Générer des fichiers vides avec la structure correcte pour les niveaux d’administration non disponibles
Spécification des fichiers de sortie
La partie 1 (module m005) génère sept fichiers CSV :
Fichiers dénominateurs
1. M5_denominators_national.csv
2. M5_denominators_admin2.csv
3. M5_denominators_admin3.csv
Structure :
admin_area_1, [admin_area_2/3], year, denominator, source_indicator, target_population, valueChamps :
denominator: Nom complet du dénominateur (par exemple,danc1_livebirth)source_indicator: Service utilisé (par exemple,source_anc1,source_wpp)target_population: Groupe cible (par exemple,target_livebirth,target_dpt)value: Taille du dénominateur calculée
Fichiers de résultats combinés
4. M5_combined_results_national.csv — colonnes : admin_area_1, year, indicator_common_id, denominator_best_or_survey, value
5. M5_combined_results_admin2.csv — colonnes : admin_area_1, admin_area_2, year, indicator_common_id, denominator_best_or_survey, value
6. M5_combined_results_admin3.csv — colonnes : admin_area_1, admin_area_3, year, indicator_common_id, denominator_best_or_survey, value
Champs :
indicator_common_id: Indicateur de santé (par exemple,anc1,penta3)denominator_best_or_survey: Soitbest(la chaîne pré-sélectionnée parm005),survey(observation brute EDS/MICS), soit un nom de dénominateur spécifique (par ex.danc1_pregnancy,dwpp_livebirth)value: Pourcentage de couverture (0–100+) pour les lignes de dénominateur, ou couverture brute d’enquête pour les lignessurvey
Entrée spéciale best : Duplique le dénominateur de la chaîne pour chaque indicateur afin que m006 puisse filtrer sur denominator_best_or_survey == "best" sans avoir à connaître la chaîne sélectionnée.
7. M5_selected_denominator_per_indicator.csv
Objectif : Tableau récapitulatif listant le dénominateur de la chaîne pré-sélectionnée attribué à chaque indicateur à chaque niveau géographique. Comme m005 sélectionne une seule chaîne et l’applique à toutes les géographies, les trois colonnes contiennent généralement la même chaîne (seule la variante de population cible diffère selon l’indicateur).
Structure :
indicator_common_id, denominator_national, denominator_admin2, denominator_admin3Champs :
indicator_common_id: Indicateur de santé (par exemple,anc1,penta3)denominator_national: Dénominateur de la chaîne utilisé au niveau national (par ex.danc1_pregnancypouranc1si la chaîne ANC1 a été sélectionnée)denominator_admin2: Même dénominateur au niveau admin 2, ouNOT_AVAILABLElorsque la chaîne est nationale uniquement (BCG)denominator_admin3: Même dénominateur au niveau admin 3, ouNOT_AVAILABLElorsque la chaîne est nationale uniquement (BCG)
Sauvegarde et validation des données
La partie 1 comprend de multiples contrôles de validation :
-
Validation ISO3 : Vérifie que les données de l’enquête et de la population correspondent à celles du pays SIGS
-
Correspondance géographique : Validation des noms des régions administratives entre le SIGS et l’enquête
- Rapporte le taux de concordance (par exemple, “15/20 régions concordent”)
- Retourne au niveau géographique supérieur en cas de non-concordance
-
Mécanismes de repli :
- Si aucune donnée d’enquête infranationale n’existe pour le pays, l’exécution entière bascule en
NATIONAL_ONLY - Aux niveaux infranationaux, les lacunes par indicateur dans l’enquête restent à
NA(aucune substitution national → infranational) - SBA → Delivery si SBA manquant (appliqué à chaque niveau)
- PNC1_mother → PNC1 si manquant (appliqué à chaque niveau)
- Si aucune donnée d’enquête infranationale n’existe pour le pays, l’exécution entière bascule en
-
Traitement des cas de bordure : Détecte quand admin_area_3 doit être utilisé comme admin_area_2 dans certains contextes nationaux
-
Gestion des données vides : Crée des CSV vides avec une structure correcte lorsque les données ne sont pas disponibles
-
Gestion des erreurs : Enveloppe le traitement de l’enquête dans
tryCatchpour gérer les erreurs de manière élégante
Indicateurs pris en charge
La partie 1 traite les indicateurs de santé suivants :
Santé maternelle :
anc1: Soins prénatals 1ère visiteanc4: Soins prénatals 4+ visitesdelivery: Accouchement en institutionsba: Assistance qualifiée à l’accouchementpnc1: Soins postnatals (enfant)pnc1_mother: Soins postnatals (mère)
Immunisation :
bcg: Vaccin BCGpenta1,penta2,penta3: Vaccin Pentavalentmeasles1,measles2: Vaccin contenant la rougeolerota1,rota2: Vaccin contre le rotavirusopv1,opv2,opv3: Vaccin oral contre la poliofully_immunized: Statut vaccinal complet
Santé de l’enfant :
nmr: Taux de mortalité néonatale (enquête uniquement)imr: Taux de mortalité infantile (enquête uniquement)vitaminA: Supplémentation en vitamine A
Notes d'utilisation et bonnes pratiques
Quand utiliser quelle variable de comptage
count_final_none: Pas d’ajustement (données brutes)count_final_outliers: Ajustement des valeurs aberrantes uniquement (par défaut)count_final_completeness: Ajustement de l’exhaustivité uniquementcount_final_both: Les deux ajustements combinés
Interprétation des “meilleurs” dénominateurs
Le “meilleur” dénominateur peut varier selon l’indicateur et le domaine en fonction de :
- La disponibilité des données (certains services ne sont pas universellement rapportés)
- L’exhaustivité des rapports (affecte les dénominateurs basés sur SIGS)
- La qualité des projections démographiques (affecte les dénominateurs du WPP)
- Niveaux de couverture de l’enquête (les valeurs extrêmes réduisent les options de dénominateur)
