Service utilization analysis
Background and purpose
Section titled “Background and purpose”Objective of the module
Section titled “Objective of the module”The Service Utilization module analyzes health service delivery patterns to detect and quantify disruptions in service volumes over time. It identifies deviations from expected service delivery patterns and estimates the magnitude of these disruptions at national, provincial, and district levels.
Using statistical process control and regression-based methods, the module compares observed service volumes with expected levels derived from historical trends and seasonal patterns. This enables routine, predictable variation (such as seasonal increases in malaria cases) to be distinguished from substantive service disruptions, including sudden declines in RMNCAH-N services—such as immunization and maternal or child health care—during periods of conflict or public health emergencies.
The analysis produces quantified estimates of service shortfalls and surpluses, enabling changes in service delivery to be systematically measured and compared across time and geographic levels.
Analytical rationale
Section titled “Analytical rationale”Service utilization data provide insight into how populations access essential health services, but observed volumes may vary for multiple reasons, including seasonality, policy changes, external shocks (such as pandemics, natural disasters, or conflict), data quality limitations, and changes in service availability. Without systematic analysis, it is difficult to distinguish normal variation from material disruptions in service delivery.
This module applies a standardized, data-driven approach to identify deviations in service utilization and to quantify their magnitude. The outputs allow emerging issues in service delivery to be detected, compared across geographic levels, and tracked over time, including during periods of disruption and recovery. The results are structured for use in routine monitoring, analytical reporting, and assessment of changes in health service performance.
Key points
Section titled “Key points”| Component | Details |
|---|---|
| Inputs | Adjusted service volumes from Module 2 (M2_adjusted_data.csv and M2_adjusted_data_admin_area.csv)Outlier flags from Module 1 ( M1_output_outliers.csv)Raw HMIS ( hmis_ISO3.csv) - only for facility_id to admin_area_1 lookup |
| Outputs | Pass-through adjusted data (M3_service_utilization.csv)Disruption flags ( M3_chartout.csv)Quantified impacts by geographic level ( M3_disruptions_analysis_admin_area_1 to _4.csv)Shortfall/surplus summaries ( M3_all_indicators_shortfalls_admin_area_1 to _4.csv) |
| Purpose | Detect and quantify service delivery disruptions through two-stage analysis: control charts identify when disruptions occur, panel regression quantifies their magnitude |
Analytical workflow
Section titled “Analytical workflow”Overview of analytical steps
Section titled “Overview of analytical steps”The module operates in two sequential parts, each with a distinct purpose:
Part 1: Control chart analysis - Identifies unusual patterns in service volumes
-
Prepare the data: Load health service data, remove previously identified outliers, aggregate to the appropriate geographic level, and fill in missing months using interpolation.
-
Model expected patterns: For each combination of health indicator and geographic area, use robust statistical methods to estimate what service volumes should look like based on historical trends and seasonal patterns (e.g., accounting for predictable increases in malaria cases during rainy season).
-
Detect deviations: Compare actual service volumes to expected patterns and identify significant deviations using multiple detection rules:
- Sharp disruptions: Single months with extreme deviations
- Sustained drops: Gradual declines over several months
- Sustained dips: Periods consistently below expected levels
- Sustained rises: Periods consistently above expected levels
- Missing data patterns: Gaps in reporting that may signal problems
-
Flag disrupted periods: Mark months where any disruption pattern is detected, ensuring recent months are always flagged for review.
Part 2: Disruption analysis - Quantifies the impact of identified disruptions
-
Apply regression models: Use panel regression at multiple geographic levels (national, provincial, district) to estimate how much service volumes changed during flagged disruption periods, controlling for trends and seasonality.
-
Calculate shortfalls and surpluses: Compare predicted volumes to actual volumes to quantify the magnitude of disruptions in absolute numbers and percentages.
-
Generate outputs: Create summary files showing disruption impacts at each geographic level, ready for visualization and reporting.
Workflow diagram
Section titled “Workflow diagram”Key decision points
Section titled “Key decision points”Geographic level of analysis
The module supports disruption analysis at multiple geographic scales. Users may limit analysis to national and provincial levels, which is computationally faster and suitable for routine monitoring, or extend the analysis to district and ward levels to obtain more granular information for targeted investigation and response.
Control chart level selection
The level at which control charts are calculated determines where statistical modeling is performed. This is configured through two flags and follows the FASTR convention in which higher administrative level numbers correspond to smaller geographic units.
-
Default configuration (both flags set to FALSE)
Control charts are calculated at an intermediate subnational level (admin_area_2). Service volumes are aggregated to this level, and trend estimation, control limit calculation, and disruption detection are performed for each geography–indicator combination. This option is the most computationally efficient and is suitable for routine monitoring. -
RUN_DISTRICT_MODEL = TRUE
Control charts are calculated at a finer subnational level (admin_area_3). Service volumes are aggregated to smaller geographic units, allowing detection of localized disruptions that may be masked at higher levels of aggregation. This option is more computationally intensive but provides greater spatial resolution. -
RUN_ADMIN_AREA_4_ANALYSIS = TRUE
Control charts are calculated at the most granular geographic level available (admin_area_4). This enables identification of highly localized or facility-level disruptions. It is the most resource-intensive option and is typically used for targeted or diagnostic analysis.
The selected control chart level determines where statistical modeling is conducted, including trend estimation, control limit calculation, and disruption flagging. Regardless of the level at which control charts are calculated, disruption results are aggregated and reported at all available geographic levels (national and subnational).
Sensitivity settings
The module uses configurable statistical thresholds to define what constitutes a disruption. More sensitive settings (lower thresholds) flag smaller deviations from expected patterns and are suitable for early warning purposes. More conservative settings (higher thresholds) restrict detection to larger deviations and are useful for focusing on major disruptions.
Treatment of reporting completeness
The module accepts alternative versions of service counts produced by Module 2, allowing users to choose whether to analyze raw reported volumes or volumes adjusted for reporting completeness. This provides flexibility to align disruption analysis with different data quality assumptions.
Data processing and outputs
Section titled “Data processing and outputs”Input transformation
The module begins with facility-level monthly service counts (for example, deliveries reported by each facility). These data are aggregated to the selected geographic level. Observations identified as outliers in Module 1 are excluded to prevent anomalous values from influencing trend estimation and control limits.
Pattern estimation and detection
Using robust statistical methods, the module estimates expected service utilization patterns for each indicator and geographic unit based on historical data, accounting for long-term trends and seasonality. Months in which observed service volumes deviate significantly from these expected patterns are flagged as potential disruptions.
Quantification of disruption impacts
For periods identified as disrupted, regression-based models are used to estimate counterfactual service volumes—representing expected utilization in the absence of disruption. Differences between predicted and observed volumes are calculated to quantify service shortfalls or surpluses.
Output structure
The final outputs report disruption metrics at multiple geographic levels, from national summaries to detailed local results. The original reported data are preserved, with additional fields providing expected values, disruption flags, and quantified impacts.
Analysis outputs and visualization
Section titled “Analysis outputs and visualization”The FASTR analysis generates four main visual outputs for service utilization:
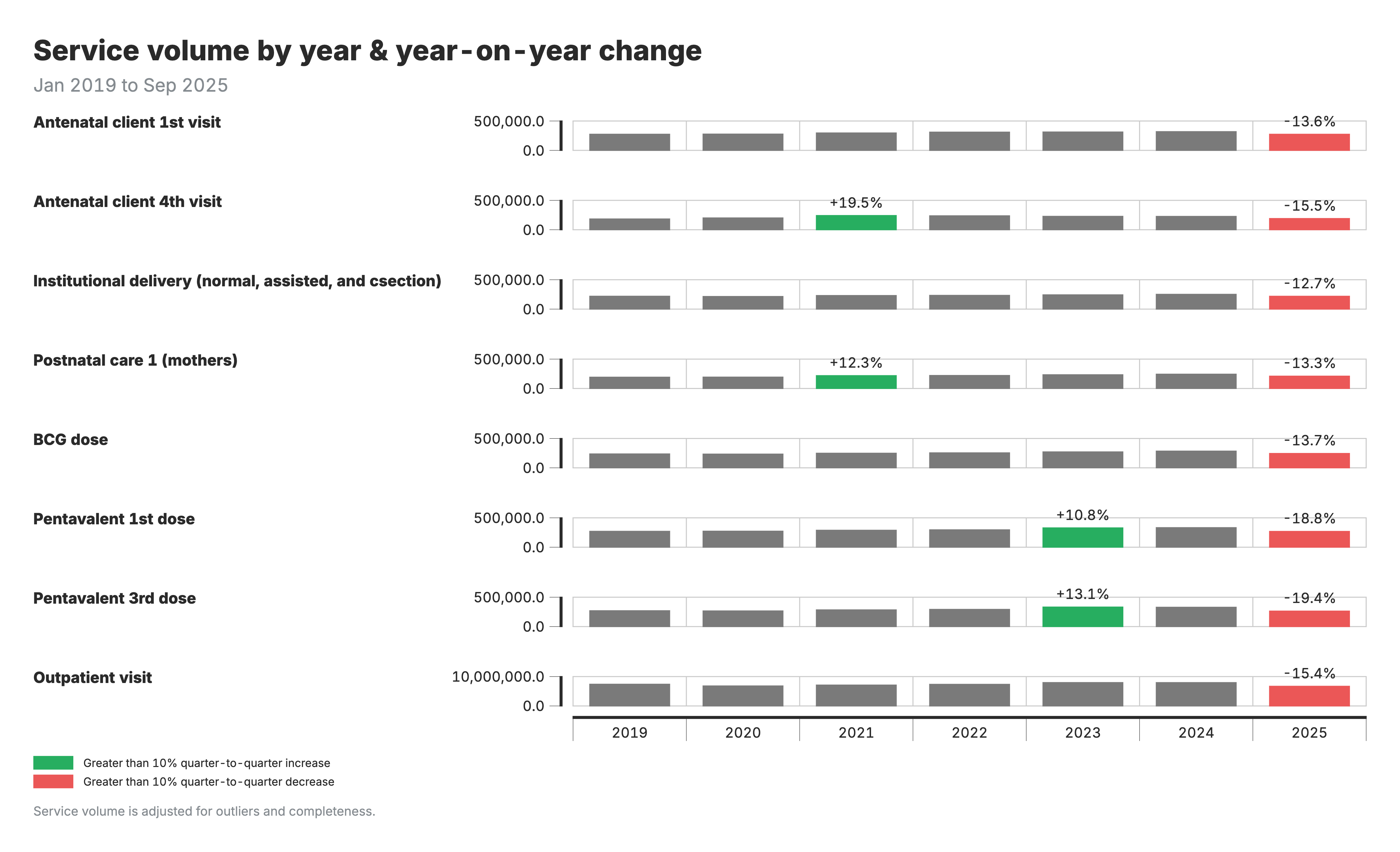
1. Change in service volume
Bar chart showing annual service volumes by region and indicator, with year-on-year percent change annotations.
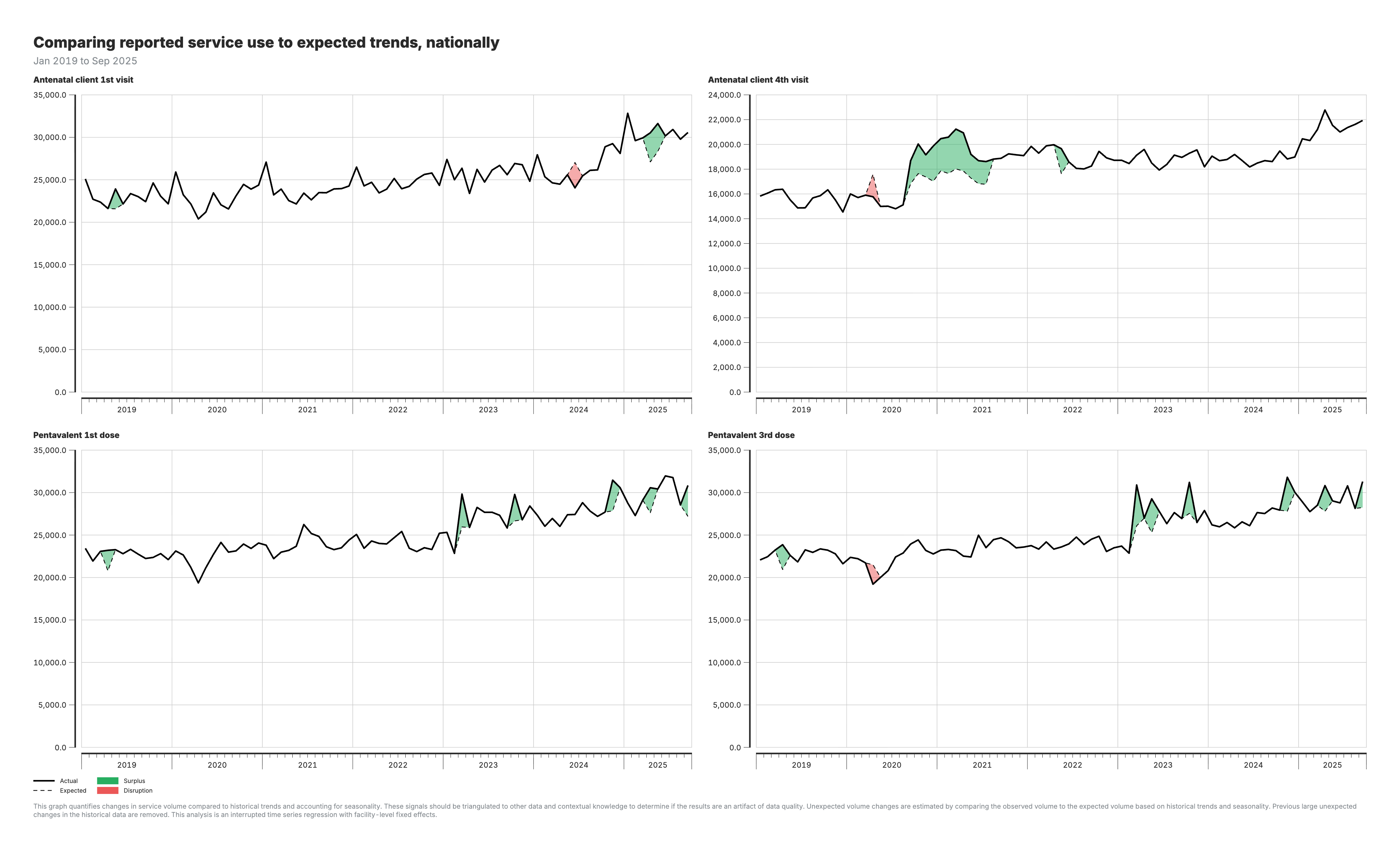
2. Actual vs expected services (national)
Line chart comparing observed service volumes against model predictions at the national level.