**Pourquoi plusieurs dénominateurs ?
Des dénominateurs différents servent des objectifs différents :
- Dénominateurs indépendants : Fournir une validation croisée entre les services
- Dénominateurs de référence : Montrer la cohérence interne du SIGS (mais exclus par défaut des “meilleurs” dénominateurs)
- Dénominateurs de référence : montrent la cohérence interne du système SIGS (mais sont exclus de la “meilleure” valeur par défaut) : Offrent des points de référence basés sur la population
- La comparaison de plusieurs options révèle des problèmes de qualité des données
Résolution des problèmes courants
Problèmes : Pas de correspondance entre les domaines administratifs du SIGS et de l’enquête
- Solution : Vérifiez que le code ISO3 est correct ; vérifiez les conventions de dénomination des zones administratives ; le module reviendra à l’analyse nationale
Problème : Tous les dénominateurs montrent une couverture >100%
- Solution : Peut indiquer une sous-déclaration dans l’enquête ou une sur-déclaration dans le SIGS ; vérifier la qualité des données dans le module 2
Problème : L’UNWPP a été sélectionné comme “meilleur” pour la plupart des indicateurs
- Solution : Peut indiquer une mauvaise qualité ou complétude des données SIGS ; revoir les ajustements du module 2
Partie 2 : Sélection du dénominateur et projection de l’enquête (détails techniques)
Section intitulée « Partie 2 : Sélection du dénominateur et projection de l’enquête (détails techniques) »But et objectifs
Section intitulée « But et objectifs »La partie 2 a trois objectifs principaux :
-
Sélection du dénominateur par l’utilisateur : Alors que la partie 1 pré-sélectionne automatiquement une chaîne de dénominateurs unique en fonction de la proximité des estimations SIGS-implicites aux estimations de population UN WPP au niveau national, la partie 2 permet aux utilisateurs d’outrepasser cette sélection et de forcer une autre chaîne (
anc1,delivery,bcgoupenta1) sur la base de leurs connaissances programmatiques ou de leurs priorités politiques -
Analyse des tendances temporelles : Analyse des tendances temporelles** : calcule les changements d’une année sur l’autre (deltas) dans la couverture pour comprendre les tendances de la prestation de services au fil du temps
-
Projection de l’enquête : Projette les estimations de couverture basées sur l’enquête dans le temps en utilisant les tendances observées dans les données administratives (SIGS), en comblant les lacunes lorsque les données de l’enquête ne sont pas disponibles
Configuration de l’utilisateur
Section intitulée « Configuration de l’utilisateur »La partie 2 (module m006) expose un seul paramètre de configuration, DENOMINATOR_CHAIN, qui contrôle le dénominateur utilisé pour tous les calculs de couverture :
DENOMINATOR_CHAIN <- "auto" # Options : "auto", "anc1", "delivery", "bcg", "penta1"Options :
"auto"(par défaut) — Utilise la chaînebestpré-sélectionnée par la partie 1 (m005) — une chaîne unique choisie par proximité au UN WPP au niveau national et réutilisée pour chaque indicateur et chaque niveau géographique."anc1"— Force toutes les estimations de couverture à utiliser la chaîne de dénominateurs dérivée de la CPN1 (danc1_pregnancy,danc1_livebirth,danc1_dpt, etc.)."delivery"— Force la chaîne dérivée des accouchements (ddelivery_*)."bcg"— Force la chaîne dérivée du BCG (dbcg_*, niveau national uniquement)."penta1"— Force la chaîne dérivée du Penta1 (dpenta1_*).
Lorsqu’une chaîne fixe est sélectionnée, le module applique la même source à tous les indicateurs et à tous les niveaux géographiques pour assurer la cohérence. La couverture est ensuite calculée pour chaque indicateur en utilisant la variante de population cible appropriée de cette chaîne (par exemple, danc1_pregnancy pour CPN1/CPN4, danc1_livebirth pour accouchement/BCG/SBA, danc1_dpt pour Penta1-3, danc1_measles1 pour MCV1, etc.).
La portée géographique est héritée du paramètre ANALYSIS_LEVEL de la partie 1 — m006 s’exécute pour les sorties nationales, admin 2 et admin 3 de m005 lorsqu’elles sont disponibles.
Fonctions et méthodes principales
Section intitulée « Fonctions et méthodes principales »Fonction 1 : `coverage_deltas()`
Objectif : Calculer les changements de couverture d’une année sur l’autre pour chaque combinaison indicateur-dénominateur-géographie.
Algorithme :
coverage_deltas <- function(coverage_df, lag_n = 1, complete_years = TRUE)Processus :
- Regroupement des données par géographie (zones administratives), par indicateur et par dénominateur
- Complète éventuellement les années manquantes pour créer une série chronologique complète
- Trie les données par ordre chronologique au sein de chaque groupe
- Calcule le delta comme suit $\Delta\text{coverage}_t = \text{coverage}t - \text{coverage}{t-1}$
Formulation mathématique : $$ \Delta C_{i,d,g,t} = C_{i,d,g,t} - C_{i,d,g,t-1} $$
où :
- $C$ = estimation de la couverture
- $i$ = indicateur
- $d$ = dénominateur
- $g$ = zone géographique
- $t$ = temps (année)
Entrée :
coverage_df: Cadre de données avec les estimations de couverturelag_n: Nombre d’années de décalage (par défaut = 1 pour une comparaison d’une année sur l’autre)complete_years: Remplir ou non les années manquantes (par défaut = TRUE)
Sortie :
Cadre de données avec les valeurs de couverture originales et une colonne delta montrant les changements d’une année sur l’autre.
Exemple de sortie :
| admin_area_1 | indicator_common_id | denominator | year | coverage | delta |
|---|---|---|---|---|---|
| Country A | penta3 | dpenta1_dpt | 2018 | 75.2 | NA |
| Country A | penta3 | dpenta1_dpt | 2019 | 78.5 | 3.3 |
| Country A | penta3 | dpenta1_dpt | 2020 | 80.1 | 1.6 |
Fonction 2 : `project_survey_from_deltas()`
Objectif : Projette les estimations de couverture basées sur les enquêtes en utilisant les tendances des données administratives.
Algorithme :
project_survey_from_deltas <- function(deltas_df, survey_raw_long)Processus :
-
Identifier la ligne de base : Pour chaque combinaison géographie-indicateur, trouver l’observation la plus récente de l’enquête
- Extraire la dernière année d’enquête observée
- Enregistrer la valeur de la couverture de référence pour cette année-là
-
Attacher la base de référence à chaque chemin de dénominateur : Étant donné que la partie 2 opère sur des sélections de dénominateurs spécifiques, attachez la ligne de base à chaque série de dénominateurs
-
Calculer les deltas cumulés : Pour les années postérieures à l’année de référence, calculez la somme cumulative des deltas :
$$\text{cumulative delta}t = \sum{\tau = \text{année de référence} + 1}^{t} \Delta C_\tau$$
-
Calculer la projection : Ajouter le delta cumulé à la valeur de référence :
$$\text{Couverture projetée}_t = \text{Couverture de base} + \text{délta cumulatif}_t$$
Formulation mathématique :
Pour chaque indicateur $i$, dénominateur $d$ et géographie $g$ :
- Trouver la ligne de base :
$$ y_{\text{valeur de référence}} = \max{t : S_{i,g,t} \text{ existe}} $$
$$ S_{\text{valeur de référence}} = S_{i,g,y_{\text{valeur de référence}}} $$
- Pour $t > y_{\text{valeur de référence}}$ :
$$ \hat{S}{i,d,g,t} = S{text{valeur de référence}} + \sum_{\tau = y_{\text{valeur de référence}} + 1}^{t} \Delta C_{i,d,g,\tau} $$
où :
- $S$ = estimation de la couverture basée sur l’enquête
- $S$ = estimation de la couverture basée sur l’enquête $S$ = estimation de la couverture basée sur l’enquête $S$ = estimation de la couverture basée sur l’enquête
- $Delta C$ = variation de la couverture administrative d’une année sur l’autre
Hypothèses :
- Les tendances observées dans les données administratives reflètent les changements réels dans la couverture des services
- L’enquête de référence fournit un point de référence précis
- Les tendances observées dans les données administratives peuvent être appliquées aux estimations de l’enquête
Entrée :
deltas_df: Sortie decoverage_deltas()contenant les changements de couverturesurvey_raw_long: Données brutes de l’enquête avec les années et les valeurs
Sortie :
Cadre de données avec la couverture projetée pour chaque année, indicateur, dénominateur et combinaison géographique.