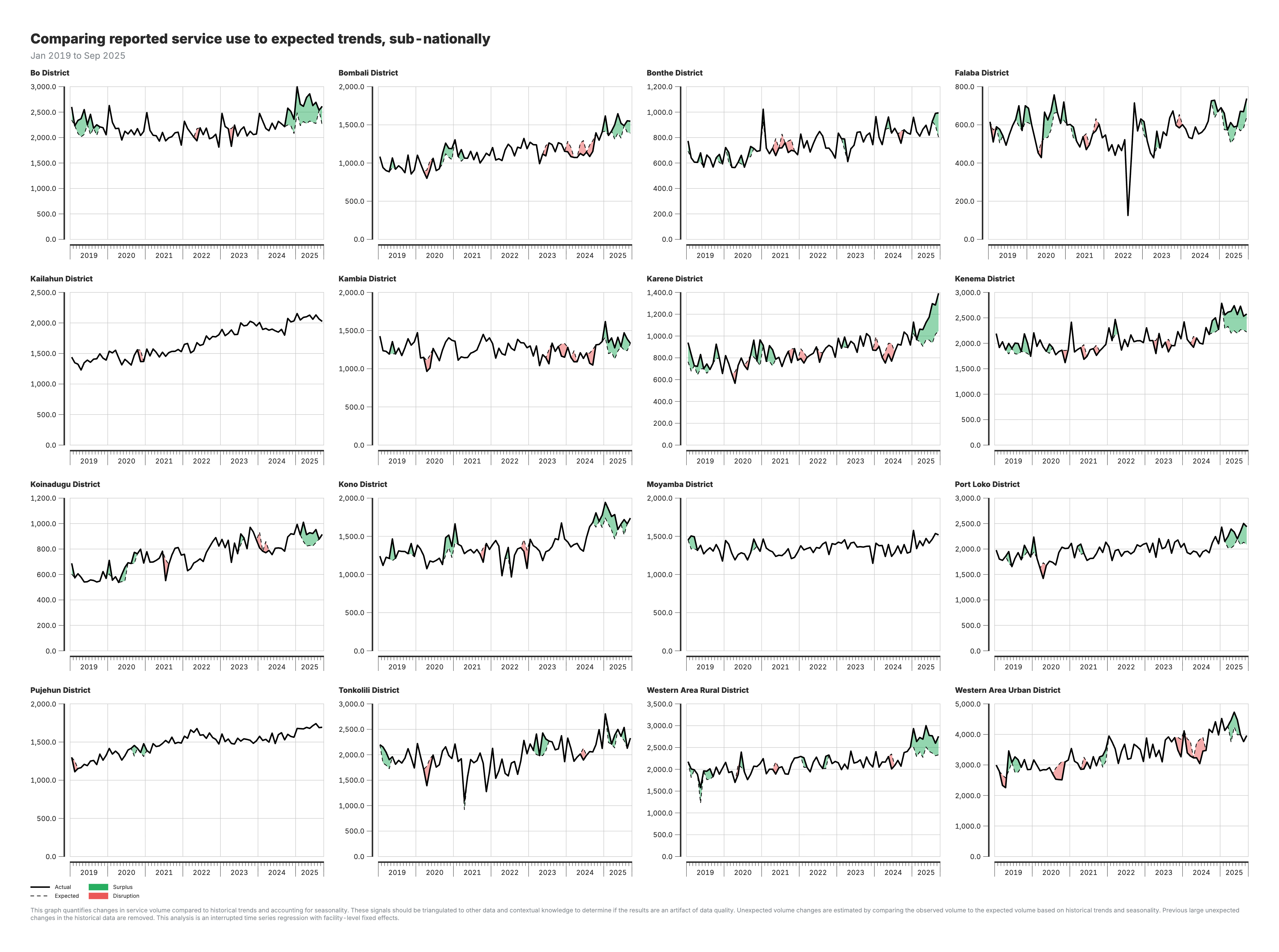
3. Actual vs expected services (subnational)
Line charts by region comparing observed volumes to expected patterns.
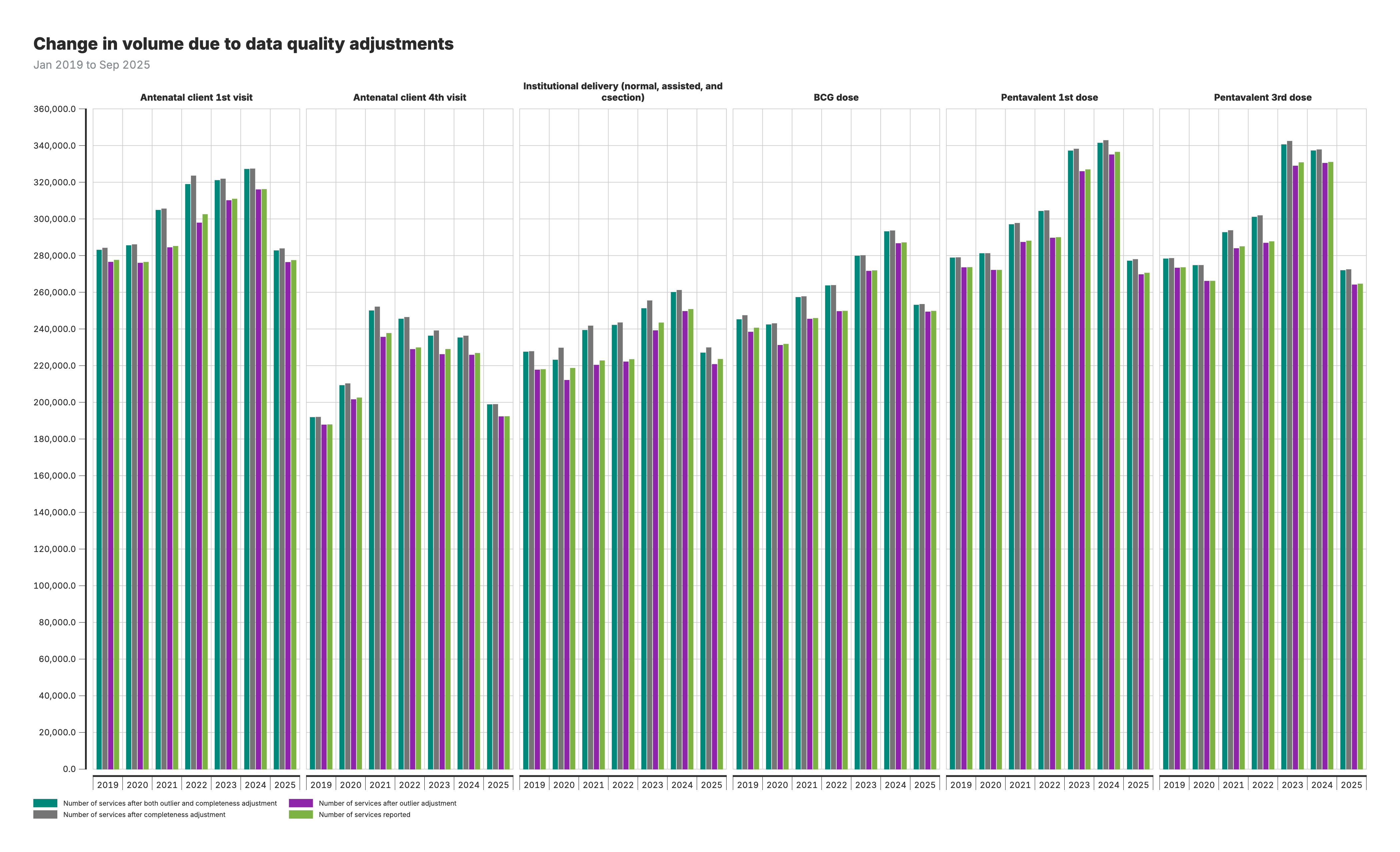
4. Volume change due to data quality adjustments
Grouped bar chart comparing service volumes across four adjustment scenarios: no adjustment, outlier adjustment only, completeness adjustment only, and both adjustments.