Exemple de sortie :
| admin_area_1 | indicator_common_id | denominator | year | baseline_year | projected |
|---|---|---|---|---|---|
| Country A | penta3 | dpenta1_dpt | 2018 | 2018 | 75.0 |
| Country A | penta3 | dpenta1_dpt | 2019 | 2018 | 78.3 |
| Country A | penta3 | dpenta1_dpt | 2020 | 2018 | 79.9 |
Fonction 3 : `build_final_results()`
Objectif : Combine la couverture SIGS, les estimations de l’enquête projetée et les valeurs de l’enquête originale dans un ensemble de données de sortie unifié.
Algorithme :
build_final_results <- function(coverage_df, proj_df, survey_raw_df = NULL)Processus :
-
Préparation de la couverture SIGS : Extraire les estimations de couverture des données administratives
- Renommer la colonne couverture en
coverage_covpour plus de clarté
- Renommer la colonne couverture en
-
Fusionner les projections : Joindre les estimations projetées de l’enquête
- Correspondance par géographie, année, indicateur et dénominateur
- Créer une colonne
coverage_avgsurveyprojection
-
Traiter les données d’enquête originales (si elles sont disponibles) :
- Regrouper plusieurs sources d’enquête en prenant la valeur moyenne
- Préserver les métadonnées de la source (source, source_detail)
- Élargir les valeurs de l’enquête à tous les dénominateurs pour cet indicateur
-
Calculer les projections finales : Utiliser une formule de projection améliorée qui s’ancre dans la dernière valeur d’enquête :
Pour les années postérieures à la dernière année d’enquête :
$$ \text{Couverture projetée}t = \text{Dernière valeur d’enquête} + (C{\text{SIGS},t} - C_{\text{SIGS, dernière année d’enquête}}) $$
Cette approche additive
- Préserve l’étalonnage des données d’enquête
- Applique la tendance de l’enquête SIGS (delta) pour étendre l’estimation vers l’avant
- Évite les erreurs cumulées dues aux deltas d’une année sur l’autre
-
Combiner les résultats : Fusionner tous les composants à l’aide d’une jointure externe complète pour préserver :
- Les années avec seulement des données SIGS
- Années avec uniquement des données d’enquête
- Années avec les deux sources de données
Formulation mathématique :
Let :
- $t_s$ = année de la dernière enquête
- $S_{t_s}$ = couverture de l’enquête à l’année $t_s$
- $C_{\text{SIGS},t}$ = couverture basée sur SIGS à l’année $t$
Pour $t > t_s$ :
$$ \hat{C}t = S{t_s} + (C_{\text{SIGS},t} - C_{\text{SIGS},t_s}) $$
Entrée :
coverage_df: Estimations de la couverture basées sur le SIGS à partir de dénominateurs sélectionnésproj_df: Estimations projetées de l’enquête à partir deproject_survey_from_deltas()survey_raw_df: Données d’enquête originales (facultatif)
Sortie :
Cadre de données complet avec des colonnes :
- Identifiants géographiques (admin_area_1, admin_area_2, admin_area_3)
- year, indicator_common_id, denominator
coverage_cov: Couverture basée sur le SIGScoverage_original_estimate: Valeurs de l’enquête initialecoverage_avgsurveyprojection: Couverture projetée de l’enquêtesurvey_raw_source: Source des données de l’enquête (par exemple, “DHS”, “MICS”)survey_raw_source_detail: Informations détaillées sur la source
Fonctions d’aide
Section intitulée « Fonctions d’aide »Fonction d'aide : filtrage par chaîne de dénominateurs
Objectif : Filtre les résultats combinés de la partie 1 (m005) selon le paramètre DENOMINATOR_CHAIN défini dans la partie 2 (m006).
Algorithme :
- Lire
DENOMINATOR_CHAIN(auto,anc1,delivery,bcgoupenta1). - Si
auto: conserver les lignes oùdenominator_best_or_survey == "best"(la chaîne pré-sélectionnée parm005). - Si une chaîne spécifique (par exemple
anc1) : conserver les lignes oùdenominator_best_or_surveycommence par le préfixe de la chaîne (par ex.danc1_). La correspondance entre indicateur et variante de population cible a déjà été encodée parm005lorsqu’il a étendu les dénominateurs aux indicateurs ; cette étape est donc un simple filtre sur préfixe. - Supprimer les lignes
surveyrestantes et renommervalueencoverage. - Retourner la trame de données filtrée.
Entrée :
combined_results_df: Résultat de la partie 1 avec toutes les options de dénominateurchain: Valeur deDENOMINATOR_CHAIN
Sortie :
Trame de données filtrée contenant uniquement les lignes correspondant à la chaîne sélectionnée (un dénominateur par indicateur).
Fonction d'aide : `extract_survey_from_combined()`
Objectif : Extrait les valeurs brutes de l’enquête à partir des résultats combinés de la partie 1.
Algorithme :
- Filtre pour les lignes où
denominator_best_or_survey == "survey" - Renommer la colonne
valueensurvey_value - Sélectionner dynamiquement les colonnes pertinentes en fonction des niveaux d’administration présents
Entrée :
Cadre de données des résultats combinés de la partie 1
Sortie :
Cadre de données d’enquête avec colonnes : admin areas, year, indicator_common_id, survey_value
Étapes d’exécution du flux de travail
Section intitulée « Étapes d’exécution du flux de travail »La partie 2 exécute le flux de travail suivant pour chaque niveau administratif (national, admin2, admin3) :
Étape 1 : Chargement des données
- Charger les résultats combinés de la partie 1 pour tous les niveaux administratifs
- Vérifier quels niveaux administratifs disposent de données
- Extraire les données de l’enquête pour les utiliser comme base de projection
- Afficher des messages sur la disponibilité des données
Étape 2 : Pour chaque niveau d’administration
Sous-étape 1 : filtrer par sélection du dénominateur
- Appliquer les choix de dénominateur de l’utilisateur en utilisant
filter_by_denominator_selection() - Message : Nombre d’enregistrements sélectionnés
Sous-étape 2 : Calcul des deltas
- Calculer les changements de couverture d’une année sur l’autre en utilisant
coverage_deltas() - Crée des séries chronologiques complètes avec des lacunes comblées
Sous-étape 3 : projeter les valeurs de l’enquête
- Utiliser
project_survey_from_deltas()pour étendre les estimations de l’enquête - La base est ancrée dans l’enquête la plus récente
- Les projections utilisent les deltas cumulés des tendances SIGS
Sous-étape 4 : Construire les résultats finaux
- Combiner la couverture SIGS, les projections et les enquêtes initiales
- Calculer les estimations finales projetées à l’aide d’une formule additive
- Conserver toutes les métadonnées
Étape 3 : Normaliser et sauvegarder les résultats
- Définir les colonnes requises pour chaque niveau administratif
- S’assurer que toutes les colonnes requises existent (ajouter NA si elles sont manquantes)
- Ordonner les colonnes correctement
- Supprimer les colonnes inappropriées au niveau de l’administrateur
- Sauvegarder au format CSV avec l’encodage UTF-8
- Créer des fichiers vides pour les niveaux d’administration sans données
Spécifications de sortie
Section intitulée « Spécifications de sortie »La partie 2 produit trois fichiers de sortie :
1. Sortie nationale : M6_coverage_estimation_national.csv
Section intitulée « 1. Sortie nationale : M6_coverage_estimation_national.csv »Colonnes :
admin_area_1: Nom du paysyear: Année d’estimationindicator_common_id: Code de l’indicateur standardisédenominator: Nom du dénominateur issu de la chaîne sélectionnée parDENOMINATOR_CHAIN(par ex.danc1_pregnancy)coverage_original_estimate: Couverture initiale basée sur l’enquête (NA pour les années sans enquête)coverage_avgsurveyprojection: Projection de la couverture de l’enquête à l’aide des tendances SIGScoverage_cov: Estimation de la couverture basée sur le SIGS
2. Résultats du niveau 2 de l’administration : M6_coverage_estimation_admin2.csv
Section intitulée « 2. Résultats du niveau 2 de l’administration : M6_coverage_estimation_admin2.csv »Colonnes :
Identique à la colonne nationale, plus :
admin_area_2: Nom de la division administrative de deuxième niveau (par exemple, province, région)
3. Niveau administratif 3 Sortie : M6_coverage_estimation_admin3.csv
Section intitulée « 3. Niveau administratif 3 Sortie : M6_coverage_estimation_admin3.csv »Colonnes :
admin_area_1: Nom du paysadmin_area_3: Nom de la division administrative de troisième niveau (par exemple, district)year: Année d’estimationindicator_common_id: Code de l’indicateur standardisédenominator: Nom du dénominateur issu de la chaîne sélectionnéecoverage_original_estimate: Couverture de l’enquête initialecoverage_avgsurveyprojection: Couverture projetée de l’enquêtecoverage_cov: Couverture basée sur le SIGS
Note : bien que le schéma des résultats de m006 liste survey_raw_source et survey_raw_source_detail, l’étape d’écriture actuelle de m006 ne conserve que les huit colonnes ci-dessus (sept au niveau national). Les métadonnées de source et de détail d’enquête restent disponibles dans M5_combined_results_*.csv de la partie 1 si besoin.