Interpretation guide
For the change in service volume chart (output 1):
- Bars: Annual service volumes by region
- Annotations: Year-on-year percent change between consecutive years
For the actual vs expected charts (outputs 2–3):
- Black line: Actual (observed) service volumes
- Red shaded areas: Shortfall periods (actual below expected)
- Green shaded areas: Surplus periods (actual above expected)
For the volume change chart (output 4):
- Four bars per year: Each bar represents a different adjustment scenario
- Compare bar heights to see how adjustments affect reported volumes
Detailed reference
Section titled “Detailed reference”Configuration parameters
Section titled “Configuration parameters”Core analysis parameters
| Parameter | Default | Type | Description | Tuning Guidance |
|---|---|---|---|---|
COUNTRY_ISO3 | ”ISO3” | String | Three-letter country code | Set to your country code (e.g., “RWA”, “UGA”, “ZMB”) |
SELECTEDCOUNT | ”count_final_outliers” | String | Data column used for regression modeling | Options: count_final_none, count_final_outliers, count_final_completeness, count_final_both |
VISUALIZATIONCOUNT | ”count_final_outliers” | String | Data column used for visualization | Same options as SELECTEDCOUNT; can differ if you want to model on one and plot another |
Control chart parameters
| Parameter | Default | Type | Description | Tuning Guidance |
|---|---|---|---|---|
SMOOTH_K | 7 | Integer (odd) | Rolling median window size in months | Larger values = smoother trends, less sensitivity. Must be odd number (e.g., 5, 7, 9, 11) |
MADS_THRESHOLD | 1.5 | Numeric | MAD units threshold for sharp disruptions | Lower = more sensitive (e.g., 1.0), higher = more conservative (e.g., 2.0) |
DIP_THRESHOLD | 0.90 | Numeric | Proportion threshold for sustained dips | 0.90 = flag if below 90% of expected (10% drop). Use 0.80 for 20% drop threshold |
DIFFPERCENT | 10 | Numeric | Percentage threshold for plotting disruptions | If actual differs from predicted by >10%, use predicted value in visualizations |
Note: RISE_THRESHOLD is automatically calculated as 1 / DIP_THRESHOLD (default: ~1.11) to mirror dip detection symmetrically.
Geographic analysis parameters
| Parameter | Default | Type | Description | Tuning Guidance |
|---|---|---|---|---|
CONTROL_CHART_LEVEL | Auto-set | String | Geographic level for control charts | Automatically set based on RUN_DISTRICT_MODEL and RUN_ADMIN_AREA_4_ANALYSIS |
RUN_DISTRICT_MODEL | FALSE | Logical | Whether to run admin_area_3 regressions | Set TRUE for district-level analysis (increases runtime) |
RUN_ADMIN_AREA_4_ANALYSIS | FALSE | Logical | Whether to run admin_area_4 analysis | Set TRUE for finest-level analysis (very slow for large datasets) |
Data source parameters
| Parameter | Default | Type | Description |
|---|---|---|---|
PROJECT_DATA_HMIS | ”hmis_ISO3.csv” | String | Filename for raw HMIS data |
Parameter selection guide
For high-sensitivity analysis (detecting smaller disruptions):
MADS_THRESHOLD = 1.0DIP_THRESHOLD = 0.95(5% drop)SMOOTH_K = 5(less smoothing)
For conservative analysis (only major disruptions):
MADS_THRESHOLD = 2.0DIP_THRESHOLD = 0.80(20% drop)SMOOTH_K = 9or11(more smoothing)
For faster runtime:
RUN_DISTRICT_MODEL = FALSERUN_ADMIN_AREA_4_ANALYSIS = FALSECONTROL_CHART_LEVEL = "admin_area_2"
Input/output specifications
Section titled “Input/output specifications”Input requirements
Primary Inputs
Section titled “Primary Inputs”-
M2_adjusted_data.csv(main data source)- Output from Module 2 (Data Quality Adjustments)
- Contains adjusted service counts with different completeness assumptions
- Required columns:
facility_id,indicator_common_id,period_id,count_final_none,count_final_outliers,count_final_completeness,count_final_both
-
M1_output_outliers.csv- Output from Module 1 (Data Quality Assessment)
- Contains
outlier_flagto identify and exclude anomalous data points - Required columns:
facility_id,indicator_common_id,period_id,outlier_flag
-
hmis_ISO3.csv(used only for geographic lookup)- Raw HMIS file used solely to extract facility_id → admin_area_1 mapping
- Required because M2_adjusted_data.csv does not include admin_area_1
- Required columns:
facility_id,admin_area_1
Data Requirements
Section titled “Data Requirements”- Temporal coverage: Minimum 12 months of data for seasonal modeling
- Data completeness: Missing months are filled using interpolation
- Geographic completeness: Data at specified administrative levels
- Count data: Non-negative integer counts (predictions are bounded at zero)
Outputs
Section titled “Outputs”1. Control Chart Results
Section titled “1. Control Chart Results”M3_chartout.csv
Purpose: Contains flagged disruptions from the control chart analysis
Columns:
admin_area_*: Geographic identifier (level depends onCONTROL_CHART_LEVEL)indicator_common_id: Health service indicator codeperiod_id: Time period in YYYYMM formattagged: Binary flag (1 = disruption detected, 0 = normal)
Use: Identifies which months require further investigation for each indicator-geography combination
M3_service_utilization.csv
Purpose: Pass-through copy of adjusted data for visualization
Source: Direct copy of M2_adjusted_data.csv
Use: Provides baseline data for plotting actual service volumes
M3_memory_log.txt
Purpose: Tracks memory usage throughout execution
Use: Diagnostics for performance optimization and troubleshooting
2. Disruption Analysis Results
Section titled “2. Disruption Analysis Results”M3_disruptions_analysis_admin_area_1.csv (National level - always generated)
Columns:
admin_area_1: Country nameindicator_common_id: Health service indicatorperiod_id: Time period (YYYYMM)count_sum: Actual service volume (sum across all facilities)count_expect_sum: Expected service volume (sum of predictions)count_expected_if_above_diff_threshold: Value for plotting (expected if |difference| > DIFFPERCENT, otherwise actual)
M3_disruptions_analysis_admin_area_2.csv (Province level - always generated)
Additional column: admin_area_2 (province/region name)
Same structure: As admin_area_1 file but disaggregated by province
M3_disruptions_analysis_admin_area_3.csv (District level - conditional)
Generated when: RUN_DISTRICT_MODEL = TRUE
Additional columns: admin_area_2, admin_area_3
Same structure: As above but disaggregated by district
M3_disruptions_analysis_admin_area_4.csv (Ward level - conditional)
Generated when: RUN_ADMIN_AREA_4_ANALYSIS = TRUE
Additional columns: admin_area_2, admin_area_3, admin_area_4
Warning: Very large file size for countries with many wards
3. Shortfall/Surplus Summary Files
Section titled “3. Shortfall/Surplus Summary Files”M3_all_indicators_shortfalls_admin_area_*.csv (one for each geographic level)
Purpose: Pre-calculated shortfall and surplus metrics for reporting
Common columns:
- Geographic identifier(s):
admin_area_* indicator_common_id: Health service indicatorperiod_id: Time period (YYYYMM)count_sum: Actual service volumecount_expect_sum: Expected service volumeshortfall_absolute: Absolute number of missing services (if negative disruption)shortfall_percent: Percentage shortfall relative to expectedsurplus_absolute: Absolute number of excess services (if positive disruption)surplus_percent: Percentage surplus relative to expected
Note: If optional geographic levels are disabled, empty placeholder files are created for compatibility with downstream processes.