Considérations méthodologiques
Section intitulée « Considérations méthodologiques »1. Stratégie de sélection de la chaîne de dénominateurs
Quand utiliser auto (par défaut) :
- Vous souhaitez laisser la pré-sélection par proximité au UN WPP de la partie 1 choisir la chaîne
- Point de départ pour l’analyse ou les rapports de routine
- Vous n’avez pas de raison programmatique forte de préférer une source
Quand forcer une chaîne spécifique (anc1, delivery, bcg, penta1) :
- Les connaissances programmatiques indiquent qu’un flux de déclaration SIGS (par ex. CPN1) est le plus fiable dans le pays
- Vous souhaitez assurer la cohérence dans les comparaisons entre pays en utilisant la même source partout
- Réalisation d’analyses de sensibilité pour voir comment la chaîne affecte la couverture
- Problèmes connus avec la source sélectionnée automatiquement (par ex. préoccupations sur la qualité des données dans ce flux de déclaration)
Rappelez-vous que la chaîne s’applique à tous les indicateurs et à tous les niveaux géographiques — vous ne pouvez pas mélanger les chaînes par indicateur.
2) Méthodologie de projection
L’approche de projection de la partie 2 utilise une méthode delta additive plutôt qu’un remplacement multiplicatif ou direct :
Avantages :
- Préserve le calibrage en niveau des données d’enquête
- Prolonge en douceur les estimations de l’enquête en utilisant les tendances administratives
- Évite les erreurs cumulées dues aux changements d’une année sur l’autre
- Maintient la cohérence lorsque la couverture SIGS est stable
Limites :
- Suppose que les tendances SIGS reflètent les véritables changements de couverture
- Peut diverger de la réalité si la qualité des données administratives diminue
- Les projections deviennent moins fiables à mesure que l’on s’éloigne de l’enquête de référence
- Ne tient pas compte des biais systématiques dans les données SIGS
Meilleure pratique : Les projections doivent être validées par rapport aux nouvelles données d’enquête lorsqu’elles sont disponibles, et la base de référence doit être mise à jour avec l’enquête la plus récente.
3. traitement des données manquantes
La partie 2 met en œuvre plusieurs stratégies pour les données manquantes :
- Séries temporelles complètes : La fonction
coverage_deltas()peut combler les années manquantes, créant ainsi une série continue - Les lacunes de l’enquête : Les projections étendent les estimations vers l’avant, mais les années antérieures à la première enquête restent NA
- Lacunes au niveau de l’administration : Le script détecte automatiquement et saute les niveaux d’administration pour lesquels il n’y a pas de données
- Dénominateurs manquants : Si un dénominateur sélectionné n’existe pas pour un indicateur, cette combinaison indicateur-dénominateur est omise
Cohérence de l'analyse multiniveau
La partie 2 traite chaque niveau administratif de manière indépendante :
- National : Estimations agrégées au niveau national
- Admin 2 : Estimations provinciales/régionales (la somme peut ne pas correspondre au niveau national en raison de dénominateurs différents)
- Administration 3 : Estimations au niveau du district
Important : Les estimations entre les niveaux peuvent ne pas être directement comparables si des dénominateurs différents sont sélectionnés ou si la qualité des données varie selon le niveau.
Validation et contrôles de qualité
Les utilisateurs doivent valider les résultats de la partie 2 en procédant comme suit
-
Contrôlant la vraisemblance des projections :
- Les valeurs projetées se situent-elles dans des fourchettes plausibles (0-100%) ?
- Les tendances ont-elles un sens programmatique ?