Temporary Files (Automatically Cleaned)
Section titled “Temporary Files (Automatically Cleaned)”During execution, the module creates temporary batch files for memory management:
M3_temp_controlchart_batch_*.csvM3_temp_indicator_batch_*.csvM3_temp_province_batch_*.csvM3_temp_district_batch_*.csvM3_temp_admin4_batch_*.csv
These are automatically deleted upon successful completion. If the script crashes, these files may remain and will be cleaned up on the next run.
Key functions documentation
Section titled “Key functions documentation”`robust_control_chart(panel_data, selected_count)`
Purpose: Identifies anomalies in service utilization using robust regression and MAD-based control limits.
Inputs:
panel_data: Time series data for a specific indicator-geography combinationselected_count: Column name containing service volume counts to analyze
Process:
- Fits a robust linear model (using
MASS::rlm()) with seasonal controls and time trends - Applies rolling median smoothing to predicted values to reduce noise
- Calculates residuals and standardizes them using Median Absolute Deviation (MAD)
- Applies rule-based tagging logic to identify different disruption types
- Flags recent months automatically to ensure timely detection
Outputs:
count_predict: Predicted service volume from robust regressioncount_smooth: Smoothed predictions using rolling medianresidual: Difference between actual and smoothed valuesrobust_control: Standardized residual (residual/MAD)tagged: Binary flag (1 = disruption detected, 0 = normal variation)- Additional flags:
tag_sharp,tag_sustained,tag_sustained_dip,tag_sustained_rise,tag_missing
Key features:
- Handles missing data gracefully with interpolation
- Uses robust regression to minimize influence of outliers
- Employs multiple disruption detection rules for different patterns
- Ensures non-negative predictions (counts cannot be negative)
Panel Regression Models
Section titled “Panel Regression Models”The disruption analysis uses panel regression models (fixest::feols()) at multiple geographic levels. Separate regressions are run for each geographic unit at each level, with clustered standard errors to account for within-area correlation.
Country-wide Model (Admin Area 1):
count ~ date + factor(month) + taggedSingle regression across all facilities, with standard errors clustered at district level (admin_area_3) when more than one district is available; otherwise unclustered.
Province-level Models (Admin Area 2):
count ~ date + factor(month) + taggedSeparate regression run for each province, with standard errors clustered at district level when more than one district is available; otherwise unclustered.
District-level Models (Admin Area 3 - optional):
count ~ date + factor(month) + taggedSeparate regression run for each district (minimum 10 observations required), with standard errors clustered at ward level (admin_area_4) when more than one ward is available; otherwise unclustered.
Ward-level Models (Admin Area 4 - optional):
count ~ date + factor(month) + taggedSeparate regression run for each ward/finest unit (minimum 8 observations required, no clustering).
Supporting Functions
Section titled “Supporting Functions”mem_usage(msg): Tracks and logs memory consumption throughout execution
Data processing:
- Batch processing with disk-based temporary files for memory efficiency
- Efficient data.table operations for large datasets
- Progressive aggregation and merging strategies
Statistical methods & algorithms
Section titled “Statistical methods & algorithms”Control chart analysis
Service volumes are aggregated at the specified geographic level (configurable via CONTROL_CHART_LEVEL). The pipeline removes outliers (outlier_flag == 1), fills in missing months, and filters low-volume months (<50% of global mean volume).
A robust regression model estimates expected service volumes per indicator × geographic area (panelvar). A centered rolling median is applied to smooth the predicted values. Residuals (actual - smoothed) are standardized using MAD. Disruptions are identified using a rule-based tagging system.
Disruption Detection Rules
Section titled “Disruption Detection Rules”Each rule is controlled by user-defined parameters, allowing customization of the sensitivity and behavior of the detection logic:
Sharp disruptions: Flags a single month when the standardized residual (residual divided by MAD) exceeds a threshold:
$$ \left| \frac{\text{residual}}{\text{MAD}} \right| \geq \text{MADS_THRESHOLD} $$
- Parameter:
MADS_THRESHOLD(default:1.5) - Lower values make the detection more sensitive to sudden spikes or dips.
Sustained drops: Flags a sustained drop if:
- Three consecutive months show mild deviations (standardized residual ≥ 1 but <
MADS_THRESHOLD), and - The current month has a standardized residual ≥ 1.5 (hardcoded threshold).
This captures slower, compounding declines.
Sustained dips: Flags periods where the actual volume falls consistently below a defined proportion of expected volume (smoothed prediction):
$$ \text{count_original} < \text{DIP_THRESHOLD} \times \text{count_smooth} $$
- Parameter:
DIP_THRESHOLD(default:0.90) - Users can adjust this to detect deeper or shallower dips (e.g.,
0.80for a 20% drop).
Sustained rises: Symmetric to dips, flags periods of consistent overperformance:
$$ \text{count_original} > \text{RISE_THRESHOLD} \times \text{count_smooth} $$
- Parameter:
RISE_THRESHOLD(default:1 / DIP_THRESHOLD, e.g.,1.11) - Users can adjust this to detect upward surges in volume.
Missing data: Flags when 2 or more of the past 3 months have missing (NA) or zero service volume.
- Fixed rule.
Recent tail override: Automatically flags all months in the last 6 months of data to ensure recent trends are reviewed, even if model-based tagging is not conclusive.
- Fixed rule.