-
Comparer les dénominateurs :
- Exécuter la partie 2 avec différentes sélections de dénominateurs
- Évaluer la sensibilité des résultats au choix du dénominateur
-
Validation par rapport à de nouvelles enquêtes :
- Lorsque de nouvelles données d’enquête sont disponibles, comparer les projections aux valeurs réelles
- Mise à jour de la base de référence et nouvelle exécution si nécessaire
-
Examiner les tendances du système SIGS :
- Des écarts importants peuvent indiquer des problèmes de qualité des données
- Les changements soudains doivent faire l’objet d’une enquête
-
Cohérence au niveau de l’administration :
- Vérifier si les tendances infranationales s’alignent sur les tendances nationales
- Enquêter sur les écarts importants
Résolution des problèmes courants
Problème : “Pas de données dans les résultats combinés d’admin2”
- Cause : La partie 1 (
m005) n’a pas traité le niveau 2 de l’administration, ou il n’existe pas de données infranationales - Solution : Modifier le paramètre
ANALYSIS_LEVELde la partie 1 (par exemple surNATIONAL_ONLY) ou vérifier les entrées de la partie 1
Problème : Les projections montrent des valeurs non plausibles (>100% ou <0%)
- Cause : Erreurs importantes dans les données SIGS ou dénominateur inapproprié
- Solution : Revoir le choix du dénominateur, vérifier la qualité des données SIGS, envisager un autre dénominateur
Problème : Dénominateurs manquants dans les résultats
- Cause : Le dénominateur sélectionné n’a pas été calculé dans la partie 1 pour cet indicateur
- Solution : Vérifier les options de dénominateur de la partie 1, vérifier la compatibilité entre l’indicateur et le dénominateur
Problème : Lacunes dans la couverture projetée
- Cause : Données SIGS manquantes pour certaines années
- Solution : Examiner les résultats du module 2 et vérifier l’exhaustivité des données
Exemples de codes
Section intitulée « Exemples de codes »Exemple 1 : Exécution de la partie 1 avec les paramètres par défaut
# Set working directorysetwd("/path/to/module/directory")
# Load required librarieslibrary(dplyr)library(tidyr)library(zoo)library(stringr)library(purrr)
# Configure countryCOUNTRY_ISO3 <- "KEN" # Replace with your country code
# Use default analysis level (national + admin2)ANALYSIS_LEVEL <- "NATIONAL_PLUS_AA2"
# Run Part 1source("05_module_coverage_estimates_part1.R")La partie 1 génère des estimations de dénominateurs et sélectionne le meilleur dénominateur pour chaque indicateur sur la base d’une comparaison d’enquêtes.
Exemple 2 : Ajustement des paramètres de mortalité
# Use country-specific mortality rates from EDS or other sourcesPREGNANCY_LOSS_RATE <- 0.04 # Default: 0.03TWIN_RATE <- 0.02 # Default: 0.015STILLBIRTH_RATE <- 0.025 # Default: 0.02P1_NMR <- 0.045 # Default: 0.039P2_PNMR <- 0.030 # Default: 0.028INFANT_MORTALITY_RATE <- 0.070 # Default: 0.067UNDER5_MORTALITY_RATE <- 0.110 # Default: 0.103
# These parameters affect survival-adjusted dénominateurssource("05_module_coverage_estimates_part1.R")Sources pour les taux spécifiques aux pays : Rapports finaux des EDS, Groupe interinstitutions des Nations unies pour l’estimation de la mortalité infantile (IGME), ou statistiques nationales de l’état civil.
Exemple 3 : Exécution de la partie 2 avec une chaîne de dénominateurs fixe
# Forcer tous les calculs de couverture à utiliser la chaîne dérivée de la CPN1DENOMINATOR_CHAIN <- "anc1" # Options : "auto", "anc1", "delivery", "bcg", "penta1"
# Exécuter la partie 2 (module m006)source("06_module_coverage_estimates_part2.R")Cas d’utilisation : Lorsque les connaissances programmatiques suggèrent qu’un point d’entrée spécifique est le plus fiable pour tous les indicateurs (par exemple, une déclaration CPN1 très solide), ou pour la cohérence des comparaisons entre pays. Utilisez "auto" (par défaut) pour conserver la sélection du meilleur dénominateur indicateur par indicateur de la partie 1.
Exemple 4 : Analyse nationale uniquement pour l'évaluation rapide
# Part 1: Run national level only (faster)ANALYSIS_LEVEL <- "NATIONAL_ONLY"source("05_module_coverage_estimates_part1.R")
# Part 2: Will automatically skip infranational levelssource("06_module_coverage_estimates_part2.R")Cas d’utilisation : Analyse exploratoire initiale, ou lorsque les données d’enquêtes infranationales ne sont pas disponibles.
Exemple 5 : Analyse infranationale complète
# Part 1: Include admin3 levelANALYSIS_LEVEL <- "NATIONAL_PLUS_AA2_AA3"source("05_module_coverage_estimates_part1.R")
# Part 2: Will process all available levelssource("06_module_coverage_estimates_part2.R")Cas d’utilisation : Analyse détaillée au niveau du district lorsqu’il existe des données d’enquête infranationales.