Final flag: A month is assigned tagged = 1 if any of the following conditions are met:
tag_sharp == 1tag_sustained == 1tag_sustained_dip == 1tag_sustained_rise == 1tag_missing == 1- It falls within the most recent 6 months (
last_6_months == 1)
Robust Regression Model
Section titled “Robust Regression Model”Model fitting:
If ≥12 observations and >12 unique dates:
$$Y_{it} = \beta_0 + \sum \gamma_m \cdot \text{month}m + \beta_1 \cdot \text{date} + \epsilon{it}$$
If only ≥12 observations:
$$Y_{it} = \beta_0 + \beta_1 \cdot \text{date} + \epsilon_{it}$$
If insufficient data: use the median of observed values.
Apply rolling median smoothing to predictions:
$$ \text{count_smooth}{it} = \text{Median}(\text{count_predict}{t-k}, \dots, \text{count_predict}t, \dots, \text{count_predict}{t+k}) $$
- Parameter:
SMOOTH_K(default: 7, must be odd) - Larger
SMOOTH_Ksmooths more; smaller retains more variation.
Calculate residuals:
$$ \text{residual}{it} = \text{count_original}{it} - \text{count_smooth}_{it} $$
Standardize residuals using MAD:
$$ \text{robust_control}{it} = \text{residual}{it} / \text{MAD}_i $$
Disruption Analysis Regression Models
Section titled “Disruption Analysis Regression Models”Once anomalies are identified and saved in M3_chartout.csv, the disruption analysis quantifies their impact using regression models. These models estimate how much service utilization changed during the flagged disruption periods by adjusting for long-term trends and seasonal variations.
For each indicator, we estimate:
$$ Y_{it} = \beta_0 + \beta_1 \cdot \text{date} + \sum_{m=1}^{12} \gamma_m \cdot \text{month}m + \beta_2 \cdot \text{tagged} + \epsilon{it} $$
where:
- $Y_{it}$ is the observed service volume,
- $\text{date}$ captures time trends,
- $\text{month}_m$ controls for seasonality,
- $\text{tagged}$ is the disruption dummy (from the control chart analysis),
- $\epsilon_{it}$ is the error term.
The coefficient on tagged ($\beta_2$) measures the relative change in service utilization during flagged disruptions. Separate regressions are run at the national, province and district levels to assess the impact across different geographic scales.
Country-wide Regression
Section titled “Country-wide Regression”The country-wide regression estimates how service utilization changes at the national level when a disruption occurs. Instead of analyzing individual provinces or districts separately, this model considers the entire country’s data in a single regression. Errors are clustered at the lowest available geographic level (lowest_geo_level), typically districts.
Model specification:
$$Y_{it} = \beta_0 + \beta_1 \cdot \text{date} + \sum_{m=1}^{12} \gamma_m \cdot \text{month} + \beta_2 \cdot \text{tagged} + \epsilon_{it}$$
Where:
- $Y_{it}$ = volume (e.g., number of deliveries)
- $\text{date}$ = time trend
- $\text{month}_m$ = controls for seasonality (factor variable)
- $\text{tagged}$ = dummy for disruption period
- $\epsilon_{it}$ = error term, clustered at the district level (
admin_area_3)
Province-level Regression
Section titled “Province-level Regression”The province-level disruption regression estimates how service utilization changes at the province level when a disruption occurs. Unlike the country-wide model, this approach runs separate regressions for each province to capture regional variations.
Model specification (run separately for each province):
$$Y_{it} = \beta_0 + \beta_1 \cdot \text{date} + \sum_{m=1}^{12} \gamma_m \cdot \text{month} + \beta_2 \cdot \text{tagged} + \epsilon_{it}$$
Where:
- $Y_{it}$ = volume (e.g., number of deliveries)
- $\text{date}$ = time trend
- $\text{month}_m$ = controls for seasonality (factor variable)
- $\text{tagged}$ = dummy for disruption period
- $\epsilon_{it}$ = error term, clustered at the district level
District-level Regression
Section titled “District-level Regression”The district-level disruption regression estimates how service utilization changes at the district level when a disruption occurs. This approach runs separate regressions for each district to capture localized variations.
Model specification (run separately for each district):
$$Y_{it} = \beta_0 + \beta_1 \cdot \text{date} + \sum_{m=1}^{12} \gamma_m \cdot \text{month} + \beta_2 \cdot \text{tagged} + \epsilon_{it}$$
Where:
- $Y_{it}$ = volume (e.g., number of deliveries)
- $\text{date}$ = time trend
- $\text{month}_m$ = controls for seasonality (factor variable)
- $\text{tagged}$ = dummy for disruption period
- $\epsilon_{it}$ = error term, clustered at the ward level (
admin_area_4) if multiple clusters available
Regression Outputs
Section titled “Regression Outputs”Each regression level produces the following outputs:
Expected values (expect_admin_area_*): Predicted service volume adjusted for seasonality and trends.
Disruption effect (b_admin_area_*): Estimated relative change during disruptions:
$$ b_{\text{admin_area_*}} = -\frac{\text{diff mean}}{\text{predict mean}} $$
Trend coefficient (b_trend_admin_area_*): Reflects long-term trend.
- Positive = increasing service use
- Negative = declining service use
- Near zero = stable trend
P-value (p_admin_area_*): Measures statistical significance of the disruption effect.
- Lower values = stronger evidence of true disruption
Statistical Methods Used
Section titled “Statistical Methods Used”Robust regression (MASS::rlm):
- Uses iteratively reweighted least squares (IRLS)
- Minimizes influence of outliers and extreme values
- More resistant to model misspecification than ordinary least squares
- Default: Huber weighting with maximum 100 iterations
MAD (Median Absolute Deviation):
- Robust measure of scale/variability
- Formula:
MAD = median(|x - median(x)|) - More resistant to outliers than standard deviation
- Used to standardize residuals for anomaly detection
Panel regression (fixest::feols):
- Fixed-effects estimation with clustered standard errors
- Accounts for within-group correlation in errors
- More efficient than traditional panel regression packages
- Handles unbalanced panels gracefully
Geographic clustering:
- Regressions use clustered standard errors at the lowest available geographic level
- This accounts for within-area correlation in service delivery patterns
- Example: Country-wide model clusters by district, province model clusters by district
- Prevents underestimation of standard errors and false positives
Detailed analysis steps
Section titled “Detailed analysis steps”Part 1: Control chart analysis
Step 1: Prepare the Data
Section titled “Step 1: Prepare the Data”- Load adjusted service volumes from
M2_adjusted_data.csv. - Load outlier flags from
M1_output_outliers.csv. - Load raw HMIS only to extract
facility_id → admin_area_1lookup (then discard). - Merge outlier flags into adjusted data by facility × indicator × month.
- Remove rows flagged as outliers (
outlier_flag == 1). - Create a
datevariable fromperiod_idand extractyearandmonth. - Create a unique
panelvarfor each geographic area-indicator combination. - Aggregate data to the specified geographic level by summing
count_model(based onSELECTEDCOUNT) by date. - Fill in missing months within each panel to ensure continuity.
- Fill missing metadata using forward and backward fill.
Step 2: Filter Out Low-Volume Months
Section titled “Step 2: Filter Out Low-Volume Months”- Compute the global mean service volume for each
panelvar. - If
count_originalis <50% of the global mean, drop the value by setting it toNA.
Step 3: Apply Regression and Smoothing
Section titled “Step 3: Apply Regression and Smoothing”Estimate expected service volume using robust regression, then smooth the predicted trend.
- Fit robust regression (
rlm) for each panel using one of three model specifications based on data availability. - Apply rolling median smoothing to predictions using window size
SMOOTH_K. - If smoothing is not possible (e.g., at series edges), fallback to model predictions.
- Calculate residuals: actual - smoothed
- Standardize residuals using MAD
This standardized control variable is used to detect anomalies in Step 4.
Step 4: Tag Disruptions
Section titled “Step 4: Tag Disruptions”Apply rule-based tagging to identify potential disruptions. Each rule is governed by user-defined parameters that can be tuned for sensitivity:
- Sharp disruptions: Tag if
|robust_control| ≥ MADS_THRESHOLD - Sustained drops: Tag if 3 consecutive months have mild deviations (residual ≥ 1 but < MADS_THRESHOLD) and current month has residual ≥ 1.5
- Sustained dips: Tag entire sequence if
count_original < DIP_THRESHOLD × count_smoothfor 3+ months - Sustained rises: Tag entire sequence if
count_original > RISE_THRESHOLD × count_smoothfor 3+ months - Missing data: Tag if 2+ of past 3 months are missing or zero
- Recent tail override: Automatically tag all months in last 6 months of data
A month is assigned tagged = 1 if any of the above conditions are met. Tagged records are saved in M3_chartout.csv and passed to the disruption analysis.
Part 2: Disruption analysis
Step 1: Data Preparation
Section titled “Step 1: Data Preparation”- The
M3_chartoutdataset is merged with the main dataset to integrate thetaggedvariable, which identifies flagged disruptions. - The lowest available geographic level (
lowest_geo_level) is identified for clustering, based on the highest-resolutionadmin_area_*column available.
Step 2: National-Level Regression
Section titled “Step 2: National-Level Regression”For each indicator_common_id, estimate the national-level model with errors clustered at district level.
- A panel regression model is applied at the country-wide level, estimating the expected service volume (
expect_admin_area_1) for each indicator. - The model controls for long-term trends and seasonal patterns in service utilization.
- When a disruption (
tagged = 1) is identified, predicted service volumes are adjusted by removing the estimated disruption effect to isolate its impact.
Step 3: Intermediate Subnational-Level Regression
Section titled “Step 3: Intermediate Subnational-Level Regression”For each indicator_common_id × admin_area_2 combination, subnational models are estimated, with standard errors clustered at a lower administrative level.
- A fixed-effects panel regression model is applied at an intermediate subnational level, estimating expected service volumes (
expect_admin_area_2) while accounting for time-invariant geographic characteristics. - The model controls for historical trends and seasonality.
- When a disruption is identified, predicted volumes are adjusted to isolate the disruption effect.
Step 4: Fine Subnational-Level Regression (if RUN_DISTRICT_MODEL = TRUE)
Section titled “Step 4: Fine Subnational-Level Regression (if RUN_DISTRICT_MODEL = TRUE)”For each indicator_common_id × admin_area_3 combination, subnational models are estimated, with standard errors clustered at the ward level (admin_area_4) when more than one ward is available.
- A fixed-effects panel regression model is applied at a fine subnational level, estimating expected service volumes (
expect_admin_area_3). - Panels with fewer than 10 observations are skipped.
- The model controls for historical trends and seasonality.
- When a disruption is identified, predicted volumes are adjusted to isolate the disruption effect.
Step 5: Ward-Level Regression (if RUN_ADMIN_AREA_4_ANALYSIS = TRUE)
Section titled “Step 5: Ward-Level Regression (if RUN_ADMIN_AREA_4_ANALYSIS = TRUE)”For each indicator_common_id × admin_area_4 combination, ward-level models are estimated without clustering.
- A panel regression model is applied at the finest geographic level, estimating expected service volumes (
expect_admin_area_4). - Panels with fewer than 8 observations are skipped.
- The model controls for historical trends and seasonality.
- When a disruption is identified, predicted volumes are adjusted to isolate the disruption effect.
Step 6: Prepare Outputs for Visualization
Section titled “Step 6: Prepare Outputs for Visualization”Once expected values have been calculated for each level (country, province, district), the pipeline compares predicted and actual values to assess the magnitude of disruption.
For each month and indicator, the pipeline calculates:
- Absolute and percentage difference between predicted and actual values:
$$ \text{diff_percent} = 100 \times \frac{\text{predicted} - \text{actual}}{\text{predicted}} $$
-
A configurable threshold parameter
DIFFPERCENT(default:10) is used to determine when a disruption is significant.If the percentage difference exceeds ±10%, the expected (predicted) value is retained and used for plotting and summary statistics. Otherwise, the actual observed value is used.
This ensures that minor fluctuations do not lead to artificial disruptions in the visualization, while meaningful deviations are preserved.
-
The final adjusted value for plotting is stored in a field such as
count_expected_if_above_diff_threshold.This value reflects either:
- The predicted count (if deviation > threshold), or
- The actual count (if within acceptable range).
This logic is applied consistently across all admin levels. These adjusted values are then exported as part of the final output files for each level.
Code examples
Section titled “Code examples”Example 1: Running the module with default settings
# Set working directorysetwd("/path/to/module/directory")
# Load required librarieslibrary(data.table)library(lubridate)library(zoo)library(MASS)library(fixest)library(stringr)library(dplyr)library(tidyr)
# Configure countryCOUNTRY_ISO3 <- "SLE"PROJECT_DATA_HMIS <- "hmis_SLE.csv"
# Use default settings (admin_area_2 level analysis)RUN_DISTRICT_MODEL <- FALSERUN_ADMIN_AREA_4_ANALYSIS <- FALSE
# Run the modulesource("03_module_service_utilization.R")With default settings, the module runs control chart analysis at admin_area_2 level and produces disruption estimates for national and regional levels.
Example 2: Adjusting disruption detection sensitivity
# Make disruption detection more sensitive (lower thresholds)MADS_THRESHOLD <- 1.0 # Flag at 1 MAD (default: 1.5)DIP_THRESHOLD <- 0.95 # Flag if <95% of expected (default: 0.90)SMOOTH_K <- 5 # Smaller smoothing window (default: 7)
# Make disruption detection less sensitive (higher thresholds)MADS_THRESHOLD <- 2.0 # Flag only at 2 MADsDIP_THRESHOLD <- 0.80 # Flag only if <80% of expectedSMOOTH_K <- 9 # Larger smoothing window
source("03_module_service_utilization.R")Use case: Adjust sensitivity based on data quality. Noisier data may require less sensitive thresholds to avoid false positives.
Example 3: Running district-level analysis
# Enable district-level analysis (slower but more detailed)RUN_DISTRICT_MODEL <- TRUERUN_ADMIN_AREA_4_ANALYSIS <- FALSE
source("03_module_service_utilization.R")Use case: When district-level disruption patterns are needed for sub-national program planning.
Note: District-level analysis increases runtime substantially. For large countries, consider running overnight.