Exemple 6 : Utilisation programmatique des résultats
# Load coverage outputscoverage_national <- read.csv("M6_coverage_estimation_national.csv")coverage_admin2 <- read.csv("M6_coverage_estimation_admin2.csv")
# Filter to specific indicatorpenta3_national <- coverage_national %>% filter(indicator_common_id == "penta3")
# Compare HMIS-based and survey-projected coveragecoverage_comparison <- penta3_national %>% select(year, coverage_cov, coverage_avgsurveyprojection, coverage_original_estimate) %>% mutate( hmis_survey_gap = coverage_cov - coverage_avgsurveyprojection, data_source = case_when( !is.na(coverage_original_estimate) ~ "Survey", !is.na(coverage_avgsurveyprojection) ~ "Projected", TRUE ~ "HMIS only" ) )
# Identify admin2 areas with coverage below thresholdlow_coverage_areas <- coverage_admin2 %>% filter(indicator_common_id == "penta3", year == max(year)) %>% filter(coverage_avgsurveyprojection < 80) %>% arrange(coverage_avgsurveyprojection)Notes d’utilisation
Section intitulée « Notes d’utilisation »Colonnes du fichier de sortie
Les fichiers de sortie de la partie 2 (M6_coverage_estimation_*.csv) contiennent :
| Colonne | Description |
|---|---|
admin_area_1 | Nom du pays |
admin_area_2 / admin_area_3 | Zone sous-nationale (le cas échéant) |
year | Année civile |
indicator_common_id | Code de l’indicateur de santé |
denominator | Nom du dénominateur issu de la chaîne sélectionnée par DENOMINATOR_CHAIN |
coverage_cov | Couverture dérivée du SIGS (numérateur ÷ dénominateur × 100) |
coverage_original_estimate | Valeur de l’enquête si disponible |
coverage_avgsurveyprojection | Valeur de l’enquête projetée à l’aide des tendances du SIGS |
Examen des options de dénominateur
Les fichiers de sortie de la partie 1 (M5_combined_results_*.csv) contiennent des estimations de couverture pour toutes les options de dénominateur. Pour les passer en revue :
- Ouvrez le fichier des résultats combinés
- Filtrez sur l’indicateur qui vous intéresse
- Comparer la colonne
valueentre les différentes entréesdenominator_best_or_survey - La ligne marquée
bestmontre le dénominateur automatiquement sélectionné - Les lignes marquées
surveymontrent les observations réelles de l’enquête
Pour annuler la sélection automatique dans la partie 2 (m006), changez le paramètre DENOMINATOR_CHAIN de "auto" à l’une des valeurs "anc1", "delivery", "bcg" ou "penta1". La chaîne sélectionnée s’applique à tous les indicateurs et niveaux géographiques.
Exigences en matière de données infranationales
Le module vérifie la disponibilité des données infranationales en deux étapes :
- Étape 1 (partie 1,
m005) : SiANALYSIS_LEVELest défini pour inclure admin2 ou admin3, le module vérifie que le jeu de données d’enquête unifié contient des lignes infranationales pour le pays. Sinon, l’ensemble du niveau d’analyse est rétrogradé enNATIONAL_ONLY. Si des données d’enquête infranationales existent mais que les noms de zones administratives ne correspondent pas aux noms HMIS, le niveau infranational concerné est sauté et l’analyse passe au niveau supérieur suivant (admin3 → admin2, admin2 → national seul). Un fichierM5_combined_results_*.csvvide est tout de même écrit pour tout niveau sauté. - Étape 2 (partie 2,
m006) : Lit les fichiersM5_combined_results_*.csvproduits par la partie 1. Si un fichier infranational a zéro ligne, le drapeauRUN_ADMIN2/RUN_ADMIN3correspondant est positionné àFALSE, l’ensemble du bloc admin2/admin3 est sauté, et unM6_coverage_estimation_*.csvvide est écrit pour ce niveau. - Les messages de la console indiquent les niveaux d’analyse en cours de traitement et ceux qui ont été sautés.
Contrôles de validation
Après avoir exécuté les deux parties, examinez les résultats pour :
- Valeurs de couverture en dehors de la plage attendue (négatives ou >100%)
- Lacunes dans les séries chronologiques (années manquantes)
- Cohérence entre
coverage_covetcoverage_avgsurveyprojection - Sélection du dénominateur dans les résultats de la partie 1
Valeur ajoutée par rapport à l’analyse DHIS2 standard
Section intitulée « Valeur ajoutée par rapport à l’analyse DHIS2 standard »DHIS2 constitue une base solide pour la collecte, le stockage et la visualisation de base des données ; FASTR vient compléter cette base avec des capacités supplémentaires : ajustement automatique de la qualité des données avant l’analyse, méthodes analytiques avancées incluant la détection des perturbations et la projection de la couverture, visualisations standardisées s’appuyant sur des approches en pourcentage de variation, estimation améliorée de la couverture utilisant des dénominateurs dérivés des enquêtes, cycles analytiques plus rapides alignés sur les calendriers de décision des pays, et renforcement intégré des capacités grâce à des méthodes reproductibles.
Dernière mise à jour : 06-05-2026 Contact : fastr@worldbank.org