Example 4: Selecting adjustment scenario for analysis
# Use unadjusted data for sensitivity analysisSELECTEDCOUNT <- "count_final_none"VISUALIZATIONCOUNT <- "count_final_none"
# Use outlier-adjusted onlySELECTEDCOUNT <- "count_final_outliers"VISUALIZATIONCOUNT <- "count_final_outliers"
# Use fully adjusted data (default)SELECTEDCOUNT <- "count_final_both"VISUALIZATIONCOUNT <- "count_final_both"
source("03_module_service_utilization.R")Use case: Compare disruption estimates across different data quality adjustment scenarios.
Example 5: Memory optimization for large datasets
# Reduce batch sizes for memory-constrained environmentsBATCH_SIZE_CC <- 50 # Control chart batches (default: 100)BATCH_SIZE_IND <- 3 # Indicator batches (default: 5)BATCH_SIZE_PROV <- 10 # Province batches (default: 20)BATCH_SIZE_DIST <- 10 # District batches (default: 15)
# Disable memory-intensive analysesRUN_DISTRICT_MODEL <- FALSERUN_ADMIN_AREA_4_ANALYSIS <- FALSE
source("03_module_service_utilization.R")Use case: Running on machines with limited RAM (<8GB).
Example 6: Programmatic use of outputs
# Load disruption analysis outputsdisruptions_national <- read.csv("M3_disruptions_analysis_admin_area_1.csv")shortfalls_national <- read.csv("M3_all_indicators_shortfalls_admin_area_1.csv")
# Calculate total service shortfall by indicatorannual_shortfalls <- shortfalls_national %>% mutate(year = period_id %/% 100) %>% group_by(indicator_common_id, year) %>% summarise( total_expected = sum(count_expect_sum, na.rm = TRUE), total_actual = sum(count_sum, na.rm = TRUE), total_shortfall = sum(shortfall_absolute, na.rm = TRUE), avg_shortfall_pct = mean(shortfall_percent, na.rm = TRUE), .groups = "drop" )
# Identify months with largest disruptionsworst_months <- shortfalls_national %>% filter(shortfall_percent > 10) %>% arrange(desc(shortfall_percent)) %>% head(20)
# Load control chart results for detailed analysiscontrol_chart <- read.csv("M3_chartout.csv")
# Count tagged periods by indicatortagged_summary <- control_chart %>% group_by(indicator_common_id) %>% summarise( total_periods = n(), tagged_periods = sum(tagged, na.rm = TRUE), pct_tagged = 100 * tagged_periods / total_periods, .groups = "drop" )Troubleshooting
Section titled “Troubleshooting”Common issues and solutions
Issue: Script crashes with “out of memory” error
Section titled “Issue: Script crashes with “out of memory” error”Solutions:
- Reduce batch sizes (e.g.,
BATCH_SIZE_IND <- 3) - Set
RUN_DISTRICT_MODEL <- FALSE - Set
RUN_ADMIN_AREA_4_ANALYSIS <- FALSE - Close other applications
- Run on machine with more RAM
Issue: Warning “model failed to converge”
Section titled “Issue: Warning “model failed to converge””Explanation: Robust regression didn’t fully converge within 100 iterations
Impact: Usually minimal - partial convergence often sufficient
Solutions:
- Check data quality for that panel
- Increase
maxitparameter inrlm()call (line 229, 247) - Generally safe to ignore if only a few panels affected
Issue: Many empty rows in output files
Section titled “Issue: Many empty rows in output files”Explanation: Insufficient data for certain indicator-geography combinations
Solutions:
- Expected behavior for sparse indicators
- Filter outputs to non-missing values
- Consider aggregating to higher geographic level
Issue: All recent months flagged as disruptions
Section titled “Issue: All recent months flagged as disruptions”Explanation: Automatic flagging of last 6 months
Purpose: Ensures recent trends reviewed even without strong statistical evidence
Solutions:
- Expected behavior, not a bug
- Review recent months manually
- Adjust
last_6_monthslogic if needed (line 333)
Issue: tagged variable dropped from regression
Section titled “Issue: tagged variable dropped from regression”Message: Variable automatically set to 0
Explanation: No variation in tagged within that panel (all 0 or all 1)
Solutions:
- Expected in panels with no disruptions or constant disruption
- Not an error - disruption effect correctly set to 0
Issue: Temporary files remain after run
Section titled “Issue: Temporary files remain after run”Cause: Script crashed before cleanup
Solutions:
- Delete manually:
M3_temp_*.csv - Or re-run script (automatic cleanup at start)
Issue: Very different results at different geographic levels
Section titled “Issue: Very different results at different geographic levels”Explanation: Different geographic aggregation captures different patterns
Example: National trend may be stable while some districts have large disruptions
Solutions:
- Expected behavior - not a bug
- Use appropriate level for your research question
- Cross-check patterns across levels for robustness
Usage notes
Section titled “Usage notes”Interpretation guidelines
Disruption effects (b_admin_area_*):
- Negative values indicate service volume shortfalls during disrupted periods
- Positive values indicate service volume surpluses during disrupted periods
- Values closer to zero indicate smaller disruption impacts
P-values (p_admin_area_*):
- Values < 0.05 suggest statistically significant disruptions
- Values > 0.05 may indicate normal variation rather than true disruptions
Trend coefficients (b_trend_admin_area_*):
- Positive values indicate increasing service utilization over time
- Negative values indicate declining service utilization over time
- Values near zero indicate stable utilization patterns
Choosing which outputs to review
For quick overviews:
- Start with year-over-year heatmaps to identify areas/indicators with notable changes
- Use control charts for indicators with suspected disruptions
- Focus on high-volume indicators where patterns are more reliable
For subnational analysis:
- Province-level provides reliable patterns with sufficient data volume
- District-level useful for identifying local issues but patterns may be noisier
- Cross-check district patterns against provincial trends for consistency
For time-based analysis:
- Recent periods (last 6 months) may show preliminary patterns that could change
- Look for sustained changes (3+ consecutive months) rather than single-month spikes
- Consider known events (policy changes, campaigns, strikes) when interpreting
Limitations
Statistical limitations:
- Disruption detection works best with 2+ years of historical data
- Low-volume indicators may show high percentage changes from small absolute changes
- Seasonal patterns require at least 12 months of data to model accurately
Interpretation caveats:
- Detected disruptions require contextual investigation (not all are problematic)
- Positive disruptions (surpluses) may reflect campaigns, catch-up, or data issues
- Geographic patterns affected by facility distribution and reporting rates
Data requirements:
- Results depend on quality of completeness and outlier adjustments from earlier modules
- Missing geographic identifiers will reduce coverage of subnational analysis
Quarter-on-quarter change
Section titled “Quarter-on-quarter change”In addition to year-over-year comparisons, FASTR generates quarter-on-quarter (QoQ) change metrics that compare the current quarter to the previous quarter. QoQ change is calculated as: (current quarter – previous quarter) / previous quarter × 100. Changes exceeding ±10% are flagged for follow-up investigation to determine whether they reflect a real programmatic change, a data quality issue, or an expected event (such as a campaign). This metric complements the year-over-year view by capturing more recent shifts in service delivery.